先给我说说什么是主从复制吧
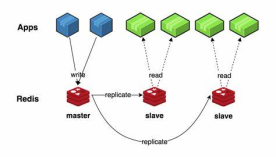
答: 主从复制就是将主节点(master)的数据复制到从节点(slave),让多个节点承载用户的请求。
主从复制具备以下几个特点:
1. 数据冗余:主节点的数据都会同步到从节点上,所以多个节点都会有相同数据,从而实现数据冗余。 2. 故障恢复:主节点出现故障后,从节点可以继续承载用户的请求,做到服务上的冗余。 3. 负载均衡:主从复制机制实现主节点接收用户写请求,从节点承载用户读请求,对于读多写少的场景,这种机制可以大大提高redis的并发量。 4. 高负载:主从复制+哨兵机制可以实现高负载,这点后文会介绍到。
能不能给我演示一下主从复制
答: 首先我们先来看看一主二仆的配置
创建3个redis配置文件,以笔者为例,名字分别为redis6379.conf、redis6380.conf、redis6381.conf
我们将6379这个端口号的redis作为主节点,配置内容如下:
# 引入redis基本配置,注意这个配置只支持RDB include /root/redis/redis.conf pidfile /var/run/redis_6379.pid port 6379 # 设置RDB文件名 dbfilename dump6379.rdb
从节点以6380,配置如下
# 引入redis基本配置,注意这个配置只支持RDB include /root/redis/redis.conf pidfile /var/run/redis_6380.pid port 6380 dbfilename dump6380.rdb # 作为6379的主节点 slaveof 127.0.0.1 6379
分别启动这几个redis
redis-server /root/redis/conf/redis6379.conf redis-server /root/redis/conf/redis6380.conf redis-server /root/redis/conf/redis6381.conf
完成配置后,我们就可以开始测试了,首先对清空主节点数据,并设置一些值进去
127.0.0.1:6379> flushdb OK 127.0.0.1:6379> set master_key value OK 127.0.0.1:6379>
我们看看从节点是否存在这个key值,可以发现这个值确实存在。
# 可以看到主节点的key来了 [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380 127.0.0.1:6380> keys * 1) "master_key" 127.0.0.1:6380>
再使用命令看看6380,发现其角色也确实是从节点
127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 .... 略
那你能不能给我说说主从复制几个特点
答: 我们一个个点来说吧:
- 从节点挂掉,在启动,数据不会丢失,照样是主节点的从节点
这个点我们也可以拿个例子来展示一下,首先我们可以将从节点挂掉:
# 强制挂掉从节点 [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380 127.0.0.1:6380> SHUTDOWN not connected>
清空数据主节点设置一些新数据,再次启动从节点,可以发现它还是从节点的角色
# 启动 发现数据都在,并且角色也是slave [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6380.conf [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380 127.0.0.1:6380> info replication # Replication role:slave .....略
- 主节点挂了,从节点仍然是从节点,主节点恢复后仍然是主节点。
这个例子,首先我们也是需要将主节点挂掉:
# 强制挂掉主节点 [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli 127.0.0.1:6379> SHUTDOWN not connected>
完成后再次将主节点启动,然后进行操作,发现角色仍然是master,而且进行各种set操作80这个从节点也会同步复制。
# 再次启动主节点,发现key都在并且角色仍然是master,设置一个k2值 [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-server /root/redis/conf/redis6379.conf [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli 127.0.0.1:6379> set key2 v2 OK 127.0.0.1:6379> # 从节点仍然可以收到,说明主节点仍然是6379 [root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380 127.0.0.1:6380> keys * 1) "key2" 2) "master_key" 127.0.0.1:6380>
有了解过薪火相传嘛?能不能也给我说说:
答: 如果大量主节点配合大量从节点,会导致主节点为了同步fork大量子进程同步数据,所以我们可以将部分从节点挂到某部分从节点下面,以此类推,作为"小弟的小弟"
以笔者本次示例为例,我们将81作为80的从节点
# 为了方便,笔者使用命令的形式,读者也可以使用conf文件配置 127.0.0.1:6381> SLAVEOF 127.0.0.1 6380 OK 127.0.0.1:6381>
再次查看80节点,可以看到slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=1,由此可知从节点的从节点配置完成
[root@iZ8vb7bhe4b8nhhhpavhwpZ sbin]# redis-cli -p 6380 127.0.0.1:6380> info replication # Replication role:slave # 6381变为它的从节点 slave0:ip=127.0.0.1,port=6381,state=online,offset=810,lag=1
反客为主配置了解过嘛?
答: 对着从节点键入下面在这段命令就好了
slaveof no one
进阶
能不能给我说说主从复制的原理啊
答: 主从复制有两种模式,我就先来说说全量复制吧,如下图,整体步骤为:
- 从节点向主节点发送同步请求,因为不知道主库的
runID,并且不知道同步的偏移量是多少,所以参数分别为? -1,同步请求的指令为psync - 主库执行
bgsave指令生成rdb指令,将数据发送给从库,从库为了保证数据一致性,会将数据清空,然后加载rdb文件,完成数据同步。在此期间,主库收到的新数据都会被存入replication buffer中。 - 主库会将
replication buffer发送给从库,完成最新数据的同步。

从 Redis 2.8 开始,因为网络断开导致数据同步中断的情况,会采用增量复制的方式完成数据补充。
需要了解的是,当主从同步过程中因为网络等问题发生中断,repl_backlog_buffer会保存两者之间差异的数据,如果从库长时间没有恢复,很可能出现该环形缓冲区数据被覆盖进而出现增量复制失败,只能通过全量复制的方式实现数据同步。
需要一个概念replication buffer,这个缓冲区用于存放用户写入的新指令,完成全量复制之后的数据都是通过这个buffer的数据传输实现数据增量同步。
主服务器不进行持久化复制是否会有安全性问题?
答: 有,假如主节点没有使用RDB持久化,数据没有持久化到磁盘,假如主节点挂掉又立刻恢复了,此时主节点所有数据都丢失了,从节点很可能会因此清空原本数据进而导致数据丢失。
为什么主从复制使用RDB而不是AOF
答: RDB是二进制且压缩过的文件,传输速度以及加载速度都远远快速AOF。且AOF存的都是指令非常耗费磁盘空间,加载时都是重放每个写命令,非常耗时。需要注意的是RDB是按照时间间隔进行持久化,对于数据不敏感的场景我们还是建议使用RDB。
什么是无磁盘复制模式
答: 数据同步不经过主进程以及硬盘,直接创建一个新进程dump RDB数据到从节点。对于磁盘性能较差的服务器可以使用这种方式。配置参数为:
repl-diskless-sync no # 决定是否开启无磁盘复制模式 repl-diskless-sync-delay 5 # 决定同步的时间间隔
为什么会有从库的从库设计
答: 避免为了同步数据给大量从库,fork大量的子进程生成rdb文件进行全量复制导致主进程阻塞。
读写分离及其中的问题
答: 大抵需要考虑以下这些问题:
- 延迟与不一致问题:如果对数据一致性容忍度较低,网络延迟导致数据不一致问题只能通过提高网络带宽,或者通知应用不在通过该节点获取数据
- 数据过期问题,从节点很可能在某一时刻某些过期数据被读取到了,这就会给用户造成很诡异的场景。
- 故障切换问题
- 如果在网络断开期间,
repl_backlog_size环形缓冲区写满之后,是进行增量复制还是全量复制?
答: 分两种情况说:
- 若主库的repl_backlog_buffer的slave_repl_offset已经被覆盖,那么同步就需要全量复制了
- 从库会通过psync命令把自己记录的slave_repl_offset发给主库,主库根据复制进度决定是增量复制还是全量复制。