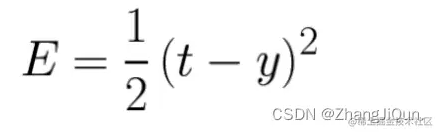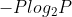3.2 交叉熵损失函数

交叉熵函数常用于逻辑回归(logistic regression),也就是分类(classification)。
3.2.1 交叉熵的由来
信息量
信息论中,信息量的表示方式:

假设对于学习神经网络原理课程,我们有三种可能的情况发生,如表3-2所示。
表3-2 三种事件的概论和信息量
| 事件编号 | 事件 | 概率 p | 信息量 I |
| x1 | 优秀 | p=0.7 | I=−ln(0.7)=0.36 |
| x2 | 及格 | p=0.2 | I=−ln(0.2)=1.61 |
| x3 | 不及格 | p=0.1 | I=−ln(0.1)=2.30 |
WoW,某某同学不及格!好大的信息量!相比较来说,“优秀”事件的信息量反而小了很多。
熵

则上面的问题的熵是:

相对熵(KL散度)

交叉熵
把上述公式变形:


3.2.2 二分类问题交叉熵

3.2.3 多分类问题交叉熵
当标签值不是非0即1的情况时,就是多分类了。假设期末考试有三种情况:
- 优秀,标签值OneHot编码为[1,0,0][1,0,0]
- 及格,标签值OneHot编码为[0,1,0][0,1,0]
- 不及格,标签值OneHot编码为[0,0,1][0,0,1]

可以看到,0.51比1.2的损失值小很多,这说明预测值越接近真实标签值(0.6 vs 0.3),交叉熵损失函数值越小,反向传播的力度越小。
3.2.4 为什么不能使用均方差做为分类问题的损失函数?
- 回归问题通常用均方差损失函数,可以保证损失函数是个凸函数,即可以得到最优解。而分类问题如果用均方差的话,损失函数的表现不是凸函数,就很难得到最优解。而交叉熵函数可以保证区间内单调。
- 分类问题的最后一层网络,需要分类函数,Sigmoid或者Softmax,如果再接均方差函数的话,其求导结果复杂,运算量比较大。用交叉熵函数的话,可以得到比较简单的计算结果,一个简单的减法就可以得到反向误差。