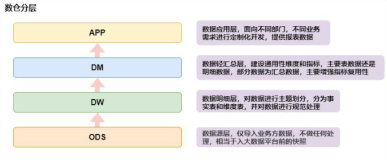
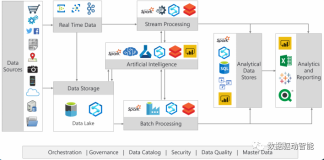
一个典型的企业数据仓库通常包含数据采集、数据加工和存储、数据展现等几个过程,本篇文章将按照这个顺序记录部门当前建设数据仓库的过程。
1. 数据采集和存储
采集数据之前,先要定义数据如何存放在 hadoop 以及一些相关约束。约束如下:
- 所有的日志数据都存放在 hdfs 上的
/logroot路径下面 - hive 中数据库命名方式为
dw_XXXX,例如:dw_srclog 存放外部来源的原始数据,dw_stat 存放统计结果的数据 - 原始数据都加工成为结构化的文本文件,字段分隔符统一使用制表符,并在 lzo 压缩之后上传到 hdfs 中。
- hive 中使用外部表保存数据,数据存放在
/logroot下,如果不是分区表,则文件名为表名;如果是分区表,则按月和天分区,每天分区下的文件名为表名_日期,例如:test_20141023
数据采集的来源可能是关系数据库或者一些系统日志,采集工具可以是日志采集系统,例如:flume、sqoop 、storm以及一些 ETL 工具等等。
目前,主要是从 mysql 中导出数据然后在导入到 hdfs 中,对于存储不需要按天分区的表,这部分过程代码如下:
#!/bin/bash
if [ "$1" ]; then
DAY="$1"
else
DAY="yesterday"
fi
datestr=`date +%Y-%m-%d -d"$DAY"`;
logday=`date +%Y%m%d -d"$DAY"`;
logmonth=`date +%Y%m -d"$DAY"`
#hive table
table=test
#mysql db config file
srcdb=db_name
sql="select * from test"
hql="
use dw_srclog;
create external table if not exists test (
id int,
name int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/logroot/test';
"
#begin
chmod +x $srcdb.sql
. ./$srcdb.sql
file="${table}"
sql_var=" -r -quick --default-character-set=utf8 --skip-column"
mysql $sql_var -h${db_host} -u${db_user} -p${db_pass} -P${db_port} -D${db_name} -e "$sql" | sed "s/NULL/\\\\N/g"> $file 2>&1
lzop -U $file
hadoop fs -mkdir -p /logroot/$table
hadoop fs -ls /logroot/$table |grep lzo|awk '{print $8}'|xargs -i hadoop fs -rm {}
hadoop fs -moveFromLocal $file.lzo /logroot/$table/
hadoop jar /usr/lib/hadoop/lib/hadoop-lzo.jar com.hadoop.compression.lzo.LzoIndexer /logroot/$table/$file.lzo 2>&1
echo "create table if not exists"
hive -v -e "$hql;" 2>&1
上面 bash 代码逻辑如下:
- 1、判断是否输入参数,如果没有参数,则取昨天,意思是每天读取 mysql 数据库中昨天的数据。
- 2、定义 mysql 中 select 查询语句
- 3、定义 hive 中建表语句
- 4、读取 mysql 数据库连接信息,上例中为从 db_name.sql 中读取
db_host、db_user、db_pass、db_port、db_name五个变量 - 5、运行 mysql 命令导出指定 sql 查询的结果,并将结果中的 NULL 字段转换为
\\N,因为\在 bash 中是转义字符,故需要使用两个\ - 6、lzo 压缩文件并上传到 hdfs,并且创建 lzo 索引
- 7、最后删除本地文件
对于分区表来说,建表语句如下:
use dw_srclog;
create external table if not exists test_p (
id int,
name int
)
partitioned by (key_ym int, key_ymd int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/logroot/test_p';
从 mysql 导出文件并上传到 hdfs 命令如下:
#begin
chmod +x $srcdb.sql
. ./$srcdb.sql
file="${table}_$logday"
sql_var=" -r -quick --default-character-set=utf8 --skip-column"
mysql $sql_var -h${db_host} -u${db_user} -p${db_pass} -P${db_port} -D${db_name} -e "$sql" | sed "s/NULL/\\\\N/g"> $file 2>&1
lzop -U $file
hadoop fs -mkdir -p /logroot/$table/key_ym=$logmonth/key_ymd=$logday
hadoop fs -ls /logroot/$table/key_ym=$logmonth/key_ymd=$logday/ |grep lzo|awk '{print $8}'|xargs -i hadoop fs -rm {} 2>&1
hadoop fs -moveFromLocal $file.lzo /logroot/$table/key_ym=$logmonth/key_ymd=$logday/
hadoop jar /usr/lib/hadoop/lib/hadoop-lzo.jar com.hadoop.compression.lzo.LzoIndexer /logroot/$table/key_ym=$logmonth/key_ymd=$logday/$file.lzo 2>&1
hive -v -e "$hql;ALTER TABLE $table ADD IF NOT EXISTS PARTITION(key_ym=$logmonth,key_ymd=$logday) location '/logroot/$table/key_ym=$logmonth/key_ymd=$logday' " 2>&1
通过上面的两个命令就可以实现将 mysql 中的数据导入到 hdfs 中。
这里需要注意以下几点:
- 1、 hive 中原始日志使用默认的 textfile 方式存储,是为了保证日志的可读性,方便以后从 hdfs 下载来之后能够很方便的转换为结构化的文本文件并能浏览文件内容。
- 2、使用 lzo 压缩是为了节省存储空间
- 3、使用外包表建表,在删除表结构之后数据不会删,方便修改表结构和分区。
使用 Sqoop
使用 sqoop 主要是用于从 oracle 中通过 jdbc 方式导出数据到 hdfs,sqoop 命令如下:
sqoop import --connect jdbc:oracle:thin:@192.168.56.121:2154:db --username bi_user_limit --password 'XXXX' --query "select * from test where \$CONDITIONS" --split-by id -m 5 --fields-terminated-by '\t' --lines-terminated-by '\n' --null-string '\\N' --null-non-string '\\N' --target-dir "/logroot/test/key_ymd=20140315" --delete-target-dir
2. 数据加工
对于数据量比较小任务可以使用 impala 处理,对于数据量大的任务使用 hive hql 来处理。
impala 处理数据:
impala-shell -i '192.168.56.121:21000' -r -q "$sql;"
有时候需要使用 impala 导出数据:
impala-shell -i '192.168.56.121:21000' -r -q "$sql;" -B --output_delimiter="\t" -o $file
sed -i '1d' $file #导出的第一行有不可见的字符
使用 hive 处理数据生成结果表:
#!/bin/bash
if [ "$1" ]; then
DAY="$1"
else
DAY="yesterday"
fi
echo "DAY=$DAY"
datestr=`date +%Y-%m-%d -d"$DAY"`;
logday=`date +%Y%m%d -d"$DAY"`;
logmonth=`date +%Y%m -d"$DAY"`
#target table
table=stat_test_p
sql="use dw_srclog;insert OVERWRITE table stat_test_p partition(key_ym=$logmonth,key_ymd=$logday)
select id,count(name) from test_p where key_ymd=$logday group by id
"
hql="
use dw_web;
create external table if not exists goods_sales_info_day (
id int,
count int
) partitioned by (key_ym int, key_ymd int)
STORED AS RCFILE
LOCATION '/logroot/stat_test_p';
"
#begin
hive -v -e "
$hql;
SET hive.exec.compress.output=true;
SET mapreduce.input.fileinputformat.split.maxsize=128000000;
SET mapred.output.compression.type=BLOCK;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
$sql" 2>&1
这里主要是先判断是否创建外包表(外包表存储为 RCFILE 格式),然后设置 map 的输出结果使用 snappy 压缩,并设置每个 map 的大小,最后运行 insert 语句。结果表存储为 RCFILE 的原因是,在 CDH 5.2 之前,该格式的表可以被 impala 读取。
任务调度
当任务多了之后,每个任务之间会有一些依赖,为了保证任务的先后执行顺序,这里使用的是 azkaban 任务调度框架。
该框架的使用方式很简单:
- 首先创建一个 bi_etl 目录,用于存放执行脚本。
- 在 bi_etl 目录下创建一个 properties 文件,文件名称任意,文件内容为:
DAY=yesterday,这是一个系统默认参数,即默认 DAY 变量的值为 yesterday,该变量在运行时可以被覆盖:在 azkaban 的 web 管理界面,运行一个 Flow 时,添加一个Flow Parameters参数,Name 为 DAY,Value 为你想要指定的值,例如:20141023。 - 创建一个 bash 脚本 test.sh,文件内容如第一章节内容,需要注意的是该脚本中会判断是否有输出参数。
- 针对 bash 脚本,创建 azkaban 需要的 job 文件,文件内容如下(azkaban 运行该 job 时候,会替换
${DAY}变量为实际的值 ):
type=command
command=sh test.sh ${DAY}
failure.emails=XXX@163.com
dependencies=xxx
- 最后,将 bi_etl 目录打包成 zip 文件,然后上传到 azkaban 管理界面上去,就可以运行或者是设置调度任务了。
使用上面的方式编写 bash 脚本和 azkaban 的 job 的好处是:
- azkaban 的 job 可以指定参数来控制运行哪一天的任务
- job 中实际上运行的是 bash 脚本,这些脚本脱离了 azkaban 也能正常运行,同样也支持传参数。
3. 数据展现
目前是将 hive 或者 impala 的处理结果推送到关系数据库中,由传统的 BI 报表工具展示数据或者直接通过 impala 查询数据生成报表并发送邮件。
为了保证报表的正常发送,需要监控任务的正常运行,当任务失败的时候能够发送邮件,这部分通过 azkaban 可以做到。另外,还需要监控每天运行的任务同步的记录数,下面脚本是统计记录数为0的任务:
#!/bin/bash
if [ "$1" ]; then
DAY="$1"
else
DAY="yesterday"
fi
echo "DAY=$DAY"
datestr=`date +%Y-%m-%d -d"$DAY"`;
logday=`date +%Y%m%d -d"$DAY"`;
logmonth=`date +%Y%m -d"$DAY"`
datemod=`date +%w -d "yesterday"`
rm -rf /tmp/stat_table_day_count_$logday
touch /tmp/stat_table_day_count_$logday
for db in `hadoop fs -ls /user/hive/warehouse|grep -vE 'testdb|dw_etl'|grep '.db'|awk '{print $8}'|awk -F '/' '{print $5}' |awk -F '.' '{print $1}'`;do
for table in `hive -S -e "set hive.cli.print.header=false; use $db;show tables" ` ;do
count_new=""
result=`hive -S -e "set hive.cli.print.header=false; use $db;show create table $table;" 2>&1 | grep PARTITIONED`
if [ ${#result} -gt 0 ];then
is_part=1
count_new=`impala-shell -k -i 10.168.35.127:21089 --quiet -B --output_delimiter="\t" -q "select count(1) from ${db}.$table where key_ymd=$logday "`
else
is_part=0
count_new=`impala-shell -k -i 10.168.35.127:21089 --quiet -B --output_delimiter="\t" -q "select count(1) from ${db}.$table; "`
fi
echo "$db,$table,$is_part,$count_new" >> /tmp/stat_table_day_count_$logday
done
done
#mail -s "The count of the table between old and new cluster in $datestr" -c $mails < /tmp/stat_table_day_count_$logday
sed -i 's/1034h//g' /tmp/stat_table_day_count_$logday
sed -i 's/\[//g' /tmp/stat_table_day_count_$logday
sed -i 's/\?//g' /tmp/stat_table_day_count_$logday
sed -i 's/\x1B//g' /tmp/stat_table_day_count_$logday
res=`cat /tmp/stat_table_day_count_$logday|grep -E '1,0|0,0'|grep -v stat_table_day_count`
echo $res
hive -e "use dw_default;
LOAD DATA LOCAL INPATH '/tmp/stat_table_day_count_$logday' overwrite INTO TABLE stat_table_day_count PARTITION (key_ym=$logmonth,key_ymd=$logday)
"
python mail.py "Count is 0 in $datestr" "$res"
4. 总结
上面介绍了数据采集、加工和任务调度的过程,有些地方还可以改进:
- 引入 ETL 工具实现关系数据库导入到 hadoop,例如:Kettle 工具
- 目前是每天一次从 mysql 同步数据到 hadoop,以后需要修改同步频率,做到更实时
- hive 和 impala 在字段类型、存储方式、函数的兼容性上存在一些问题