前言
在平时写文章的过程中,相信大多数同学用的都是 markdown 编辑器, markdown 可以理解成为一种标记,通过一些标准的规则去规定某一个字符串是某种特定的类型。而在预览的时候,我们还需要将 markdown 转成一种易于阅读的、带有一定样式的文本,在浏览器端那就是html字符串,然后再加上对应的主题样式,我们就可以把干巴巴的 markdown 字符串变成漂亮的富文本。
在跟一位做 markdown 编辑器的前辈聊天的时候,听他提起其实可以用抽象语法树去解析 markdown ,那时候感觉挺奇妙的,因为在我的认知里一般都是使用正则去匹配 markdown 。下来自己就去找了一下相关的实现,发现已经有一个库做的相当成熟——remark。
准备工作
remark 是一个基于插件转换 markdown 的工具,这里我们可以来astexplorer这个站点大概看一下 markdown 的抽象语法树长成啥样。 
由上图可以看到,不同的 markdown 节点会对应不同的节点对象,每一个对象用 type 去区分,比如标题是 heading 、列表是 list ;不同的节点对象里面会有一些专属的属性,比如 heading 中用 depth 去表示这是几级标题。一级标题 depth 的值就为 1 ;节点对象里面还有一个 children 属性,表示它的子节点。这样就构成了一个树的结构,这里我们称之为 Markdown AST ,或者叫做 MDAST ,意为 markdown 抽象语法树。
那么基于这棵抽象语法树,我们就可以尝试把它转为富文本。工程目录如下:
- src - main.js - node.js - editor.js - parser.js - package.json - webpack.config.js
分别介绍一下 src 目录下几个文件的作用:
main.js:入口文件node.js:节点生成文件editor.js:编译器主入口parser.js:节点解析文件
使用 webpack 来构建整个工程,这里使用的 webpack 配置很简单,如下:
const HtmlWebpackPlugin = require('html-webpack-plugin') const { resolve } = require('path') module.exports = { mode: 'development', entry: './src/main.js', output: { path: resolve(__dirname, './dist'), filename: 'js/[name].[hash].js', clean: true }, module: { rules: [ { test: /\.css$/, use: ['style-loader', 'css-loader'] }, ] }, plugins: [ new HtmlWebpackPlugin() ] }
对于 markdown 解析成抽象语法树,这里主要会用到三个库,分别是:
- unified:理解为一个组合器,把各种解析器组合起来
- remark-parse:解析抽象语法树的主入口
- remark-gfm:解析插件,可以解析一些比较复杂的语法,比如表格等
语法转换
有了上述的准备之后,我们就可以来开始着手将 markdown 进行转换。我们希望可以如下使用:
//main.js import { render } from "./editor" const str = ` # 123 *111* 10. A 11. B 12. C ` render(str)
render 函数就会把 markdown 字符串渲染成富文本并插入到页面里。这里 render 的输入是 markdown 字符串,输入是富文本,所以整个的流程是 markdown->ast->html 。
解析器
先利用 remark 这个库实现一个 markdown 到 ast 的解析器,下面的逻辑就是对库的调用而已,没有什么需要特别去讲的地方
//parser.js import { unified } from 'unified' import remarkParse from 'remark-parse' import remarkGfm from 'remark-gfm' const parser = unified().use(remarkParse).use(remarkGfm) const parse = (str) => { const result = parser.parse(str) result.type = 'root' return result } export { parse }
唯一有所不同的是把 remark 解析的结果加多一个 type 属性,统一所有节点的数据结构,解析结果的数据结构如下:

渲染
刚才我们看到了 AST 的结构,对于不同类型的节点会用 type 去区分,对于一个节点来说,我们要处理的是节点对应的属性以及节点的子节点,剩下的孙节点,以及节点的父节点该如何处理,在该节点中无需考虑。也就是说我们只要处理好当前节点就行,那么对于子节点,就使用一个循环处理,把每一个子节点当成一个“当前节点”。所以我们需要实现一个 create 函数,如下:
const create = (parent, nodes, options = {}) => { if (Array.isArray(nodes)) { nodes.forEach((node, index) => { createNode(parent, node, Object.assign({}, options, { index })) }) } }
它接收三个参数,一个是父元素 parent ,注意这个父元素是一个真实的 DOM 节点,还有子节点 nodes ,以及一些拓展参数 options , createNode 就是针对某一个节点类型去进行创建。把上面的解析与转换结合,代码如下:
const render = (str) => { const node = parse(str) const rootEl = document.createElement('div') rootEl.className = 'markdown-body' node.el = rootEl create(rootEl, node.children) document.body.appendChild(rootEl) }
上述代码主要干了这么几件事情:
- 将
markdown字符串解析成抽象语法树,解析的时候将结果处理了一下,也可以把解析结果看成一个根节点 - 创建一个容器
DOM,将抽象节点解析成为DOM节点,并插入容器DOM body中插入这个容器DOM
那么大致的框架我们已经搭完了,接下来要做的才是真正把虚拟节点变成 DOM 节点——即实现 createNode 函数。
派发中心
上面我们已经分析过这件事情,我们在处理的时候,只需要专注于处理某一个特定的节点,至于节点的子节点,递归调用 create 函数就行,所以我们这里要实现一个派发中心—— createNode ,根据节点不同的类型,使用不同的函数去处理,生成对应的 DOM 节点,最后再把结果整合。我整理了一下,常用的节点有以下几种:
heading: 标题,h1~h6text: 文本内容paragraph: 段落,p标签emphasis: 斜体,em标签strong: 粗体,strong标签inlineCode: 行内代码,用span标签对应code:代码块,code标签delete: 删除线,del标签thematicBreak: 分割线,hr标签,blockquote: 引用,blockquote标签,link:链接,a标签,image: 图片,img标签,list: 列表,ol或者ul标签,listItem: 列表项,li标签,table: 表格,table标签,tableRow: 表格行,tr标签,tableCell: 单元格,td标签
所以 createNode 的具体实现如下:
const createNode = (parent, node, options = {}) => { const { type } = node let result // 将节点类型与处理函数一一对应 const typeFuncMap = { heading: heading, text: text, paragraph: paragraph, emphasis: emphasis, strong: strong, inlineCode: inlineCode, delete: del, thematicBreak: thematicBreak, blockquote: blockquote, link: link, image: image, list: list, listItem: listItem, table: table, tableRow: tableRow, tableCell: tableCell } if (typeFuncMap[type]) { result = typeFuncMap[type]({ node, options, parent }) } if (result) { node.el = result node.parent = parent parent.appendChild(result) } }
由上面的代码可以看到, createNode 主要做了下面几件事情:
- 将节点类型与处理函数一一对应,根据具体的类型,调用具体的派发函数
- 将
DOM元素、父元素挂在到对应的节点上 - 将生成的结果挂载到父元素
派发函数
下面挑几个派发函数来看看具体的实现,因为大部分的派发函数的处理过程都不会很长,实现起来也大同小异,所以就不一一贴出来了,每一个派发函数的具体实现思路都是:
- 创建对应的
DOM节点,比如link类型就是创建a标签、image类型就是创建img标签 - 处理属性,比如
a标签的href属性,image标签的url属性、title属性等等 - 调用
create函数,继续创建子节点
heading
下面这个就是标题的派发函数,根据 depth 去生成具体的标签,如果 depth 为 2 ,那么就生成 h2 标签,生成完之后, heading 这个类型就处理结束了,接下来就递归调用 create 继续去生成子节点。
const heading = ({ node }) => { const { depth } = node const head = document.createElement(`h${depth}`) create(head, node.children) return head }
list
列表会分为有序列表和无序列表,所以我这里将它们的处理分别实现。创建 ol 或者 ul 标签,有序列表还会有一个 start 属性,表示列表项开始的值。
const list = ({ node }) => { const { ordered } = node return ordered ? orderList({ node }) : unorderList({ node }) } const orderList = ({ node }) => { const { start } = node const ol = document.createElement('ol') ol.setAttribute('start', start) create(ol, node.children) return ol } const unorderList = ({ node }) => { const ul = document.createElement('ul') create(ul, node.children) return ul }
列表项的处理也不复杂,注意这里有一个候选框的语法,表示的是下面的这种样式 
const listItem = ({ node }) => { const li = document.createElement('li') const { checked } = node if (checked !== null) { const input = document.createElement('input') input.setAttribute('type', 'checkbox') input.setAttribute('disabled', true) if (checked) { input.setAttribute('checked', checked) } li.style = 'display:flex' li.appendChild(input) } create(li, node.children) return li }
table
表格的处理也是分的比较细,分成了三个派发函数。这里需要注意的一点是 align 属性,表示表格的对齐方式。这个属性是在 table 这个节点中,但是使用的时候是在对应的 td 节点中使用。所以利用 create 函数的第三个拓展属性将 align 透传下去,而 create 在循环的时候也会将当前节点的下表 index 透传下去,所以在 td 节点的处理中就可以拿到对应的对齐方式,进而来设置。
const table = ({ node }) => { const { children, align } = node const table = document.createElement('table') create(table, children, { align }) return table } const tableRow = ({ node, options }) => { const tr = document.createElement('tr') create(tr, node.children, options) return tr } const tableCell = ({ node, options }) => { const td = document.createElement('td') const { align, index } = options const tableCellAlign = align[index] td.setAttribute('align', tableCellAlign) create(td, node.children) return td }
小结
在实现了这一套解析+转换之后,一起来看看渲染后的效果如何吧,比如我们渲染一个这样的 markdown 字符串:
# hello *1* \`**2**\` ***_xx_*** ~~***11***~~ --- > 这是一个引用 \`\`\` var a = 1 \`\`\` - 1 - 2 - [x] 选中复选框 10. A 11. B  这是一个链接 [百度](https://baidu.com/ "百度的网址") |**表头**|*表头*|~~***表头***~~| |:-|:-:|-:| |左对齐|居中|右对齐|
为了让效果稍微好看一点,我引入了一个 markdown 主题——github-markdown-css,可以看到渲染效果是符合预期的 
拓展属性
上面我们已经实现了基本的 markdown 转富文本,但是可能在一些场景下,我们还希望能够设置文字的大小、颜色,图片的大小等功能。所以我这里做了一些额外的处理,这些都不是 markdown 的标准语法,只是我们根据个人需要所作出的一些拓展功能而已,实现这些拓展功能,其实也就是在派发函数上做文章。
链接
对于链接,有的情况下也许希望能控制它在新窗口打开,或者在当前窗口打开,即 target 属性。所以我们为链接加上 target 属性的额外配置。这里采用这种语法:[链接描述](https://baidu.com?target=_blank),链接后面加一个 target 参数,然后在派发函数的时候进行解析。代码如下:
const parseUrlSearch = (url) => { const urlObj = new URL(url) let search = urlObj.search.substring(1) search = search.split('&') const obj = {} search.forEach(item => { if (item) { const arr = item.split('=') const [key, value] = arr obj[key] = value } }) return obj } const link = ({ node }) => { const link = document.createElement('a') const { title, url } = node link.setAttribute('href', url) link.setAttribute('title', title ? title : '') try { const res = parseUrlSearch(url) if (res.target) { link.setAttribute('target', res.target) } } catch (e) { } create(link, node.children) return link }
parseUrlSearch 是一个工具函数,用于获取一些 url 后面的 search 参数,这里获取到对应的 target 属性之后,对 el 进行设置即可。
[这是一个在新标签页打开的链接](https://baidu.com?target=_blank)

图片
对于图片来说,我们希望能够设置他的宽高,居中位置等属性。这里也是通过图片 URL 后续的参数配置的方式来实现。实现过程和用法与链接实现大同小异。
const image = ({ node, parent }) => { const { alt, url } = node const img = document.createElement('img') img.setAttribute('alt', alt) img.setAttribute('src', url) try { const res = parseUrlSearch(url) const { width, height, align } = res if (width) { img.setAttribute('width', width) } if (height) { img.setAttribute('height', height) } if (align) { parent.style.textAlign = align } } catch (e) { } return img }
对于居中方式的实现,这里的实现方式是对图片的父元素设置 tetAlign 属性。因为图片的解析结果是类似于<p><img/></p>这样子的,所以采取了这种方式去实现。下面这张图片是我在网上找的,仅做演示使用,如有侵权我会马上删除。


文本
对于文本,我们做三个额外的处理:大小、颜色、以及背景颜色。在这个处理的位置上,去实现一个 remark 插件应该才是最正确的解法,但是我对 remark 的研究尚浅,所以就还没去走这个实现方式,希望以后有机会能补上,这里我还是使用正则去匹配,拓展写法是这是红色{"color":"red"}。
先来说一下这里的大致实现,用正则去匹配文本字符串,提取对应的特征以及特征值,提取到之后重新替换拼接字符串,具体的可以看代码。
const text = ({ node }) => { const reg = /\{([A-Za-z0-9:\"\,])+\}/g //正则表达式 let regRes let replaceArr = [] // 用于存放是否有特征替换 let value = node.value let index = 0 while (regRes = reg.exec(value)) { //如果匹配到了特征 try { let str = regRes[0] let res = JSON.parse(str) //解析成对象 let style = '' Object.keys(res).forEach(key => { const value = res[key] if (key === 'color') { style += `color:${value};` } if (key === 'font') { const fontSize = isNaN(Number(value)) ? value : `${value}px` style += `font-size:${fontSize};` } if (key === 'bgColor') { style += `background-color:${value};` } }) // 以处理`红色{"color":"red"} 普通颜色`这个字符串为例,这里的replaceKey就是`红色{"color":"red"}` let replaceKey = value.substring(index, regRes.index + str.length) // 而span的值是`<span style="color:red">红色</span>` const span = `<span style="${style}">${value.substring(index, regRes.index)}</span>` // 推进数组等待后续替换 replaceArr.push({ key: replaceKey, value: span }) index = regRes.index + str.length } catch (e) { } } let content // 如果没有特征替换,直接根据value创建一个文本节点 if (replaceArr.length === 0) { content = document.createTextNode(value) } else { content = document.createElement('span') // 将`红色{"color":"red"} 普通颜色` 替换成 `<span style="color:red">红色</span> 普通颜色` replaceArr.forEach(({ key, value: content }) => { value = value.replace(key, content) }) content.innerHTML = value } // 返回结果 return content }
大致实现如上,代码加了对应注释。具体使用方式如下:
## 红色{"color":"red"} ### 30px {"font":30} *粗体绿色背景{"bgColor":"green"}* 红色 {"color":"red"}
渲染效果如下: 
局部更新
上面我们已经实现了基本语法的转换以及一些拓展语法,算得上是一个可用的 markdown 转富文本的编译器了。但是如果我们把它用作实时的转换,会不会有问题呢?简单实现了一个 markdown 编辑器,左侧是编辑区域,右侧是预览区域,效果如下: 
很明显可以看到,我们编辑了一点内容,整一片预览区域的 DOM 都会全部重新渲染,如果对于一个很大的文档来说,这样做无疑效率是十分低下的。再回头想想我们的抽象语法树,是不是很像虚拟 DOM 呢?用数据去一一对应具体的 DOM 节点。因为虚拟 DOM 我们已经有了,这里我们自然而然的想到可以参照 Vue 、 React 等框架,去采用 diff 算法实现局部更新,而不是一整个的替换。首先改造一下 render 函数如下:
let oldNode = null const render = (str) => { const node = parse(str) if (!oldNode) { init(node) } else { node.el = oldNode.el update(oldNode, node) } oldNode = node }
如果没有 oldNode ,说明这是首次渲染,则走挂载逻辑;如果有,则是更新,走 update 逻辑。所以接下来需要实现的 update 是,对比新老两个节点,找出差异并更新到真实的 DOM 上。抽象语法树与虚拟 DOM 是个很像的东西,但不完全相同,在虚拟 DOM 的比较中,属性不会影响 DOM 节点的增删,但在这里不同,这里需要通过 type+属性 才能判断具体的 DOM 类型,比如有序列表和无序列表, type 都是 list ,而 ordered 属性一个是 ul ,一个是 ol 。
属性处理
update 方法也是递归调用的,如果 type 不是文本类型,能进到 update 方法,我们则认为这个节点对应的 DOM 节点已经是复用的, update 里只需要更新节点的属性,以及进行子节点的比对即可。如果是文本节点或代码块且新旧 value 不同,则直接替换。整理一下各种节点对应的属性以及如何替换
list:替换有序列表的start属性image:替换alt属性link:替换title属性table:table的处理比较特殊,用到了setTimeout,因为这里主要处理align属性,而align属性又是运用在它的子节点的,所以等它的子节点对比结束完之后再去处理。
const update = (oldNode, node) => { if (oldNode === node) return node.el = oldNode.el node.parent = oldNode.parent const el = node.el const parent = oldNode.parent if (node.type !== 'text' && node.type !== 'code') { //更新属性 const { type } = node if (type === 'list') { if (oldNode.start !== node.start) { el.setAttribute('start', node.start) } } if (type === 'image') { if (oldNode.alt !== node.alt) { el.setAttribute('alt', node.alt) } } if (type === 'link') { if (oldNode.title != node.title) { el.setAttribute('title', node.title) } } if (type === 'table') { if (JSON.stringify(oldNode.align) !== JSON.stringify(node.align)) { setTimeout(() => { const { align } = node if (node.el) { const trs = Array.from(node.el.querySelectorAll('tr')) trs.forEach(tr => { const tds = Array.from(tr.querySelectorAll('td')) tds.forEach((td, tdIndex) => td.setAttribute('align', align[tdIndex])) }) } }) } } updateChildren(el, oldNode.children, node.children) } else if (oldNode.value !== node.value) { // 替换节点 el.innerHTML = createElement(node) } }
一起来看看这样处理之后的效果: 
可以看到所有的节点都是复用的,仅仅是对 title 属性做了变更而已。
子节点处理
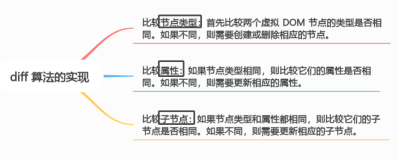
对单个节点处理完之后,就需要对它们的子节点进行处理。对新老子节点处理的时候,准循以下三条规则:
- 有老节点,无新节点——直接删除所有的老节点
- 有新节点,无老节点——直接创建所有的新节点
- 新老节点都有——进入
diff
const updateChildren = (parent, oldCh, newCh) => { if ((!oldCh && !newCh) || (oldCh.length === 0 && newCh.length === 0)) { return } if (oldCh.length > 0 && newCh.length > 0) { // 比对 pathChildren(parent, oldCh, newCh) } else if (newCh.length > 0) { // 增添children newCh.forEach(node => { const el = createElement(node) parent.appendChild(el) }) } else { // 删除children parent.children.forEach(child => { parent.removeChild(child) }) } }
这里的子节点 diff 参考的是 Vue2 的处理——双端比对。大概讲一下双端比对 diff ,首先初始化四个指针:旧头、旧尾、新头、新尾,然后进行以下操作:
- 比对旧头新头,如果一样,则进行节点比对(即
update函数),且两个指针向右移动,否则进入下一步 - 比对旧尾新尾,如果一样,则进行节点比对,且两个指针向左移动,否则进入下一步
- 比对旧头新尾,如果一样,则进入节点比对,且将旧头对应的
DOM移动到旧尾对应的DOM的后面,旧头向右移,新尾向左移,否则进入下一步 - 比较新头旧尾,如果一样,则进入节点比对,且将旧尾对应的
DOM移动到旧头对应的DOM的前面,新头向右移,旧尾向左移动,否则进入下一步 - 将还没比对的新节点一个个拿出来,去还没比对的旧节点中找,如果找不到,则创建新节点,如果找到了旧移动位置
在上面五步做完之后,把旧节点还没比对的删除,把新节点还没比对的创建,那么整个子节点数组的 diff 也就完成了。实现代码如下:
const pathChildren = (parent, oldCh, newCh) => { let oldStartIdx = 0 let newStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx] let vnodeToMove, refElm while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (!oldStartVnode) { oldStartVnode = oldCh[++oldStartIdx] } else if (!oldEndVnode) { oldEndVnode = oldCh[--oldEndIdx] } else if (sameNode(oldStartVnode, newStartVnode)) { update( oldStartVnode, newStartVnode, ) oldStartVnode = oldCh[++oldStartIdx] newStartVnode = newCh[++newStartIdx] } else if (sameNode(oldEndVnode, newEndVnode)) { update( oldEndVnode, newEndVnode, ) oldEndVnode = oldCh[--oldEndIdx] newEndVnode = newCh[--newEndIdx] } else if (sameNode(oldStartVnode, newEndVnode)) { update( oldStartVnode, newEndVnode, ) // move right parent.insertBefore(oldStartVnode.el, oldEndVnode.el.nextSibling) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] } else if (sameNode(oldEndVnode, newStartVnode)) { // moved left update( oldEndVnode, newStartVnode, ) parent.insertBefore(oldEndVnode.el, oldStartVnode.el) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] } else { // 这里在源码中会有一个构建key map的操作,但是我们这里没有唯一的key,有index来做key可能会有误判,所以索性就不做这段处理了 const idxInOld = findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) if (idxInOld === null) { // New element createNewNode(parent, newStartVnode, oldStartVnode.el) } else { vnodeToMove = oldCh[idxInOld] if (sameNode(vnodeToMove, newStartVnode)) { update( vnodeToMove, newStartVnode, ) oldCh[idxInOld] = undefined parent.insertBefore(vnodeToMove.el, oldStartVnode.el) } else { // same key but different element. treat as new element createNewNode(parent, newStartVnode, oldStartVnode.el) } } newStartVnode = newCh[++newStartIdx] } } if (oldStartIdx > oldEndIdx) { refElm = !newCh[newEndIdx + 1] ? null : newCh[newEndIdx + 1].el for (let i = newStartIdx; i <= newEndIdx; i++) { const newNode = newCh[i] createNewNode(parent, newNode, refElm) } } else if (newStartIdx > newEndIdx) { for (let i = oldStartIdx; i <= oldEndIdx; i++) { const el = oldCh[i].el parent.removeChild(el) } } }
在加上diff算法之后,我们再来看看效果: 
可以看到,现在已经可以实现局部更新,性能也会比之前提升不少。
我使用了一个大概生成 1500 个 DOM 的 markdown 字符串去测试,以下是全量更新和局部更新所耗费的时间:

做了几次编辑,可以看到一个全量更新的时间是 13ms 左右,而局部更新的时间时 2ms ,差了6~7倍。
最后
我们平时学习框架,也许是好奇里面的实现远离、也许是为了面试,如果有机会的话,我们也可以把框架里面那么优秀的思想以及处理拿过来自己的业务中用,那也是一件十分有趣的事情。如果你觉得本文有意思或者对你有帮助的话,点个赞再走吧~也期待你在评论区与我留言交流