在 AI 智能体开发中,开发者常陷入 “两难困境”:本地调试需要快速迭代,但依赖冲突、算力不足让流程卡顿;云端有充足 GPU 资源,却需重新配置环境、改写部署脚本。
而 Docker Compose 与 Docker Offload 的组合,恰好打破了这一壁垒 —— 通过一份配置文件,既能在本地实现多服务协同运行,又能无缝迁移到云端 GPU 节点,让 AI 智能体的 “开发 - 测试 - 扩容” 全流程更高效、更一致。本文将结合实战案例,拆解如何用这一方案构建包含语言模型(LLM)、数据库、前端的完整 AI 智能体,并实现从本地笔记本到云端的平滑过渡。
一、为何 AI 智能体需要 Docker?破解多服务协同难题
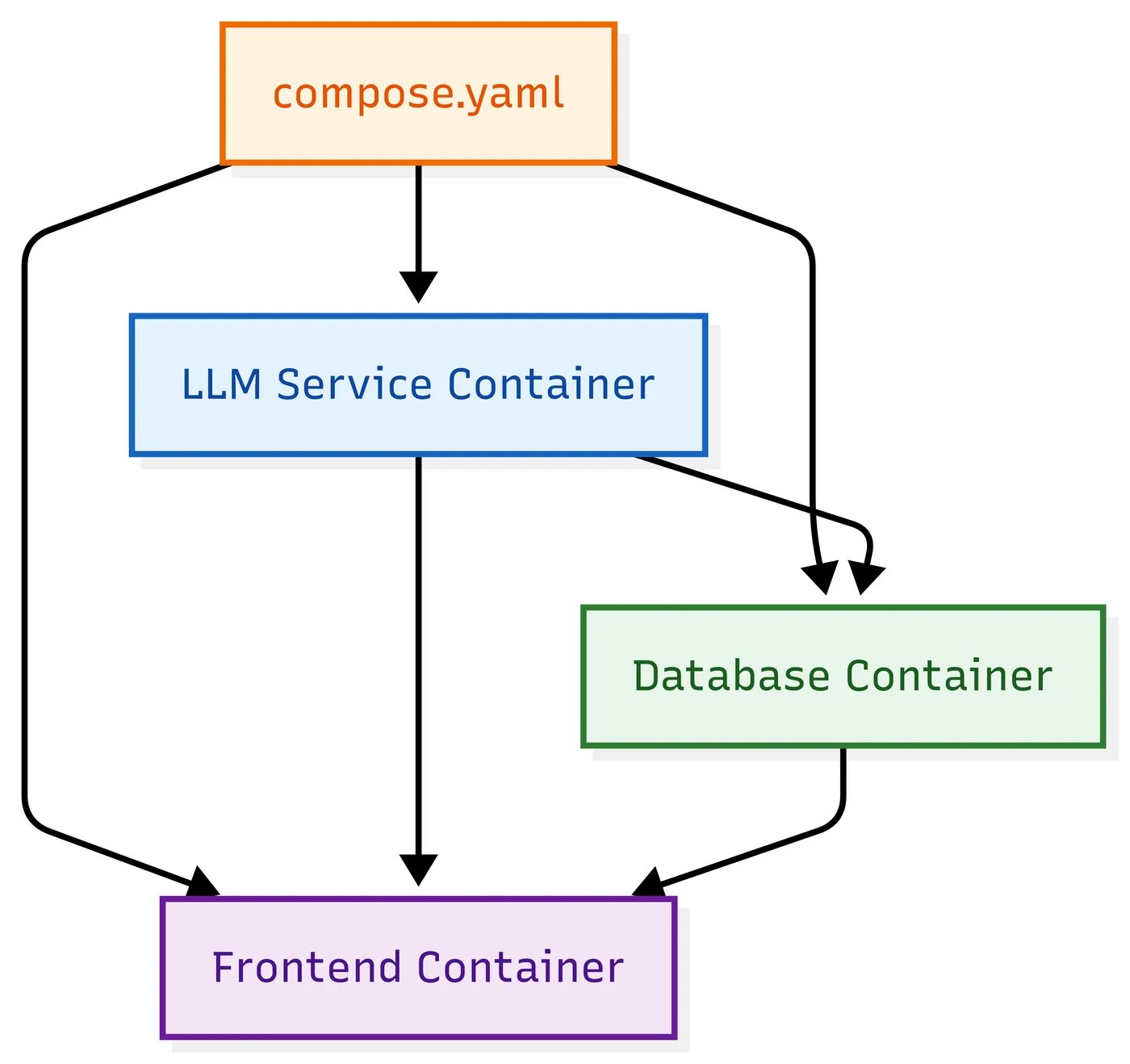
AI 智能体并非单一程序,而是由 “LLM 服务 + 存储服务 + 交互界面” 等多个组件构成的复合系统。例如,一个科研助手智能体可能需要:
- 语言模型(如 DistilGPT-2、LLaMA-2)处理自然语言请求;
- 向量数据库(如 Weaviate、Chroma)存储长文本嵌入与历史对话;
- 前端界面(如 React、Vue)供用户输入查询与查看结果;
- 监控服务跟踪请求响应时间与模型运行状态。
传统开发模式下,这些组件需手动安装配置:本地部署 Postgres 数据库、用 Python 启动 LLM 服务、用 Node.js 运行前端,不仅要处理版本冲突(如 Python 依赖库与 Node 环境的兼容性),还需手动管理端口映射(避免服务端口占用)。一旦某个组件故障(如数据库崩溃),整个智能体系统都会瘫痪。
Docker Compose 的出现彻底改变了这一现状。它通过单份 YAML 配置文件定义所有服务,自动完成容器创建、网络连接、资源分配,实现 “一份配置,多环境复用”。例如,只需执行docker compose up,就能一键启动 LLM、数据库、前端三个服务,且各服务运行在独立容器中,互不干扰。这种方式不仅解决了 “环境一致性” 问题,还让团队协作更高效 —— 无论开发者使用 Windows、macOS 还是 Linux,只要有 Docker 和 Compose 配置,就能运行完全相同的智能体栈。
二、用 Docker Compose 定义 AI 智能体:从基础到进阶配置
构建 AI 智能体的第一步,是通过compose.yaml文件明确各服务的依赖、资源需求与运行规则。根据需求复杂度,配置可分为 “基础版” 与 “进阶版”,兼顾快速调试与生产级稳定性。
2.1 基础配置:快速搭建智能体核心服务
基础版配置聚焦 “最小可用”,包含 LLM、数据库、前端三个核心组件,适合本地调试与功能验证。以下是典型配置示例:
# compose.yaml(基础版) services: # 1. LLM服务:使用LangGraph镜像,提供语言模型能力 llm: image: ghcr.io/langchain/langgraph:latest # 成熟LLM服务镜像,支持常见模型调用 ports: - "8080:8080" # 本地端口8080映射到容器8080,供前端调用 environment: - MODEL_NAME=distilgpt2 # 指定轻量模型,适合CPU运行(本地调试用) - MAX_TOKENS=512 # 限制生成文本长度,避免资源过载 # 2. 数据库服务:Postgres存储对话历史与元数据 db: image: postgres:15 # 固定Postgres版本,避免版本兼容问题 environment: - POSTGRES_PASSWORD=${POSTGRES_PASSWORD} # 从.env文件读取密码,避免硬编码 - POSTGRES_DB=agent_db # 数据库名称,统一管理智能体数据 volumes: - postgres_data:/var/lib/postgresql/data # 挂载数据卷,本地调试时保留数据 # 3. 前端服务:自定义React界面,供用户交互 ui: build: ./frontend # 从本地./frontend目录构建前端镜像 ports: - "3000:3000" # 前端访问端口,本地浏览器打开http://localhost:3000即可使用 depends_on: - llm # 确保LLM服务启动后再启动前端,避免请求失败 # 定义数据卷,持久化存储数据库数据 volumes: postgres_data:
关键说明:
- LLM 服务选型:基础配置使用
distilgpt2等轻量模型,可在 CPU 上运行(本地笔记本无需 GPU),适合快速验证对话逻辑; - 环境变量管理:数据库密码通过
.env文件传入(需在项目根目录创建.env,写入POSTGRES_PASSWORD=your_secret),避免敏感信息泄露; - 依赖控制:通过
depends_on确保服务启动顺序,防止前端因 LLM 未就绪而调用失败。
执行docker compose up后,通过docker compose ps可查看服务状态,确认三个容器均正常运行后,访问http://localhost:3000即可与智能体交互。
2.2 进阶配置:适配生产级需求(含 GPU 支持)
当需要测试更大模型(如 LLaMA-2-13B)或提升系统稳定性时,需升级为进阶配置,增加GPU 资源声明、健康检查、多阶段构建等特性,为后续云端迁移做准备:
# compose.yaml(进阶版) services: llm: # 自定义构建LLM服务,支持更大模型与GPU加速 build: context: ./llm-service # 本地LLM服务代码目录(含自定义模型逻辑) dockerfile: Dockerfile # 多阶段构建脚本,减少镜像体积 ports: - "8080:8080" environment: - MODEL_NAME=llama-2-13b # 切换到需要GPU的大模型 - CUDA_VISIBLE_DEVICES=0 # 指定使用第1块GPU(云端多GPU场景) # 声明GPU资源需求(本地有GPU可启用,云端Offload时自动匹配) deploy: resources: reservations: devices: - driver: nvidia # 支持NVIDIA GPU(主流AI模型依赖) count: 1 # 所需GPU数量 capabilities: [gpu] # 健康检查:确保LLM服务就绪后再接收请求 healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8080/health"] # 调用/health接口检测 interval: 30s # 每30秒检查一次 retries: 3 # 失败3次后标记服务异常 timeout: 10s # 超时时间10秒 db: image: postgres:15 environment: - POSTGRES_PASSWORD=${POSTGRES_PASSWORD} - POSTGRES_DB=agent_db volumes: - postgres_data:/var/lib/postgresql/data # 数据库健康检查:确保连接可用 healthcheck: test: ["CMD-SHELL", "pg_isready -U postgres"] interval: 10s retries: 5 ui: build: context: ./frontend dockerfile: Dockerfile # 前端多阶段构建:构建阶段用Node,运行阶段用Nginx ports: - "3000:80" # 前端静态文件用Nginx托管,端口映射调整为80 depends_on: llm: condition: service_healthy # 仅当LLM服务健康时才启动前端 db: condition: service_healthy # 确保数据库就绪 volumes: postgres_data:
进阶特性价值:
- GPU 资源声明:通过
deploy.resources指定 NVIDIA GPU 需求,本地有 GPU 时可直接启用,后续迁移到云端时无需修改配置; - 健康检查:避免 “服务已启动但未就绪” 的问题(如 LLM 模型加载需 10 分钟,健康检查会等待其就绪后再开放访问);
- 多阶段构建:以前端为例,构建阶段用 Node 编译 React 代码,运行阶段用轻量 Nginx 托管静态文件,镜像体积可从 GB 级压缩到 MB 级,加快云端传输速度。
三、从本地到云端:用 Docker Offload 实现无缝扩容
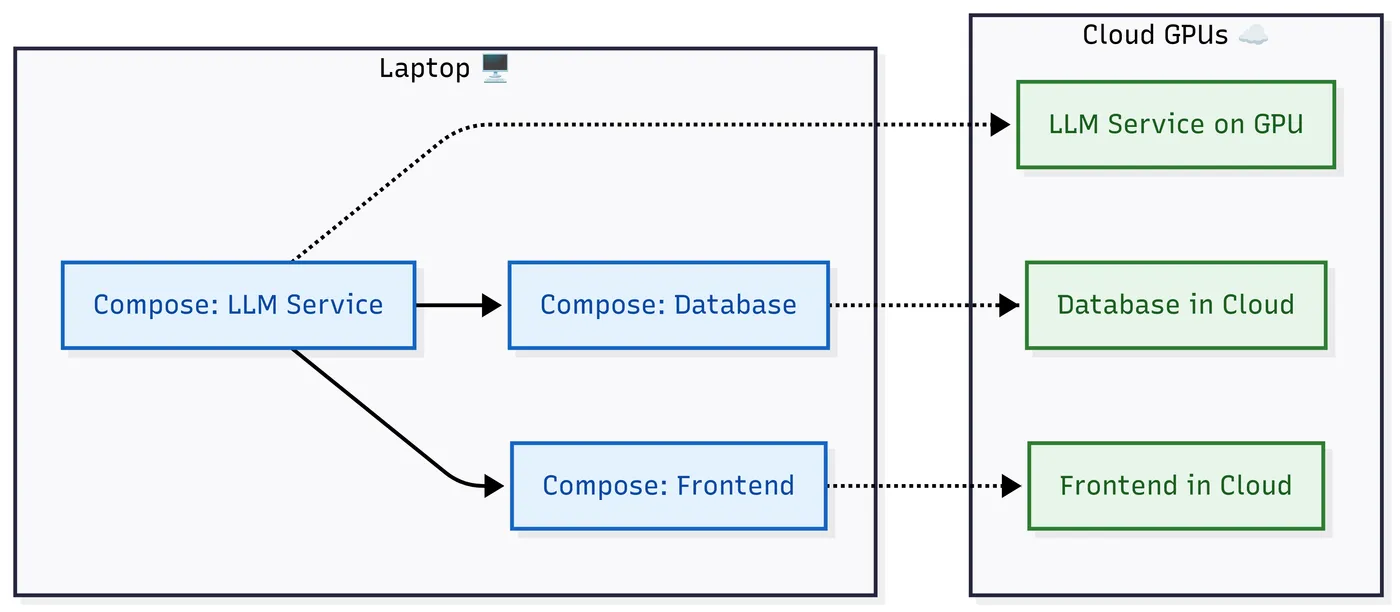
本地环境虽适合调试,但面对 LLaMA-2-13B、Falcon 等大模型时,CPU 算力不足会导致响应延迟高达数十秒,甚至触发内存溢出。Docker Offload 作为 Docker 的扩展工具,可将本地compose.yaml配置直接迁移到云端 GPU 节点,无需修改任何服务定义,实现 “一键扩容”。
3.1 Docker Offload 核心原理
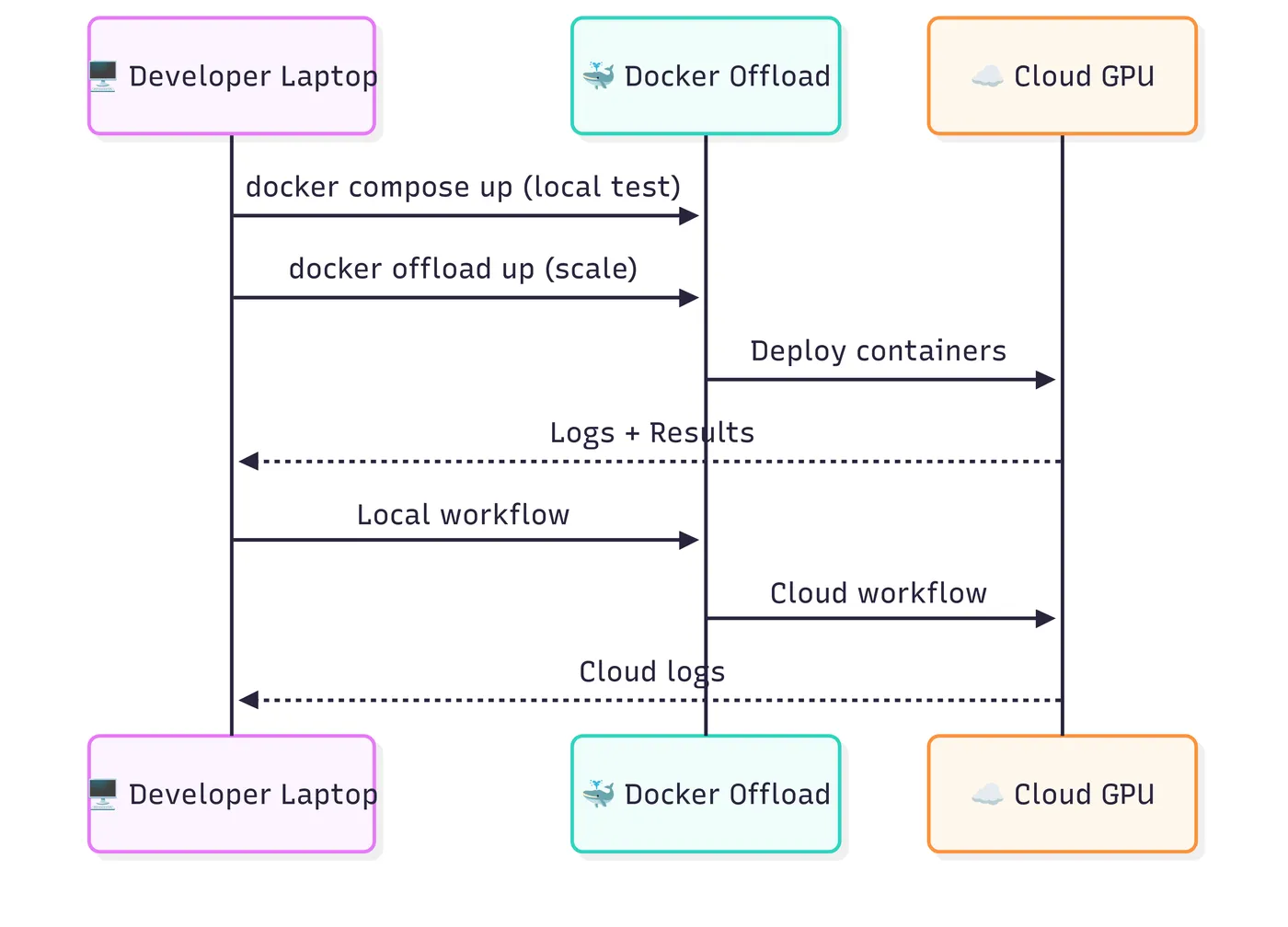
Docker Offload 的核心价值是 “配置复用, runtime 迁移”:它读取本地compose.yaml文件,识别需要 GPU 资源的服务(如 LLM 服务),自动在云端匹配 GPU-backed 主机,将这些服务部署到云端运行;而数据库、前端等轻量服务可选择保留在本地,或随 LLM 一起迁移。整个过程中,开发者仍通过本地终端查看日志、调试服务,体验与本地运行完全一致。
3.2 云端迁移实战步骤
步骤 1:安装 Docker Offload 扩展
首先确保本地已安装 Docker Desktop,然后通过命令行安装 Offload 扩展:
# 安装Docker Offload扩展 docker extension install offload
安装完成后,可通过docker extension list确认扩展已启用。
步骤 2:一键部署到云端 GPU 节点
无需修改compose.yaml,直接执行以下命令,Offload 会自动处理云端资源匹配与服务部署:
# 将智能体栈迁移到云端GPU docker offload up
Offload 的核心优势在此体现:
- 自动 GPU 匹配:根据
compose.yaml中声明的 GPU 需求(如count:1),在云端筛选可用的 NVIDIA GPU 节点(如 AWS P3、GCP A2 实例); - 网络打通:云端 LLM 服务的端口会通过加密隧道映射到本地,前端仍可通过
http://localhost:8080调用,无需修改请求地址; - 日志同步:云端服务的日志实时流式传输到本地终端,开发者用
docker offload logs llm即可查看 LLM 服务运行状态,调试体验与本地一致。
步骤 3:验证云端部署状态
通过以下命令查看云端服务运行情况:
# 查看云端服务列表 docker offload ps # 查看LLM服务日志(确认模型加载成功) docker offload logs llm # 检查云端部署健康状态 docker offload status
若输出显示llm服务状态为 “Running”,且日志中出现 “Model loaded successfully”,说明云端 GPU 已成功运行大模型,此时访问http://localhost:3000,智能体响应速度会比本地 CPU 版本提升 10-50 倍(取决于模型大小与 GPU 规格)。
步骤 4:云端资源回收
测试或使用完成后,及时停止云端服务,避免不必要的 GPU 费用消耗:
# 停止云端所有服务 docker offload stop # 彻底删除云端部署(可选,释放所有资源) docker offload down
四、实战案例:科研助手智能体的 “本地调试 - 云端扩容” 全流程
以 “科研助手智能体” 为例,完整演示如何用 Docker Compose+Offload 实现从本地验证到云端扩容的闭环。该智能体需实现 “论文摘要生成”“文献检索” 功能,核心依赖 LLM 模型与向量数据库。
4.1 本地调试阶段(轻量配置)
需求:
- 快速验证 “用户输入论文标题→LLM 生成摘要→存储到数据库” 的流程;
- 本地 CPU 运行,无需 GPU。
配置与操作:
- 使用基础版
compose.yaml,LLM 服务指定distilgpt2模型,向量数据库选用轻量的chromadb(替代 Postgres); - 执行
docker compose up,启动 LLM、ChromaDB、前端服务; - 在前端输入 “Attention Is All You Need”,验证智能体能否生成正确的论文摘要,并将结果存储到 ChromaDB。
优势:
- 本地启动时间 < 2 分钟,适合快速迭代功能逻辑;
- 数据卷挂载确保 ChromaDB 数据不丢失,便于多次调试。
4.2 云端扩容阶段(大模型升级)
需求:
- 替换为 LLaMA-2-13B 模型,提升摘要生成质量;
- 增加 Weaviate 向量数据库,支持海量文献的语义检索。
配置与操作:
- 升级
compose.yaml为进阶版,修改 LLM 服务的MODEL_NAME=llama-2-13b,添加 Weaviate 服务:yaml
services: # 新增Weaviate向量数据库服务 weaviate: image: semitechnologies/weaviate:1.23.0 ports: - "8081:8080" environment: - AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED=true - PERSISTENCE_DATA_PATH=/var/lib/weaviate volumes: - weaviate_data:/var/lib/weaviate llm: environment: - MODEL_NAME=llama-2-13b # 升级大模型 - WEAVIATE_URL=http://weaviate:8080 # 连接云端Weaviate
- 执行
docker offload up,Offload 自动将 LLM、Weaviate 部署到云端 GPU 节点,前端保留在本地; - 测试 “输入研究方向→智能体检索相关文献→生成总结报告” 功能,响应延迟从本地 CPU 的 20 秒降至云端 GPU 的 2 秒以内。
优势:
- 无需改写代码与配置,仅修改模型参数即可完成升级;
- 云端 GPU 支撑大模型运行,同时 Weaviate 提供高效语义检索,满足复杂科研需求。
五、关键实践建议:平衡效率、成本与安全
使用 Docker Compose+Offload 构建 AI 智能体时,需关注 “配置稳定性”“成本控制”“数据安全” 三大核心问题,避免常见陷阱。
5.1 配置管理:确保环境一致性
- 固定镜像版本:避免使用
:latest标签(如 LLM 服务镜像用ghcr.io/langchain/langgraph:v0.1.10而非:latest),防止云端拉取意外更新的版本,导致本地与云端环境不一致; - 版本控制 Compose 文件:将
compose.yaml与.env文件(不含敏感信息)提交到 Git 仓库,团队成员共享同一配置,避免 “本地能跑,云端失败” 的问题; - 使用.dockerignore:在 LLM、前端服务目录添加
.dockerignore,排除node_modules、日志文件等无关内容,减少镜像体积(如前端镜像可从 500MB 压缩到 50MB),加快云端传输速度。
5.2 成本控制:优化 GPU 资源使用
云端 GPU 费用较高(如 AWS P4d.24xlarge 每小时约 32 美元),需通过以下方式降低成本:
- 选择合适的 GPU 规格:测试阶段用入门级 GPU(如 GCP T4,每小时约 0.8 美元),生产阶段再升级到 A100/H100;
- 利用 Spot 实例:对非实时任务(如批量文献处理),使用云端 Spot 实例(折扣 60%-90%),通过
docker offload的 “任务调度” 功能自动匹配; - 及时停止闲置服务:通过
docker offload status监控 GPU 使用率,闲置超过 10 分钟则执行docker offload stop,避免空跑计费。
5.3 安全防护:保障数据与模型安全
- 敏感信息管理:数据库密码、API 密钥等通过 Docker Secrets 或
.env文件管理,禁止硬编码到compose.yaml;若使用云端服务,确保数据传输启用 TLS 加密(Offload 默认支持); - 镜像漏洞扫描:部署前用
docker scout cves扫描 LLM、数据库镜像的漏洞(如 Postgres 的已知安全隐患),避免部署存在风险的镜像; - 合规检查:若处理敏感数据(如医疗文献、个人信息),需确认云端服务商符合 HIPAA、GDPR 等合规要求,Offload 支持筛选合规的云端节点。
AI 智能体开发的 “新范式”
Docker Compose 与 Offload 的组合,为 AI 智能体开发提供了 “本地迭代,云端扩容” 的新范式:通过一份配置文件,开发者可在本地快速验证功能,无需担心依赖冲突;当需要更大算力时,无需改写代码,仅需一条命令即可迁移到云端 GPU 节点,实现 “无缝切换”。
这种方案的核心价值在于 “降低复杂度”—— 它消除了本地与云端的环境差异,让开发者专注于 AI 智能体的功能逻辑,而非基础设施配置。无论是个人开发者测试小模型,还是企业团队部署生产级大模型,Docker Compose+Offload 都能提供高效、一致的开发体验。
未来,随着 Docker 对 AI 功能的进一步优化(如更智能的 GPU 资源调度、多云端协同),这一方案将成为 AI 智能体开发的 “标准工具链”。
对于开发者而言,现在只需从一份compose.yaml开始,就能快速踏上 AI 智能体的构建与扩容之路。