第七章:数据和模型的可视化
本章内容
可视化对于机器学习从业者来说是一项重要的技能,因为它涉及到机器学习工作流的每个阶段。在我们构建模型之前,我们通过可视化来检查数据;在模型工程和训练期间,我们通过可视化来监测训练过程;模型训练完毕后,我们使用可视化来了解其工作原理。
在第六章中,你了解到在应用机器学习之前,可视化和了解数据的好处。我们介绍了如何使用 Facets,这是一个基于浏览器的工具,可以帮助你快速、交互式地查看数据。在本章中,我们将介绍一个新工具 tfjs-vis,它可以帮助你以自定义、程序化的方式可视化数据。这样做的好处,相较于只看数据的原始格式或使用 Facets 等现成工具,是更灵活、多样的可视化范式以及更深入理解数据的可能性。
除了数据可视化外,我们还会展示如何在深度学习模型训练后使用可视化。我们将使用深入的例子,通过可视化内部激活和计算卷积神经网络层最大程度“激发”的模式,来窥视神经网络“黑盒”的潜力。这将完整展现可视化如何在每个阶段与深度学习相辅相成的故事。
完成本章后,你应该知道为什么可视化是任何机器学习工作流不可或缺的一部分。你还应该熟悉在 TensorFlow.js 框架中可视化数据和模型的标准方式,并能够将它们应用到自己的机器学习问题中。
7.1 数据可视化
让我们从数据可视化开始,因为这是机器学习实践者在解决新问题时首先做的事情。我们假设可视化任务比 Facets 能够覆盖的更高级(例如,数据不在一个小的 CSV 文件中)。因此,我们首先会介绍一个基本的图表 API,它可以帮助你在浏览器中创建简单且广泛使用的绘图类型,包括折线图、散点图、条形图和直方图。在完成使用手工编写的数据的基本示例后,我们将通过一个涉及可视化有趣真实数据集的示例将事物整合起来。
7.1.1 使用 tfjs-vis 可视化数据
tfjs-vis 是一个与 TensorFlow.js 紧密集成的可视化库。本章将介绍其许多功能之一,即其 tfvis.render.* 命名空间下的轻量级图表 API。这个简单直观的 API 允许你在浏览器中制作图表,重点关注机器学习中最常用的图表类型。为了帮助你开始使用 tfvis.render,我们将给你介绍一个 CodePen,地址为 codepen.io/tfjs-book/pen/BvzMZr,该 CodePen 展示了如何使用 tfvis.render 创建各种基本数据图。
¹
此绘图 API 是建立在 Vega 可视化库之上的:
vega.github.io/vega/。
tfjs-vis 的基础知识
首先,注意 tfjs-vis 是独立于主要的 TensorFlow.js 库的。你可以从 CodePen 如何用 <script> 标签导入 tfjs-vis 来看出这一点:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@latest"> </script>
这与导入主要的 TensorFlow.js 库的方式不同:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest"> </script>
tfjs-vis 和 TensorFlow.js 的 npm 包有所不同(分别是 @tensorflow/tfjs-vis 和 @tensorflow/tfjs)。在一个依赖于 TensorFlow.js 和 tfjs-vis 的网页或 JavaScript 程序中,这两个依赖都必须被导入。
线图
最常用的图表类型可能是 线图(一个曲线,将一个数量绘制成有序数量)。线图有一个水平轴和一个垂直轴,通常分别称为 x 轴 和 y 轴。这种类型的可视化在生活中随处可见。例如,我们可以通过线图将一天中温度的变化情况绘制出来,其中水平轴是一天中的时间,垂直轴是温度计的读数。线图的水平轴也可以是其他东西。例如,我们可以使用线图来显示高血压药物的治疗效应(它降低了多少血压)与剂量(每天使用多少药物)之间的关系。这样的绘图被称为 剂量-反应曲线。另一个非时间线图的很好的例子是我们在第三章中讨论的 ROC 曲线。那里,x 轴和 y 轴都与时间无关(它们是二元分类器的假阳性和真阳性率)。
要使用 tfvis.render 创建线图,可以使用 linechart() 函数。正如 CodePen 的第一个示例(也是清单 7.1)所示,该函数需要三个参数:
- 第一个参数是用于绘制图表的 HTML 元素。可以使用空的
<div>元素。 - 第二个参数是图表中数据点的值。这是一个包含
value字段并指向一个数组的普通 JavaScript 对象(POJO)。数组由多个 x-y 值对组成,每个值对由一个包含名为x和y字段的 POJO 表示。x和y值分别是数据点的 x 和 y 坐标。 - 第三个参数(可选)包含线图的其他配置字段。在这个例子中,我们使用
width字段来指定结果图的宽度(以像素为单位)。在后面的例子中您将看到更多的配置字段。^([2])
²
js.tensorflow.org/api_vis/latest/包含 tfjs-vis API 的完整文档,在这里您可以找到关于此函数的其他配置字段的信息。
清单 7.1. 使用tfvis.render.linechart()创建一个简单的折线图
let values = [{x: 1, y: 20}, {x: 2, y: 30}, {x: 3, y: 5}, {x: 4, y: 12}]; ***1*** tfvis.render.linechart(document.getElementById('plot1'), ***2*** {values}, ***3*** {width: 400}); ***4***
- 1 数据系列是一个包含 x-y 对的数组。
- 2 第一个参数是将绘制图表的 HTML 元素。这里的’plot1’是一个空的 div 的 ID。
- 3 第二个参数是一个包含键“值”的对象。
- 4 自定义配置作为第三个参数传递。在这种情况下,我们只配置了图的宽度。
由清单 7.1 中的代码创建的折线图显示在图 7.1 的左侧面板中。这是一个只有四个数据点的简单曲线。但是,linechart()函数可以支持更多数据点的曲线(例如,数千个)。然而,如果你尝试一次绘制太多数据点,你最终会遇到浏览器的资源限制。限制与浏览器和平台相关,应当通过实证方法来确定。一般来说,为了使用户界面流畅响应,限制图表中可呈现的数据大小是一个好习惯。
图 7.1. 使用tfvis.render.linechart()创建的折线图。左侧:使用清单 7.1 中的代码创建的单个系列。右侧:使用清单 7.2 中的代码在同一个坐标轴上创建的两个系列。
有时您想在同一张图中绘制两条曲线,以显示它们之间的关系(例如相互比较)。您可以使用tfvis.render.linechart()制作这些类型的图表。示例显示在图 7.1 的右侧面板中,代码在清单 7.2 中。
这些被称为多系列图表,每条线称为系列。要创建多系列图表,必须在传递给linechart()的第一个参数中包括一个附加字段series。该字段的值是一个字符串数组。这些字符串是系列的名称,并将作为图表中的图例呈现。在示例代码中,我们将系列称为'My series 1'和'My series 2'。
对于多系列图表,第一个参数的value字段也需要恰当地指定。对于我们的第一个示例,我们提供了一个点数组,但是对于多系列图表,我们必须提供一个数组的数组。嵌套数组的每个元素都是一个系列的数据点,并且具有与我们在清单 7.1 中绘制单系列图表时看到的值数组相同的格式。因此,嵌套数组的长度必须与series数组的长度匹配,否则将出现错误。
由清单 7.2 创建的图表显示在图 7.1 的右侧面板中。如您在本书的电子版本中图表中所见,tfjs-vis 选择两种不同的颜色(蓝色和橙色)来渲染两条曲线。这种默认的着色方案通常很有效,因为蓝色和橙色很容易区分。如果有更多的系列需要呈现,其他新颜色将自动选择。
此示例图表中的两个系列在 x 坐标的值(1、2、3 和 4)完全相同。但是,在多系列图表中,不同系列的 x 坐标值不一定相同。您可以尝试在本章末尾的练习 1 中尝试这种情况。但是,需要注意的是,将两条曲线绘制在同一个线条图表中并不总是明智的做法。例如,如果两条曲线具有非常不同并且不重叠的 y 值范围,则将它们绘制在同一个线条图表中会使每个曲线的变化更难以看到。在这种情况下,最好将它们绘制在单独的线条图表中。
在清单 7.2 中还值得指出的是轴的自定义标签。 我们使用配置对象中的xLabel和yLabel字段(传递给linechart()的第三个参数)来标记我们选择的自定义字符串的 x 和 y 轴。 通常,标记轴是一种良好的实践,因为它使图表更易于理解。 如果您没有指定xLabel和yLabel,tfjs-vis 将始终将您的轴标记为x和y,这就是清单 7.1 和图 7.1 的左面板所发生的。
清单 7.2。使用 tfvis.render.linechart()制作带有两个系列的线条图表
values = [ ***1*** [{x: 1, y: 20}, {x: 2, y: 30}, {x: 3, y: 5}, {x: 4, y: 12}], ***1*** [{x: 1, y: 40}, {x: 2, y: 0}, {x: 3, y: 50}, {x: 4, y: -5}] ***1*** ]; ***1*** let series = ['My series 1', 'My series 2']; ***2*** tfvis.render.linechart( document.getElementById('plot2'), {values, series}, { width: 400, xLabel: 'My x-axis label', ***3*** yLabel: 'My y-axis label' ***3*** });
- 1 为了在相同的轴上显示多个系列,使值成为由多个 x-y 对数组组成的数组。
- 2 在绘制多个系列时,必须提供系列名称。
- 3 覆盖默认的 x 和 y 坐标轴标签。
散点图
散点图 是您可以使用 tfvis.render 创建的另一种图表类型。散点图与折线图最显著的区别在于,散点图不使用线段连接数据点。这使得散点图适用于数据点间顺序不重要的情况。例如,散点图可以将几个国家的人口与人均国内生产总值进行绘制。在这样的图中,主要信息是 x 值和 y 值之间的关系,而不是数据点之间的顺序。
在 tfvis.render 中,让您创建散点图的函数是 scatterplot()。正如 清单 7.3 中的示例所示,scatterplot() 可以呈现多个系列,就像 linechart() 一样。事实上,scatterplot() 和 linechart() 的 API 实际上是相同的,您可以通过比较 清单 7.2 和 清单 7.3 来了解。清单 7.3 创建的散点图显示在 图 7.2 中。
图 7.2. 包含两个系列的散点图,使用 清单 7.3 中的代码制作。
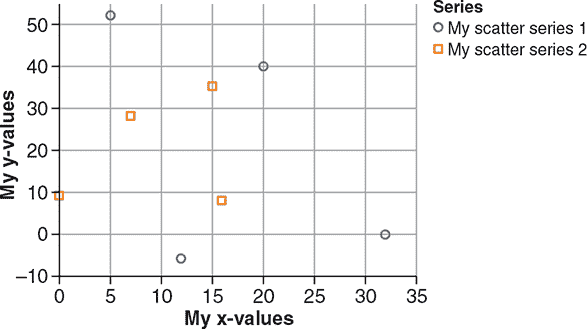
清单 7.3. 使用 tfvis.render.scatterplot() 制作散点图
values = [ ***1*** [{x: 20, y: 40}, {x: 32, y: 0}, {x: 5, y: 52}, {x: 12, y: -6}], ***1*** [{x: 15, y: 35}, {x: 0, y: 9}, {x: 7, y: 28}, {x: 16, y: 8}] ***1*** ]; ***1*** series = ['My scatter series 1', 'My scatter series 2']; tfvis.render.scatterplot( document.getElementById('plot4'), {values, series}, { width: 400, xLabel: 'My x-values', ***2*** yLabel: 'My y-values' ***2*** });
- 1 与 linechart() 一样,使用 x-y 对数组的数组来在散点图中显示多个系列
- 2 记得始终标记你的轴。
柱状图
如其名称所示,柱状图 使用柱形显示数量的大小。这些柱通常从底部的零开始,以便可以从柱形的相对高度读取数量之间的比率。因此,当数量之间的比率很重要时,柱状图是一个不错的选择。例如,自然而然地使用柱状图来显示公司几年来的年收入。在这种情况下,柱形的相对高度使观众对收入在季度之间的变化情况有直观的感觉。这使得柱状图与折线图和散点图有所不同,因为这些值不一定“锚定”在零点上。
要使用tfvis.render创建条形图,请使用barchart()。您可以在代码清单 7.4 中找到一个示例。代码创建的条形图显示在图 7.3 中。barchart()的 API 类似于linechart()和scatterplot()的 API。但是,应该注意一个重要的区别。传递给barchart()的第一个参数不是由value字段组成的对象。相反,它是一个简单的索引-值对数组。水平值不是用一个叫做x的字段指定的,而是用一个叫做index的字段指定的。同样,垂直值不是用一个叫做y的字段指定的,而是与一个叫做value的字段关联的。为什么有这种区别?这是因为条形图中条形的水平值不一定是一个数字。相反,它们可以是字符串或数字,正如我们在图 7.3 的示例中所示。
图 7.3. 由代码清单 7.4 生成的包含字符串和数字命名条的条形图
代码清单 7.4. 使用tfvis.render.barchart()创建条形图
const data = [ {index: 'foo', value: 1},{index: 'bar', value: 7}, ***1*** {index: 3, value: 3}, ***1*** {index: 5, value: 6}]; ***1*** tfvis.render.barchart(document.getElementById('plot5'), data, { yLabel: 'My value', width: 400 });
- 1 请注意条形图的索引可以是数字或字符串。请注意元素的顺序很重要。
直方图
先前描述的三种图表类型允许您绘制某个数量的值。有时,详细的定量值并不像值的分布那样重要。例如,考虑一位经济学家查看国家普查结果中的年度家庭收入数据。对于经济学家来说,详细的收入数值并不是最有趣的信息。它们包含了太多信息(是的,有时候太多信息可能是一件坏事!)。相反,经济学家想要更简洁的收入数值摘要。他们对这些值是如何分布感兴趣——即有多少个值低于 2 万美元,有多少个值介于 2 万美元和 4 万美元之间,或者介于 4 万美元和 6 万美元之间,等等。直方图是一种适合这种可视化任务的图表类型。
直方图将值分配到区间中。每个区间只是一个值的连续范围,有一个下界和一个上界。区间被选择为相邻的,以覆盖所有可能的值。在前面的例子中,经济学家可能使用诸如 0 ~ 20k、20k ~ 40k、40k ~ 60k 等的区间。一旦选择了这样一组N个区间,您就可以编写一个程序来计算落入每个区间的单个数据点的数量。执行此程序将给您N个数字(每个区间一个)。然后,您可以使用垂直条形图绘制这些数字。这就给您一个直方图。
tfvis.render.histogram() 会为您执行所有这些步骤。这样可以省去您确定箱界限并按箱计数示例的麻烦。要调用 histogram(),只需传递一个数字数组,如下面的列表所示。这些数字不需要按任何顺序排序。
第 7.5 节。使用 tfvis.render.histogram() 可视化值分布。
const data = [1, 5, 5, 5, 5, 10, -3, -3]; tfvis.render.histogram(document.getElementById('plot6'), data, { ***1*** width: 400 ***1*** }); ***1*** // Histogram: with custom number of bins. // Note that the data is the same as above. tfvis.render.histogram(document.getElementById('plot7'), data, { maxBins: 3, ***2*** width: 400 });
- 1 使用自动生成的箱。
- 2 指定了明确的箱数。
在 列表 7.5 中,有两个略有不同的 histogram() 调用。第一个调用除了绘图宽度之外没有指定任何自定义选项。在这种情况下,histogram() 使用其内置的启发式方法来计算箱。结果是七个箱:–4 ~ –2,–2 ~ 0,0 ~ 2,…,8 ~ 10,如图 7.4 的左面板所示。在这七个箱中,直方图显示在 4 ~ 6 箱中具有最高值,其中包含 4 个计数,因为数据数组中的四个值为 5。直方图的三个箱(–2 ~ 0,2 ~ 4 和 6 ~ 8)的值为零,因为数据点的元素都没有落入这三个箱中。
图 7.4。相同数据的直方图,使用自动计算的箱(左)和明确指定的箱数(右)绘制。生成这些直方图的代码在 列表 7.5 中。
因此,我们可以认为默认的启发式方法对于我们特定的数据点来说生成了太多的箱。如果箱数较少,那么不太可能会有任何箱是空的。您可以使用配置字段 maxBins 来覆盖默认的箱子启发式方法并限制箱子数量。这就是列表 7.5 中第二个 histogram() 调用所做的,其结果在图 7.4 中右侧显示。您可以看到通过将箱数限制为三个,所有箱都变得非空。
热图
热图 将数字的 2D 数组显示为彩色单元格的网格。每个单元格的颜色反映了 2D 数组元素的相对大小。传统上,“较冷”的颜色(如蓝色和绿色)用于表示较低的值,而“较暖”的颜色(如橙色和红色)则用于表示较高的值。这就是为什么这些图被称为热图。在深度学习中最常见的热图例子可能是混淆矩阵(参见第三章中的鸢尾花示例)和注意力矩阵(参见第九章中的日期转换示例)。tfjs-vis 提供了函数 tfvis.render.heatmap() 来支持此类可视化的渲染。
列表 7.6 展示了如何制作一个热图来可视化涉及三个类别的虚构混淆矩阵。混淆矩阵的值在第二个输入参数的 values 字段中指定。类别的名称,用于标记热图的列和行,是作为 xTickLabels 和 yTickLabels 指定的。不要将这些刻度标签与第三个参数中的 xLabel 和 yLabel 混淆,后者用于标记整个 x 和 y 轴。图 7.5 展示了生成的热图绘图。
图 7.5. 由 列表 7.6 中的代码渲染的热图。它展示了一个涉及三个类别的虚构混淆矩阵。
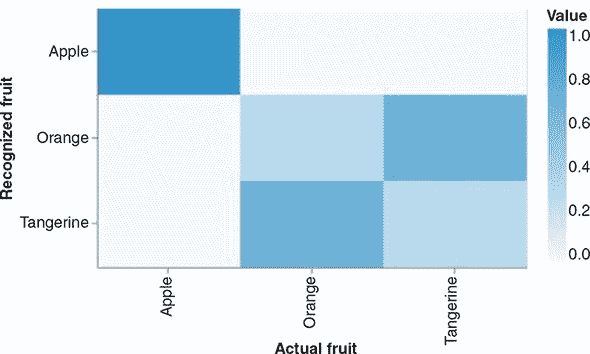
列表 7.6. 使用 tfvis.render.heatmap() 可视化 2D 张量
tfvis.render.heatmap(document.getElementById('plot8'), { values: [[1, 0, 0], [0, 0.3, 0.7], [0, 0.7, 0.3]], ***1*** xTickLabels: ['Apple', 'Orange', 'Tangerine'], ***2*** yTickLabels: ['Apple', 'Orange', 'Tangerine'] ***2*** }, { width: 500, height: 300, xLabel: 'Actual Fruit', ***3*** yLabel: 'Recognized Fruit', ***3*** colorMap: 'blues' ***4*** });
- 1 传递给 heatmap() 的值可以是嵌套的 JavaScript 数组(如此处所示)或 2D tf.Tensor。
- 2 xTickLabels 用于标记沿 x 轴的单个列。不要与 xLabel 混淆。同样,yTickLabels 用于标记沿 y 轴的单个行。
- 3 xLabel 和 yLabel 用于标记整个坐标轴,不同于 xTickLabel 和 yTickLabel。
- 4 除了这里展示的“蓝色”色图外,还有“灰度”和“翠绿”。
这就是我们对 tfvis.render 支持的四种主要图表类型的快速介绍。如果你未来的工作涉及使用 tfjs-vis 进行数据可视化,很有可能会经常使用这些图表。表 7.1 提供了图表类型的简要摘要,以帮助您决定在给定的可视化任务中使用哪种图表。
表 7.1. tfjs-vis 在 tfvis.render 命名空间下支持的五种主要图表类型的摘要
| 图表名称 | tfjs-vis 中对应的函数 | 适合的可视化任务和机器学习示例 |
| 折线图 | tfvis.render.linechart() | 一个标量(y 值)随另一个具有固有顺序(时间、剂量等)的标量(x 值)变化。多个系列可以在同一坐标轴上绘制:例如,来自训练集和验证集的指标,每个指标都根据训练轮次数量绘制。 |
| 散点图 | tfvis.render.scatterplot() | x-y 标量值对,没有固有的顺序,例如 CSV 数据集的两个数值列之间的关系。多个系列可以在同一坐标轴上绘制。 |
| 条形图 | tfvis.render.barchart() | 一组属于少数类别的值,例如几个模型在相同分类问题上实现的准确率(以百分比数字表示)。 |
| 直方图 | tfvis.render.histogram() | 分布的主要兴趣是一组值,例如密集层内核中参数值的分布。 |
| 热力图 | tfvis.render.heathmap() | 一种二维数字数组,以 2D 网格单元格的形式进行可视化,每个元素的颜色用于反映对应值的大小:例如,多类别分类器的混淆矩阵(3.3 节);序列到序列模型的注意力矩阵(9.3 节)。 |
7.1.2. 一个综合案例研究:使用 tfjs-vis 可视化天气数据
上一节的 CodePen 示例使用的是小型的手动编码数据。在本节中,我们将展示如何在更大更有趣的真实数据集上使用 tfjs-vis 的图表功能。这将展示出 API 的真正强大之处,并且为在浏览器中进行数据可视化的价值提供论据。这个示例还将突出一些在解决实际问题时可能遇到的微妙之处和陷阱。
我们将使用的数据是 Jena-weather-archive 数据集。它包括在德国耶拿(Jena)地区的一个位置上使用各种气象仪器收集的数据,涵盖了八年的时间(2009 年至 2017 年)。可以从 Kaggle 页面上下载该数据集(参见www.kaggle.com/pankrzysiu/weather-archive-jena),它以一个 42MB 的 CSV 文件的形式提供。它包含 15 列,第一列是时间戳,其余列是气象数据,如温度(T deg(C))、气压(p (mbar))、相对湿度(rh (%s))、风速(wv (m/s))等。如果你检查时间戳,你会发现它们之间有 10 分钟的间隔,反映出测量是每隔 10 分钟进行一次。这是一个丰富的数据集,可以进行可视化、探索和尝试机器学习。在接下来的章节中,我们将尝试使用不同的机器学习模型进行天气预报。特别是,我们将使用前 10 天的天气数据来预测第二天的温度。但在我们开始这个令人兴奋的天气预测任务之前,让我们遵循“在尝试机器学习之前,始终查看数据”的原则,看看 tfjs-vis 如何以清晰直观的方式绘制数据。
要下载和运行 Jena-weather 示例,请使用以下命令:
git clone https://github.com/tensorflow/tfjs-examples.git cd tfjs-examples/jena-weather yarn yarn watch
限制数据量以进行高效有效的可视化
Jena-weather 数据集相当大。文件大小为 42MB,比迄今为止本书中看到的所有 CSV 或表格数据集都要大。这导致了两个挑战:
- 第一个挑战是对计算机而言:如果一次绘制八年的所有数据,浏览器选项卡将耗尽资源,变得无响应,并可能崩溃。即使你仅限制在 14 列中的 1 列,仍然有大约 42 万个数据点需要显示。这比 tfjs-vis(或任何 JavaScript 绘图库)能够安全渲染的量要多。
- 第二个挑战是对用户而言:一次查看大量数据并从中提取有用信息是困难的。例如,有人应该如何查看所有 420,000 个数据点并从中提取有用信息?就像计算机一样,人类大脑的信息处理带宽是有限的。可视化设计师的工作是以高效的方式呈现数据的最相关和最有信息量的方面。
我们使用三种技巧来解决这些挑战:
- 我们不是一次性绘制整个八年的数据,而是让用户使用交互式用户界面选择要绘制的时间范围。这就是用户界面中时间跨度下拉菜单的目的(请参见 图 7.6 和 7.7 中的截屏)。时间跨度选项包括 Day、Week、10 Days、Month、Year 和 Full。最后一个对应于整个八年。对于任何其他时间跨度,用户界面允许用户在时间上前后移动。这就是左箭头和右箭头按钮的作用。
图 7.6. 展示了 Jena 气象档案数据集中温度(T(degC))和气压(p(mbar))的折线图,分别以两种不同的时间尺度绘制。顶部:10 天时间跨度。注意温度曲线中的日常周期。底部:1 年时间跨度。注意温度曲线中的年度周期以及春季和夏季期间气压相对其他季节更稳定的轻微倾向。
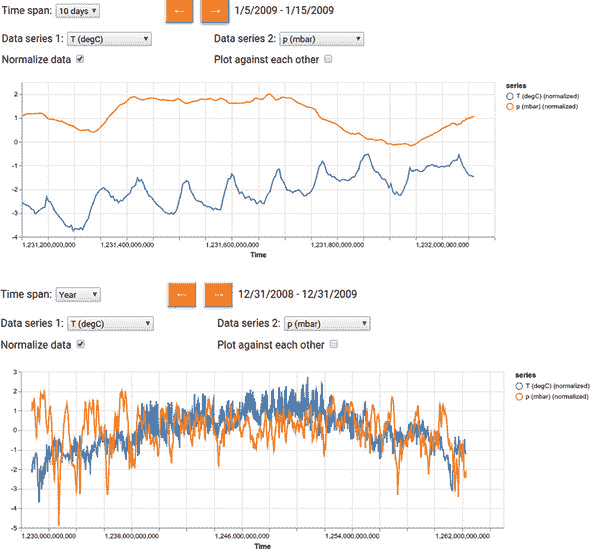
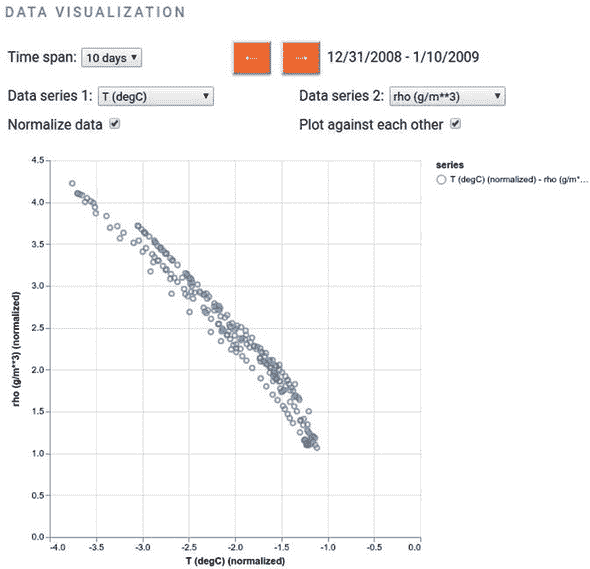
图 7.7. Jena 气象演示的散点图示例。该图显示了空气密度(rho,纵轴)和温度(T,横轴)之间的关系,时间跨度为 10 天,可以看到负相关性。
- 对于任何超过一周的时间跨度,我们在将时间序列绘制到屏幕上之前进行降采样。例如,考虑时间跨度为一个月(30 天)。这个时间跨度的完整数据包含约 30 * 24 * 6 = 4.32k 个数据点。在 清单 7.7 中的代码中,您可以看到我们在显示一个月的数据时仅绘制每六个数据点。这将绘制的数据点数量减少到 0.72k,大大降低了渲染成本。但对于人眼来说,数据点数量的六倍减少几乎没有什么差别。
- 与我们在时间跨度下拉菜单中所做的类似,我们在用户界面中包含一个下拉菜单,以便用户可以选择在任何给定时间绘制什么天气数据。注意标有 Data Series 1 和 Data Series 2 的下拉菜单。通过使用它们,用户可以在同一坐标轴上将任何 1 或任何 2 个 14 列中的数据作为折线图绘制到屏幕上。
7.7 节的示例展示了负责制作与图 7.6 类似的图表的代码。尽管代码调用了tfvis.render.linechart(),与前一节中的 CodePen 示例相似,但与前面列表中的代码相比,它要抽象得多。这是因为在我们的网页中,我们需要根据 UI 状态延迟决定要绘制的数量。
7.7 节。Jena 天气数据作为多系列折线图(在 jena-weather/index.js 中)
function makeTimeSerieChart( series1, series2, timeSpan, normalize, chartContainer) { const values = []; const series = []; const includeTime = true; if (series1 !== 'None') { values.push(jenaWeatherData.getColumnData( ***1*** series1, includeTime, normalize, currBeginIndex, TIME_SPAN_RANGE_MAP[timeSpan], ***2*** TIME_SPAN_STRIDE_MAP[timeSpan])); ***3*** series.push(normalize ? `${series1} (normalized)` : series1); } if (series2 !== 'None') { ***4*** values.push(jenaWeatherData.getColumnData( series2, includeTime, normalize, currBeginIndex, TIME_SPAN_RANGE_MAP[timeSpan], TIME_SPAN_STRIDE_MAP[timeSpan])); series.push(normalize ? `${series2} (normalized)` : series2); } tfvis.render.linechart({values, series: series}, chartContainer, { width: chartContainer.offsetWidth * 0.95, height: chartContainer.offsetWidth * 0.3, xLabel: 'Time', ***5*** yLabel: series.length === 1 ? series[0] : '' }); }
- 1 jenaWeatherData 是一个帮助我们组织和检索来自 CSV 文件的天气数据的对象。请参阅 jena-weather/data.js。
- 2 指定可视化的时间跨度
- 3 选择适当的步幅(降采样因子)
- 4 利用了 tfjs-vis 的折线图支持多系列的特性。
- 5 总是标记轴。
鼓励您探索数据可视化界面。它包含许多有趣的天气模式,您可以发现。例如,图 7.6 的顶部面板显示了在 10 天内温度(T (degC))和标准化气压(p (mbar))是如何变化的。在温度曲线中,您可以看到一个明显的日循环:温度倾向于在中午左右达到峰值,并在午夜后不久达到最低点。在日循环之上,您还可以看到在这 10 天期间的一个更全局的趋势(逐渐增加)。相比之下,气压曲线在这个时间尺度上没有显示出明显的模式。同一图的底部面板显示了一年时间跨度内的相同测量值。在那里,您可以看到温度的年循环:它在八月左右达到峰值,并在一月左右达到最低点。气压再次显示出一个不太清晰的模式,比起温度,在这个时间尺度上。压力在整个年份内可能以一种略微混沌的方式变化,尽管在夏季周围,似乎有一个较少变化的倾向,而在冬季则相反。通过在不同的时间尺度上查看相同的测量值,我们可以注意到各种有趣的模式。如果我们只看数字 CSV 格式的原始数据,所有这些模式几乎是不可能注意到的。
在图 7.6 中的图表中,你可能已经注意到它们显示的是温度和气压的归一化值,而不是它们的绝对值,这是因为我们在生成这些图表时勾选了 UI 中的“Normalize Data”复选框。我们在第二章中讨论波士顿房价模型时简单提到了归一化。那里的归一化涉及将平均值减去,然后除以标准差的结果。我们这里进行的归一化完全相同。然而,这不仅仅是为了我们机器学习模型的准确性(下一节将介绍),还是为了可视化。为什么呢?如果你尝试在图表显示温度和气压时取消勾选“Normalize Data”复选框,你会立即看到原因。温度测量值的范围在-10 到 40 之间(摄氏度),而气压的范围在 980 到 1,000 之间。在没有归一化的情况下,具有非常不同范围的两个变量会导致 y 轴扩展到非常大的范围,使得两条曲线看起来基本上是平的,并且只有微小的变化。通过归一化,可以避免这个问题,将所有测量值映射到零平均值和单位标准差的分布。
图 7.7 展示了一个将两个气象测量值绘制为散点图的示例,你可以通过勾选“Plot Against Each Other”复选框并确保两个“Data Series”下拉菜单都不是“None”来激活此模式。制作这样的散点图的代码与清单 7.7 中的makeTimeSerieChart()函数相似,因此这里为了简洁起见省略了。如果你对细节感兴趣,可以在相同的文件(jena-weather/index.js)中进行研究。
这个示例散点图展示了归一化空气密度(y 轴)和归一化温度(x 轴)之间的关系。在这里,你可以发现两个变量之间存在较强的负相关性:随着温度的升高,空气密度将降低。这个示例图表使用了 10 天的时间跨度,但你可以验证这种趋势在其他时间跨度下也基本保持不变。这种变量之间的相关性可以通过散点图轻松地可视化,但只通过文本格式的数据很难发现。这再次展示了数据可视化的强大价值。
JavaScript 深度学习(三)(2)https://developer.aliyun.com/article/1516962
