导语:2023 年 3 月,在阿里云瑶池数据库峰会上,阿里云与飞轮科技正式达成战略合作协议,双方旨在共同研发名为“阿里云数据库 SelectDB 版”的新一代实时数据仓库,为用户提供在阿里云上的全托管服务。
SelectDB 是飞轮科技基于 Apache Doris 内核打造的聚焦于企业大数据实时分析需求的企业级产品。因此阿里云数据库 SelectDB 版也延续了 Apache Doris 性能优异、架构精简、稳定可靠、生态丰富等核心特性,同时还融入了云服务随需而用的特性,通过云原生存算分离的创新架构,为企业带来分钟级弹性伸缩、高性价比、简单易用、安全稳定的一键式云上实时分析体验。
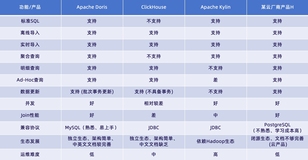
为了更深度的了解阿里云数据库 SelectDB 版,我们可以全面多角度的了解 Apache Doris 的应用实践和经验。
亲爱的社区小伙伴们,Apache Doris 2.1.3 版本已于 2024 年 5 月 20 日正式发布。该版本在功能特性上对数据湖、物化视图、负载管理等方面进行了多项更新,进一步简化湖仓一体架构、加速了查询性能;同时提交了若干改进项以及问题修复,进一步提升了系统的性能及稳定性,欢迎大家下载体验。
官网下载: https://doris.apache.org/download/
GitHub 下载: https://github.com/apache/doris/releases
功能特性
1. 支持通过 Hive Catalog 向 Hive 表中回写数据
从 2.1.3 版本开始,Apache Doris 支持对 Hive 的 DDL 和 DML 操作。用户可以直接通过 Apache Doris 在 Hive 中创建库表,通过执行INSERT INTO语句来向 Hive 表中写入数据。通过该功能,用户可以通过 Apache Doris 对 Hive 进行完整的数据查询和写入操作,进一步帮助用户简化湖仓一体架构。
参考文档:https://doris.apache.org/docs/lakehouse/datalake-building/hive-build/
2. 支持在异步物化视图之上构建新的异步物化视图
用户可以在异步物化视图之上来创建新的异步物化视图,直接复用计算好的中间结果进行数据加工处理,简化复杂的聚合和计算操作带来的资源消耗和维护成本,进一步加速查询性能、提升数据可用性。
3. 支持通过物化视图嵌套物化视图进行重写
物化视图(Materialized View,MV)是用于存储查询结果的数据库对象。现在,Apache Doris 支持通过 MV 嵌套物化视图进行重写,这有助于优化查询性能。
4. 新增 SHOW VIEWS 语句
可以使用SHOW VIEWS语句来查询数据库中的视图,有助于更好地管理和理解数据库中的视图对象。
5. Workload Group 支持绑定到特定的 BE 节点
Workload Group 可以绑定到特定的 BE 节点,实现查询执行的更精细化控制,以优化资源使用和提高性能。
6. Broker Load 支持压缩的 JSON 格式
Broker Load 支持导入压缩的 JSON 格式数据,可以显著减少数据传输的带宽需求、加速数据导入性能。
7. TRUNCATE 函数可以使用列作为 scale 参数
TRUNCATE 函数现在可以接受列作为 scale 参数,这使得在处理数值数据时可以更加灵活。
8. 添加新的函数 uuid_to_int 和 int_to_uuid
这两个函数允许用户在 UUID 和整数之间进行转换,对于需要处理 UUID 数据的场景有明显帮助。
9. 添加 bypass_workload_group Session Variable 以绕过查询队列
会话变量 bypass_workload_group 允许某些查询绕过 Workload Group 队列直接执行,这可以用于处理需要快速响应的关键查询。
10. 添加 strcmp 函数
strcmp 函数用于比较两个字符串并返回它们的比较结果,帮助文本数据的处理更加简易。
11. 支持 HLL 函数 hll_from_base64 和 hll_to_base64
HLL(HyperLogLog)是一种用于基数估计的算法,以上两个函数允许用户将 HLL 数据从 Base64 编码的字符串中解码,或将 HLL 数据编码为 Base64 字符串,这对于存储和传输 HLL 数据非常有用。
优化改进
1. 替换 SipHash 为 XXHash 以改善 Shuffle 性能
SipHash 和 XXHash 都是哈希函数,但 XXHash 在某些场景下可能提供更快的哈希速度和更好的性能,此优化旨在通过采用 XXHash 来提高数据 Shuffle 过程中的性能。
2. 异步物化视图支持 OLAP 表分区列为可以为 NULL:
允许异步物化视图支持 OLAP 表的分区列可以为 NULL,从而增强了数据处理的灵活性。
3. 收集列统计信息时限制最大字符串长度为 1024 以控制 BE 内存使用
在收集列统计信息时,限制字符串的长度可以防止过大的数据消耗过多的 BE 内存,有助于保持系统的稳定性和性能。
4. 支持动态删除 Bitmap Cache 以提高性能
通过支持动态删除不再需要的 Bitmap Cache,可以释放内存并改善系统性能。
5. 在 ALTER 操作中减少内存使用
减少 ALTER 操作中的内存使用,以提高系统资源的利用效率。
6. 支持复杂类型的常量折叠
支持 Array/Map/Struct 复杂类型的常量折叠;
7. 在 Aggregate Key 聚合模型中增加对 Variant 类型的支持
Variant 数据类型能够存储多种数据类型,在此优化中允许对 Variant 类型的数据进行聚合操作,从而增强了半结构化数据分析的灵活性。
8. 在 CCR 中支持新的倒排索引格式
9. 优化嵌套物化视图的重写性能
10. 支持 decimal256 类型的行存格式
在行存格式中支持 decimal 256 类型,以以扩展系统对高精度数值数据的处理能力。
行为变更
1. 授权(Authorization)
Grant_priv 权限更改:
Grant_priv不能再被任意授予。执行GRANT操作时,用户不仅需要具有Grant_priv,还需要具有要授予的权限。例如,如果想要授予对table1的SELECT权限,那么该用户不仅需要具有GRANT权限,还需要具有对table1的SELECT权限,这增加了权限管理的安全性和一致性。Workload Group 和 Resource 的 Usage_priv:
Usage_priv对 Workload Group 和 Resource 的权限不再是全局级别的,而是仅限于 Resource 和 Workload Group 内,权限的授予和使用将更加具体。操作的授权:之前未被授权的操作现在都有了相应的授权,以实现更加细致和全面地操作权限控制。
2. LOG 目录配置
FE 和 BE 的日志目录配置现在统一使用LOG_DIR环境变量,所有其他不同类型的日志都将以LOG_DIR作为根目录进行存储。同时为了保持版本间的兼容性,以前的配置项sys_log_dir仍然可以使用。
3. S3 表函数(TVF)
由于之前的解析方式在某些情况下可能无法正确识别或处理 S3 的 URL,因此将对象存储路径的解析逻辑进行重构。对于 S3 表函数中的文件路径,需要传递force_parsing_by_standard_uri参数来确保被正确解析。
升级问题
由于许多用户将某些关键字用作列名或属性值,因此将如下关键字设置为非保留关键字,允许用户将其用作标识符使用:
https://github.com/apache/doris/pull/34613
问题修复
1. 修复在腾讯云 COSN 上读取 Hive 表时的无数据错误
解决了在腾讯云 COSN 存储上读取 Hive 表时可能遇到的无数据错误,增强了与腾讯云存储服务的兼容性。
2. 修复 milliseconds_diff 函数返回错误结果
修复milliseconds_diff函数在某些情况下返回错误结果的问题,确保了时间差计算的准确性。
3. 用户定义变量应转发到 Master 节点
确保用户定义的变量能够正确地传递到 Master 节点,以便在整个系统中保持一致性和正确的执行逻辑。
4. 修复添加复杂类型列时遇到的 Schema Change 问题
在添加复杂类型列时,可能会遇到 Schema Change 问题,此修复确保了 Schema Change 的正确性。
- 修复 FE master 节点更改时 Routine Load 的数据丢失问题
Routine Load常用于订阅 Kafka 消息队列中的数据,此修复解决了在 FE Master 节点更改时可能导致的数据丢失问题。
6. 修复当找不到 Workload Group 时 Routine Load 失败的问题
修复了当Routine Load找不到指定 Workload Group 时导致的失败问题。
7. 支持 column string64,以避免在 string size 溢出 unit32 时 Join 失败的问题
在某些情况下,字符串的大小可能会超过 unit32 的限制,支持string64类型可以确保字符串 JOIN 操作的正确执行。
8. 允许 Hadoop 用户创建 Paimon Catalog
允许具有权限的对应 Hadoop 用户来创建 Paimon Catalog。
9. 修复 function_ipxx_cidr 函数与常量参数的问题
修复了function_ipxx_cidr函数在处理常量参数时可能出现的问题,保证函数执行的正确性。
10. 修复使用 HDFS 进行还原时的文件下载错误
解决了在使用 HDFS 进行数据还原时遇到的“failed to download”错误,确保了数据恢复的正确性和可靠性。
11. 修复隐藏列相关的列权限问题
在某些情况下,隐藏列的权限设置可能不正确,此修复确保了列权限设置的正确性和安全性。
12. 修复在 K8s 部署中 Arrow Flight 无法获取正确 IP 的问题
此修复解决了在 Kubernetes 部署环境中 Arrow Flight 无法正确获取 IP 地址的问题。