计算机组成原理(4)-----Cache的原理及相关知识点(1):https://developer.aliyun.com/article/1511472
4.替换算法
Cache很小,主存很大,而每次被访问的主存块,一定会被立即调入Cache,如果Cache满了怎么办?
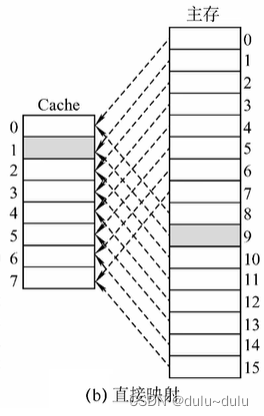
(1)对于全相联映射
对于这种方式,每一个主存块,可能被放到Cache中的任何块中,所以只有Cache完全满了才需要替换需要在全局选择替换哪一块
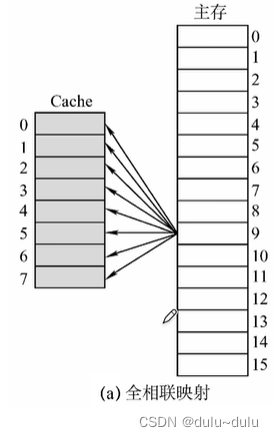
(2)对于直接映射
对于这种方式,某一主存块会被放到Cache中的指定位置,所以如果对应位置非空,则毫无选择地直接替换
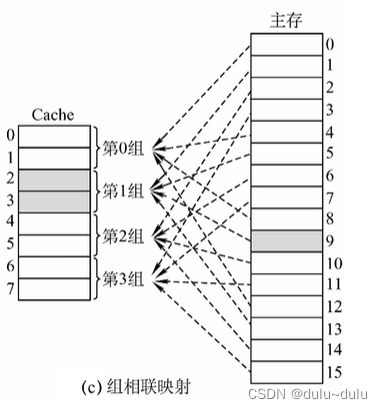
(3)对于组相联映射
对于这一方式,某一主存块会被放到固定分组中的任意位置,分组内满了才需要替换,需要在分组内选择替换哪一块
所以替换算法只会被应用到全相联映射与组相联映射中,对于直接映射,无需考虑替换算法,这里以全相联映射为例,讲解以下替换算法:
(1)随机算法(RAND)
随机算法(RAND,Random)----若Cache已满,则随机选择一块替换
设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1, 2,3,4,5}
如图所示,每访问一个主存块,都需要将其从主存调入Cache,由于前4次访问,Cache都未被装满,所以不需要进行Cache替换

由于1,2号主存块已经在Cache中,所以Cache命中

现在访问5号主存块,就需要立即将5号主存块调入Cache,根据随机算法的规则,则随机选择一个Cache块替换,其他同理:

随机算法----实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定
(2)先进先出算法(FIFO)
先进先出算法(FIFO,First In First Out)--若Cache已满,则替换最先被调入Cache 的块
设总共有4个Cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5, 1, 2, 3, 4, 5}
前面与随机算法同理:

接下来访问5号主存块,由于5号主存块没有在Cache中,所以5号主存块会被调入Cache,根据先进先出的规则,由于最先被调入的是1号主存块,所以1号主存块先被淘汰,将5号主存块放入1号主存块原来放的Cache中:

现在在Cache中,最先调入Cache的是2号主存块,所以淘汰2号主存块,将1号主存块放入到2号主存块原来放的Cache中,其他以此类推:

先进先出算法----实现简单,最开始按#0#1#2#3(Cache行号递增的方式)放入Cache,之后轮流替换#0#1#2#3
FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的,同时先进先出算法会出现抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入)
(3)近期最少使用(LRU)
近期最少使用算法(LRU,Least Recently Used)----为每一个Cache块设置一个"计数器",用于记录每个Cache块已经有多久没被访问了。当Cache满后替换“计数器”最大的
如下图所示,接下来需要将5号内存块调入Cache,那么从5这个位置往前看,依次为2,1,4,3,所以最久未被访问的是3号内存块,替换3号内存块,调入5号内存块

所以若需要将某一内存块调入Cache,就从这一内存块往前看,替换最久未被访问的内存块
若使用近期最少使用算法,每个Cache行不仅需要记录标记和有效位,还必须记录"计数器"
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
例如,刚开始1号主存块被调入Cache中,没有命中,并且依然有空闲行,所以1号主存块被调入0号Cache中,那么将0号Cache行的计数器置0,因为其他行也空闲,所以不需要加1;
同理,2号主存块调入到1号Cache中,那么将2号Cache的计数器置0,并且将0号Cache加1,依次类推:

接下来访问1号内存块,由于Cache命中,那么会把命中的行计数器清零,比其更低的计数器加1,其余不变

2号内存块同理:

接下来5号内存块会替换"计数值最大"的行,新装入行的块计数器置0,其余全部加1

接下来访问1号内存块,Cache命中,所以把命中的行的计数器清零,比其低的计数器加1,其余不变

在这里我们同样可以把3+1=4,但是这是没有必要的,因为设置计数器是想通过判断值的大小,选择要替换的内存块,要替换"计数器"最大的,所以就算不加+1,3也是最大的
注:由于Cache填满前计数的起点是不同步的,接下来填满后,若要替换,也是一次替换一个内存块,所以一定不会有相同的计数

计数器比2大的数值不变的好处有以下两个:
①当只有4个Cache行时,计数器的值只可能出现0,1,2,3,Cache块的总数=2^n,则计数器只需n
位。且Cache装满后所有计数器的值一定不重复
②若以下图中,CPU一直访问内存块1,如果不设置这一机制,则计数器一直+1,可能导致计数器溢出

其他同理,最终得到:

LRU算法----基于"局部性原理",近期被访问过的主存块,在不久的将来也很有可能被再次访问,因此淘汰最久没被访问过的块是合理的。LRU算法的实际运行效果优秀,Cache命中率高。
但若被频繁访问的主存块数量>Cache行的数量,则有可能发生“抖动”,如:{1,2,3,4,5,1,2,3,4,5,1,2...}
(4)最近不经常使用(LFU)
最不经常使用算法(LFU,Least Frequently Used )----为每一个Cache块设置一个“计数器”,用于记
录每个Cache块被访问过几次。当Cache满后替换“计数器”最小的
① 新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行 
② 接下来访问5号主存块,需要替换"计数器"最小的内存块,若有多个计数器最小的行,可按行号递增或FIFO策略进行选择,例如可以优先淘汰行号较小的块或淘汰先进的内存块,所以这里替换2号Cache行中的内存块

这里按照优先淘汰行号较小的块的规则,最终得到:

采用这种算法的话,计数器的取值范围:0~很大的值,那么每个Cache行所对应的计数器,就需要使用较长的位数表示
同时,对于LFU算法---曾经被经常访问的主存块在未来不一定会用到(例如某段时间频繁使用微信视频聊天相关的块,此时相关计数器会增加到很大,若之后不再需要视频聊天,但相关Cache块的计数器已经很大了,所以相关内存块在Cache中的数据副本在短时间内不会被淘汰),并没有很好地遵循局部性原理(最不经常使用算法可能会记录下全局的访问频率),因此实际运行效果不如LRU
5.Cache写策略
CPU修改了Cache中的数据副本,如何确保主存中数据母本的一致性?
(1)写命中
•写回法
写回法(write-back)----当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出(淘汰)时才写回主存
块被换出(淘汰)时才写回主存

为了让硬件能够区分哪个Cache块被修改过,哪个没有被修改过,需要为每个Cache行增加一个脏位,当一个Cache行的数据块被修改,需要将这一Cache行对应的脏位置1 ,这样当我们淘汰某一Cache行时,
就可以判断这一Cache行是否需要被写入主存,而写回主存的什么位置,则可以通过标记判断

这种方式减少了访存次数,但存在数据不一致的隐患。
•全写法
全写法(写直通法,write-through)----当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
当Cache行中的数据被淘汰时,也不需要写回主存中,因为数据随时都是保持一致的
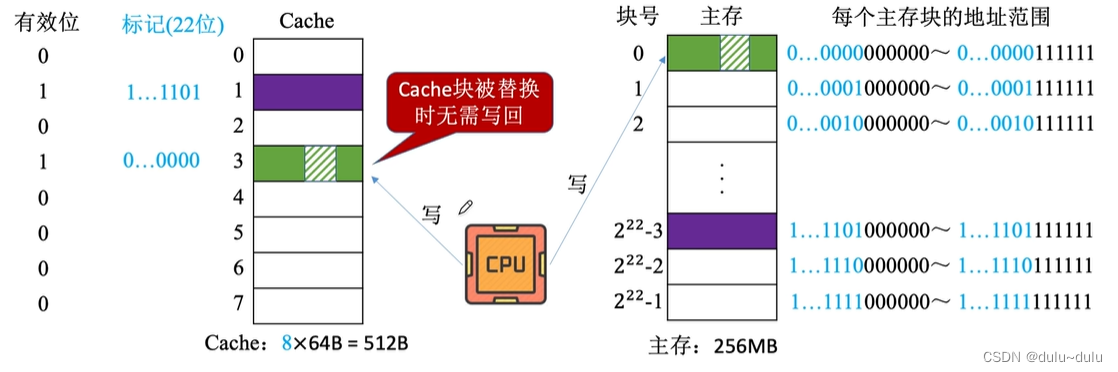
采用这种方法,CPU每次进行写操作时,除了访问Cache,也需要访问主存,访存次数增加,速度变慢,通常增加写缓存(write buffer),写缓存是用SRAM制造的,对写缓冲的读写会比较快
当CPU对某一地址的数据进行写操作,并且这一地址命中时,CPU首先会向Cache中写入这些数据,另外CPU也会向写缓冲中写入相应的数据,由于写缓存是由SRAM实现的,所以写入写缓冲要比写入主存更快

接下来CPU就可以做其他事了,在这期间,写缓冲会在专门的控制电路控制下逐一写回

使用写缓冲,CPU写的速度很快,若操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞
(2)写不命中
•写分配法
写分配法(write-allocate)---当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。(也就是主存的数据不动,CPU只是修改了Cache中的副本) 通常搭配写回法(也就是Cache块被淘汰后,才把一整块的数据同步回主存)使用。

•非写分配法
非写分配法(not-write-allocate)---当CPU对Cache写不命中时只写入主存,不调入Cache。
搭配全写法(当CPU对Cache写命中时,必须把数据同时写入Cache和主存)使用。

用这种方法,只有CPU进行"读"操作未命中时,才会把相应主存块调入Cache,而如果是"写"操作未命中时,只写入主存,不调入Cache
补充:
现在计算机常采用多级Cache
离CPU越近的速度越快,容量越小,离CPU越远的速度越慢,容量越大

对于上图,L2 Cache保存的是一小部分主存数据的副本,而对于更高级的Cache,则保存的是更低一级Cache的一部分数据的副本,所以Cache之间也存在数据一致性的问题
① 各级Cache之间常采用"全写法+非写分配法"
② Cache--主存之间常采用"写回法+写分配法"