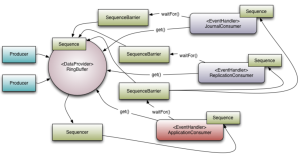
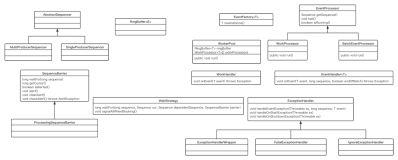
翻译自Disruptor git库教程 英文地址
获得Disruptor
可以通过Maven或者下载jar来安装Disruptor。只要把对应的jar放在Java classpath就可以了。
基本的事件生产和消费
我们从一个简单的例子开始学习Disruptor:生产者传递一个long类型的值给消费者,而消费者消费这个数据的方式仅仅是把它打印出来。首先声明一个Event来包含需要传递的数据:
public class LongEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
由于需要让Disruptor为我们创建事件,我们同时还声明了一个EventFactory来实例化Event对象。
public class LongEventFactory implements EventFactory {
@Override
public Object newInstance() {
return new LongEvent();
}
} 我们还需要一个事件消费者,也就是一个事件处理器。这个事件处理器简单地把事件中存储的数据打印到终端:
/**
*/public class LongEventHandler implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent longEvent, long l, boolean b) throws Exception {
System.out.println(longEvent.getValue());
}
} 事件都会有一个生成事件的源,这个例子中假设事件是由于磁盘IO或者network读取数据的时候触发的,事件源使用一个ByteBuffer来模拟它接受到的数据,也就是说,事件源会在IO读取到一部分数据的时候触发事件(触发事件不是自动的,程序员需要在读取到数据的时候自己触发事件并发布):
public class LongEventProducer {
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
/**
* onData用来发布事件,每调用一次就发布一次事件事件
* 它的参数会通过事件传递给消费者
*
* @param bb
*/public void onData(ByteBuffer bb) {
//可以把ringBuffer看做一个事件队列,那么next就是得到下面一个事件槽
long sequence = ringBuffer.next();try {
//用上面的索引取出一个空的事件用于填充
LongEvent event = ringBuffer.get(sequence);// for the sequence
event.setValue(bb.getLong(0));
} finally {
//发布事件
ringBuffer.publish(sequence);
}
}
} 很明显的是:当用一个简单队列来发布事件的时候会牵涉更多的细节,这是因为事件对象还需要预先创建。发布事件最少需要两步:获取下一个事件槽并发布事件(发布事件的时候要使用try/finnally保证事件一定会被发布)。如果我们使用RingBuffer.next()获取一个事件槽,那么一定要发布对应的事件。如果不能发布事件,那么就会引起Disruptor状态的混乱。尤其是在多个事件生产者的情况下会导致事件消费者失速,从而不得不重启应用才能会恢复。
Disruptor 3.0提供了lambda式的API。这样可以把一些复杂的操作放在Ring Buffer,所以在Disruptor3.0以后的版本最好使用Event Publisher或者Event Translator来发布事件。
public class LongEventProducerWithTranslator {
//一个translator可以看做一个事件初始化器,publicEvent方法会调用它
//填充Event
private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR =
new EventTranslatorOneArg<LongEvent, ByteBuffer>() {
public void translateTo(LongEvent event, long sequence, ByteBuffer bb) {
event.setValue(bb.getLong(0));
}
};
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer bb) {
ringBuffer.publishEvent(TRANSLATOR, bb);
}
} 上面写法的另一个好处是,Translator可以分离出来并且更加容易单元测试。Disruptor提供了不同的接口(EventTranslator, EventTranslatorOneArg, EventTranslatorTwoArg, 等等)去产生一个Translator对象。很明显,Translator中方法的参数是通过RingBuffer来传递的。
最后一步就是把所有的代码组合起来完成一个完整的事件处理系统。Disruptor在这方面做了简化,使用了DSL风格的代码(其实就是按照直观的写法,不太能算得上真正的DSL)。虽然DSL的写法比较简单,但是并没有提供所有的选项。如果依靠DSL已经可以处理大部分情况了。
public class LongEventMain {
public static void main(String[] args) throws InterruptedException {
// Executor that will be used to construct new threads for consumers
Executor executor = Executors.newCachedThreadPool();
// The factory for the event
LongEventFactory factory = new LongEventFactory();
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;
// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory, bufferSize, executor);
// Connect the handler
disruptor.handleEventsWith(new LongEventHandler());
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++) {
bb.putLong(0, l);
producer.onData(bb);
Thread.sleep(1000);
}
}
} 使用Java 8
Disruptor在自己的接口里面添加了对于Java 8 Lambda的支持。大部分Disruptor中的接口都符合Functional Interface的要求(也就是在接口中仅仅有一个方法)。所以在Disruptor中,可以广泛使用Lambda来代替自定义类。
public class LongEventMainJava8 {
/**
* 用lambda表达式来注册EventHandler和EventProductor
* @param args
* @throws InterruptedException
*/public static void main(String[] args) throws InterruptedException {
// Executor that will be used to construct new threads for consumers
Executor executor = Executors.newCachedThreadPool();
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, executor);
// 可以使用lambda来注册一个EventHandler
disruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event.getValue()));
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);for (long l = 0; true; l++) {
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.setValue(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
} 在上面的代码中,有很多自定义类型可以被省略了。还有注意的是:publishEvent方法中仅调用传递给它的参数,并不是直接调用对应的对象。如果把这段代码换成下面的代码:
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence) -> event.set(bb.getLong(0)));
Thread.sleep(1000);
}这段代码中有一个捕获参数的lambda,意味着在lambda表达式生成的内部类中会生成一个对象来存储这个捕获的bb对象。这会增加不必要的GC。所以在需要较低GC水平的情况下最好把所有的参数都通过publishEvent传递。
由于在Java 8中方法引用也是一个lambda,因此还可以把上面的代码改成下面的代码:
public class LongEventWithMethodRef {
public static void handleEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println(event.getValue());
}
public static void translate(LongEvent event, long sequence, ByteBuffer buffer)
{
event.setValue(buffer.getLong(0));
}
public static void main(String[] args) throws Exception
{
// Executor that will be used to construct new threads for consumers
Executor executor = Executors.newCachedThreadPool();
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;
// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, executor);
// Connect the handler
disruptor.handleEventsWith(LongEventWithMethodRef::handleEvent);
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent(LongEventWithMethodRef::translate, bb);
Thread.sleep(1000);
}
}
}
基本调整选项
上面的代码已经可以处理大多数的情况了,但是在有的时候还是会需要根据不同的软件或者硬件来调整选项以获得更高的性能。基本的选项有两个:单或者多生产者模式和可选的等待策略。
单或多 事件生产者
在并发系统中提高性能最好的方式之一就是单一写者原则,对Disruptor也是适用的。如果在你的代码中仅仅有一个事件生产者,那么可以设置为单一生产者模式来提高系统的性能。
public class singleProductorLongEventMain {
public static void main(String[] args) throws Exception {
//.....// Construct the Disruptor with a SingleProducerSequencer
Disruptor<LongEvent> disruptor = new Disruptor(factory,
bufferSize,
ProducerType.SINGLE, // Single producernew BlockingWaitStrategy(),
executor);//.....
}
} 为了证明,下面的数据是从Mac Air i7上面测试的结果:
多生产者:
Run 0, Disruptor=26,553,372 ops/sec
Run 1, Disruptor=28,727,377 ops/sec
Run 2, Disruptor=29,806,259 ops/sec
Run 3, Disruptor=29,717,682 ops/sec
Run 4, Disruptor=28,818,443 ops/sec
Run 5, Disruptor=29,103,608 ops/sec
Run 6, Disruptor=29,239,766 ops/sec单生产者:
Run 0, Disruptor=89,365,504 ops/sec
Run 1, Disruptor=77,579,519 ops/sec
Run 2, Disruptor=78,678,206 ops/sec
Run 3, Disruptor=80,840,743 ops/sec
Run 4, Disruptor=81,037,277 ops/sec
Run 5, Disruptor=81,168,831 ops/sec
Run 6, Disruptor=81,699,346 ops/sec
可选的等待策略
Disruptor默认的等待策略是BlockingWaitStrategy。这个策略的内部适用一个锁和条件变量来控制线程的执行和等待(Java基本的同步方法)。BlockingWaitStrategy是最慢的等待策略,但也是CPU使用率最低和最稳定的选项。然而,可以根据不同的部署环境调整选项以提高性能。
SleepingWaitStrategy
和BlockingWaitStrategy一样,SpleepingWaitStrategy的CPU使用率也比较低。它的方式是循环等待并且在循环中间调用LockSupport.parkNanos(1)来睡眠,(在Linux系统上面睡眠时间60µs).然而,它的优点在于生产线程只需要计数,而不执行任何指令。并且没有条件变量的消耗。但是,事件对象从生产者到消费者传递的延迟变大了。SleepingWaitStrategy最好用在不需要低延迟,而且事件发布对于生产者的影响比较小的情况下。比如异步日志功能。
YieldingWaitStrategy
YieldingWaitStrategy是可以被用在低延迟系统中的两个策略之一,这种策略在减低系统延迟的同时也会增加CPU运算量。YieldingWaitStrategy策略会循环等待sequence增加到合适的值。循环中调用Thread.yield()允许其他准备好的线程执行。如果需要高性能而且事件消费者线程比逻辑内核少的时候,推荐使用YieldingWaitStrategy策略。例如:在开启超线程的时候。
BusySpinWaitStrategy
BusySpinWaitStrategy是性能最高的等待策略,同时也是对部署环境要求最高的策略。这个性能最好用在事件处理线程比物理内核数目还要小的时候。例如:在禁用超线程技术的时候。