2018年7月13日考试
1.Python读写csv文件
现有如下图1所示的data.csv文件数据,请使用python读取该csv文件数据,并添加一条记录后输出如图2所示的output.csv文件(10分)
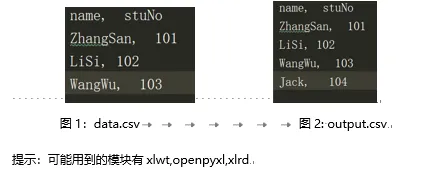
这一题需要用到的csv文件 data.csv下载链接: https://pan.baidu.com/s/1JCUCU4vXBQNwOx2xhAjDqA 密码: pbpx
第1题
import csv
def printCsv(csvName):
with open(csvName) as csvFile:
reader = csv.reader(csvFile)
for i in reader:
print(i)
if __name__ == "__main__":
inCsv = "data.csv"
outCsv = "output.csv"
with open(inCsv) as csvFile:
reader = csv.reader(csvFile)
data = list(reader)
print("原csv文件data.csv的数据内容:")
printCsv(inCsv)
data.append(['Jack','104'])
with open(outCsv,'w',\
newline='') as csvFile:
writer = csv.writer(csvFile)
writer.writerows(data)
print("新产生的csv文件output.csv的数据内容:")
printCsv(outCsv)
上面一段代码的运行结果如下:
原csv文件data.csv的数据内容:
['name', ' stuNo']
['ZhangSan', ' 101']
['LiSi', ' 102']
['WangWu', ' 103']
新产生的csv文件output.csv的数据内容:
['name', ' stuNo']
['ZhangSan', ' 101']
['LiSi', ' 102']
['WangWu', ' 103']
['Jack', '104']
2.Python读写excel文件
如下所示的Excel表格数据,请编写python代码筛选出Points大于5的数据,并按Points进行排序后输出如图2所示的Excel文件结果
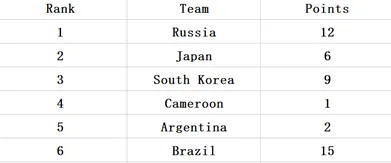
这一题需要用到的excel文件 rank.xlsx下载链接: https://pan.baidu.com/s/1reS7yjxUjU1iqZc0rCjljA 密码: uymy
import xlrd
import xlwt
if __name__ == "__main__":
excel = xlrd.open_workbook("rank.xlsx")
sheet = excel.sheet_by_index(0)
#获取字段列表赋值给field_list,第2个字段大于5的数据列表赋值给data_list
field_list = sheet.row_values(0)
data_list = []
for i in range(1,sheet.nrows):
if int(sheet.row_values(i)[2]) > 5:
data_list.append(sheet.row_values(i))
#利用sorted内置函数排序
data_list = sorted(data_list,key=lambda x:x[2],reverse=True)
#将获得的信息存入新表,命名为output.xlsx
excel_w = xlwt.Workbook()
sheet_w = excel_w.add_sheet("sheet1")
for i in range(len(field_list)):
sheet_w.write(0,i,field_list[i])
for i in range(len(data_list)):
for j in range(len(data_list[i])):
sheet_w.write(i+1,j,data_list[i][j])
excel_w.save("output.xls")
3.mysql数据库的sql语句
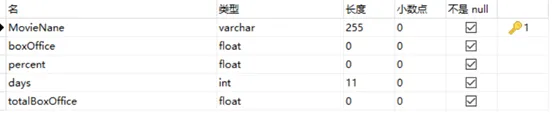
(1) 使用sql创建出如下图所示的数据表,数据库名为movies,表名为movieRank,表中包含MovieName、boxOffice、percent、days、totalBoxOffice五个字段,字段的信息如下图所示:
(2)使用sql语句向movieRank表中添加若干条数据(材料中已提供movieData.txt)
insert into movierank values("21克拉", 1031.92, 15.18, 2, 2827.06);
insert into movierank values("狂暴巨兽", 2928.28, 43.07, 9, 57089.20);
insert into movierank values("起跑线", 161.03, 2.37, 18, 19873.43);
insert into movierank values("头号玩家", 1054.87, 15.52, 23, 127306.41);
insert into movierank values("红海行动", 45.49, 0.67, 65, 364107.74);
插入数据的结果如下图所示:
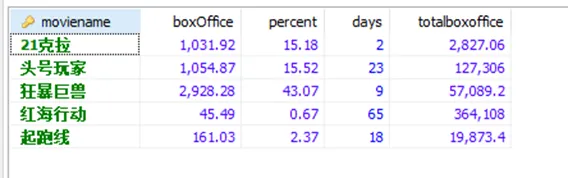
(3)使用sql语句查询movieRank表中的数据并按照totalBoxOffice字段进行排序
select * from movierank order by totalboxoffice;
(4)使用sql语句计算出字段totalBoxOffice字段的总和
select sum(totalboxoffice) from movierank;
4.Python操作mysql数据库
此题接第3题题干,在第三题的基础上完成以下需求:
(1)编写python代码连接mysql数据库,并向movieRank表中新添加两条数据(已提供second.txt)
import pymysql
def getConn(database ="pydb"):
args = dict(
host = 'localhost',
user = 'root',
passwd = 'Leimysql8',
charset = 'utf8',
db = database
)
return pymysql.connect(**args)
if __name__ == "__main__":
conn = getConn("movies")
cursor = conn.cursor()
insert_sql = 'insert into movierank values'\
'("犬之岛", 617.35, 9.08, 2, 1309.09),'\
'("湮灭", 135.34, 1.99, 9 , 5556.77)'
cursor.execute(insert_sql)
conn.commit()
conn.close()
(2)编写python代码,查询出所有的电影数据,并输出到一个Excel表movieRank.xlsx中,如下图所示
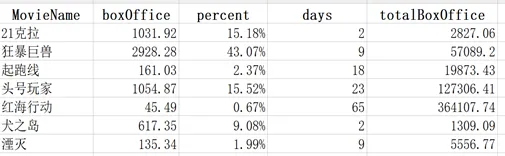
import pymysql
import xlwt
def getConn(database ="pydb"):
args = dict(
host = 'localhost',
user = 'root',
passwd = 'Leimysql8',
charset = 'utf8',
db = database
)
return pymysql.connect(**args)
if __name__ == "__main__":
#从mysql数据库中取出数据赋值给data_list,其数据类型为元组
conn = getConn("movies")
cursor = conn.cursor()
select_sql = "select * from movierank "
cursor.execute(select_sql)
data_list = cursor.fetchall()
field_list = [k[0] for k in cursor.description]
#把data_list中的数据存入新的excel中,并命名为movieRank.xls
excel = xlwt.Workbook()
sheet = excel.add_sheet("sheet1")
for i in range(len(field_list)):
sheet.write(0,i,field_list[i])
for i in range(len(data_list)):
for j in range(len(data_list[i])):
sheet.write(i+1,j,data_list[i][j])
excel.save("movieRank.xls")
5.Python操作MongoDB数据库
(1)编写python代码连接MongoDB数据库,并新建一个building库,在building库下新建一个rooms表
from pymongo import MongoClient
if __name__ == "__main__":
conn = MongoClient("localhost")
db = conn.building
rooms = db.create_collection("rooms")
(2)编写python代码读取rooms.csv文件的中的数据,并将数据插入到rooms表中,添加到rooms表中的数据结构如下图所示
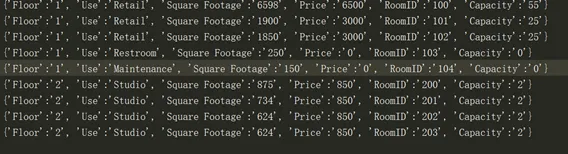
这一题需要用到的csv文件rooms.csv下载链接: https://pan.baidu.com/s/10fyct-J3a0txtS-EZaaxAQ 密码: je33
from pymongo import MongoClient
import csv
if __name__ == "__main__":
with open("rooms.csv") as csvFile:
reader = list(csv.reader(csvFile))
field_list = reader[0]
data_list = reader[1:]
conn = MongoClient("localhost")
db = conn.building
rooms = db.rooms
insert_list = []
for data in data_list:
insert_list.append(
{key:value for key,value in zip(field_list,data)})
rooms.insert_many(insert_list)
使用csv.DictReader方法
from pymongo import MongoClient
import csv
if __name__ == "__main__":
conn = MongoClient("localhost")
db = conn.building
rooms = db.rooms
with open("rooms.csv") as csvFile:
reader = csv.DictReader(csvFile)
for row in reader:
rooms.insert_one(dict(row))
