散列数据分布(Hash-based Data Distribution)是一种用于在分布式系统中分配数据的技术。它通过将数据项映射到一个固定范围的槽位上,从而实现数据的均匀分布以及高效查找。这种技术广泛应用于数据库、缓存系统和分布式文件系统等场景中,以提高系统的性能和可扩展性。
基本概念
- 散列函数:一种算法,接受任意长度的数据输入,并产生固定长度的输出值(散列值或哈希值)。理想情况下,不同的输入会产生不同的输出。
- 散列表/散列表:使用散列函数来计算存储位置的数组结构。每个元素都有一个唯一的键,该键通过散列函数转换为数组中的索引。
- 负载均衡:确保数据均匀分布在所有节点上,避免某些节点过载而其他节点空闲的情况。
应用场景
- 分布式数据库:通过散列分区技术,可以将数据集分割成多个部分,每部分存储在集群的不同节点上,从而支持大规模并行处理。
- 分布式缓存:如Redis Cluster采用了基于散列的方式进行数据分片,保证了数据访问时的一致性和高可用性。
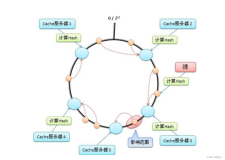
- 一致性哈希:一种特殊的散列方法,解决了传统哈希方案在节点增减时需要大量重新分配的问题。一致性哈希允许在添加或删除节点时最小化数据迁移量。
实现方式
- 直接寻址法:当数据项的数量不是特别大且键值相对集中时适用。
- 链地址法:对于可能出现冲突的情况,即不同键值可能被散列到相同的位置,可以通过链接表的方式来解决。
- 开放寻址法:包括线性探测再散列、二次探测再散列等策略,适用于内存空间有限的情形。
- 一致性哈希:通过构建一个虚拟环形结构,将节点与数据都映射到这个环上,使得即使节点数量发生变化,也只需调整少量数据的位置。
优点
- 提供了快速访问数据的能力。
- 可以有效地利用内存资源。
- 支持动态调整规模,易于扩展。
缺点
- 设计良好的散列函数比较困难。
- 在极端情况下可能会出现严重的数据倾斜问题。
- 节点变化时需要适当处理数据迁移的问题。
散列数据分布是构建高性能分布式系统的重要组成部分之一,合理选择和设计散列策略对于提升整个系统的效率至关重要。