在当今大数据时代,随着应用规模的不断扩大,传统的单库单表结构已经无法满足应用的需求。分库分表技术应运而生,成为解决海量数据存储和查询的有效手段之一。而Sharding-JDBC作为一款优秀的分库分表中间件,为开发人员提供了便捷而高效的解决方案。本文将深入介绍Sharding-JDBC的基本概念、核心功能以及实际应用场景,帮助读者快速上手并灵活应用于项目中。
什么是Sharding-JDBC?
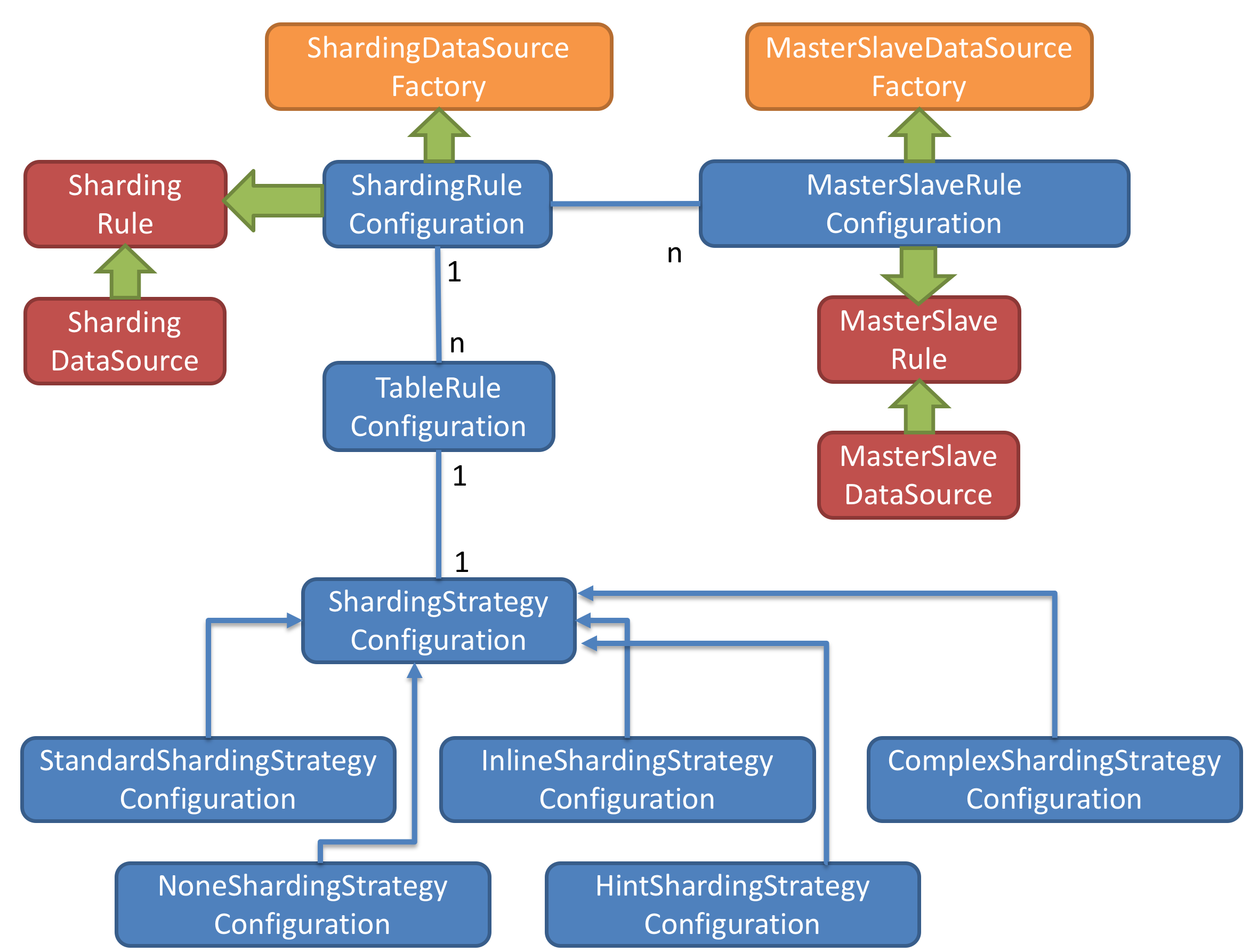
Sharding-JDBC是一款开源的分库分表中间件,它基于Java实现,为用户提供了简单易用的分布式数据库解决方案。通过Sharding-JDBC,开发人员可以将数据水平分片存储到不同的数据库实例中,从而实现数据的水平拆分和负载均衡。
核心功能
1. 数据分片
Sharding-JDBC支持水平分片,可以将数据按照指定的规则分散存储到不同的数据库节点上,实现数据的分布式存储和管理。
2. 透明路由
Sharding-JDBC提供了透明路由功能,对于开发人员而言,可以像操作单一数据库一样对分片数据进行查询和操作,而不需要关心数据的具体存储位置。
3. 分布式事务
Sharding-JDBC支持分布式事务,可以保证跨分片的事务一致性,确保数据的完整性和一致性。
4. 读写分离
Sharding-JDBC支持读写分离,可以将读操作和写操作分发到不同的数据库节点上,提高系统的并发读取能力。
5. 弹性伸缩
由于数据分片存储在多个数据库节点上,Sharding-JDBC可以根据业务需求动态添加或删除节点,实现系统的弹性伸缩。
如何使用Sharding-JDBC?
步骤一:添加依赖
首先,在项目的pom.xml文件中添加Sharding-JDBC的依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
步骤二:配置数据源
在application.properties文件中配置数据源信息,包括数据库连接地址、用户名、密码等:
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
步骤三:配置分片规则
在classpath下添加sharding-jdbc.yml配置文件,配置数据分片规则:
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds0:
...
ds1:
...
sharding:
tables:
user:
actualDataNodes: ds${
0..1}.user_${
0..1}
tableStrategy:
standard:
shardingColumn: id
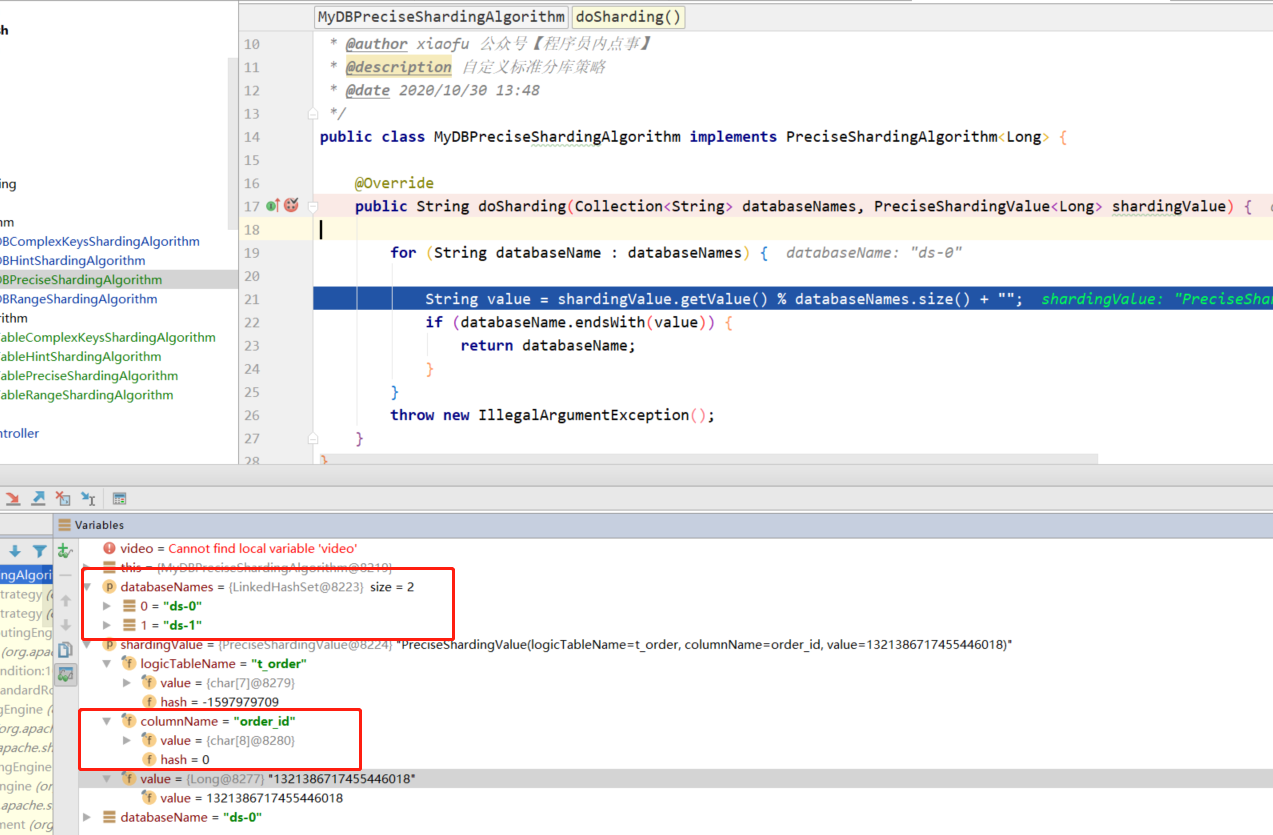
preciseAlgorithmClassName: com.example.algorithm.PreciseShardingAlgorithm
步骤四:编写代码
在代码中编写业务逻辑,使用Sharding-JDBC进行数据操作:
@Autowired
private JdbcTemplate jdbcTemplate;
public void insertUser(User user) {
jdbcTemplate.update("INSERT INTO user (id, name) VALUES (?, ?)", user.getId(), user.getName());
}
public User getUserById(Long id) {
return jdbcTemplate.queryForObject("SELECT * FROM user WHERE id = ?", new Object[]{
id}, new BeanPropertyRowMapper<>(User.class));
}
分表的CRUD操作
在使用 Sharding-JDBC 进行分表操作时,CRUD(Create、Read、Update、Delete)是开发人员最常见的数据库操作之一。
1. 创建数据表
首先,我们需要在数据库中创建分表。假设我们有一个名为 user 的表,我们将其分成了两个子表 user_0 和 user_1。每个子表都包含相同的结构。
CREATE TABLE `user_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `user_1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2. 添加依赖
在项目的 pom.xml 文件中添加 Sharding-JDBC 的依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
3. 配置数据源
在 application.properties 文件中配置数据源信息,包括数据库连接地址、用户名、密码等:
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
4. 编写代码
4.1 插入数据
@Autowired
private JdbcTemplate jdbcTemplate;
public void insertUser(User user) {
String sql = "INSERT INTO user_" + (user.getId() % 2) + " (id, name) VALUES (?, ?)";
jdbcTemplate.update(sql, user.getId(), user.getName());
}
4.2 查询数据
public User getUserById(Long id) {
String sql = "SELECT * FROM user_" + (id % 2) + " WHERE id = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{
id}, new BeanPropertyRowMapper<>(User.class));
}
4.3 更新数据
public void updateUser(User user) {
String sql = "UPDATE user_" + (user.getId() % 2) + " SET name = ? WHERE id = ?";
jdbcTemplate.update(sql, user.getName(), user.getId());
}
4.4 删除数据
public void deleteUserById(Long id) {
String sql = "DELETE FROM user_" + (id % 2) + " WHERE id = ?";
jdbcTemplate.update(sql, id);
}
实际应用场景
电商平台
在电商平台中,订单数据量通常较大,可以通过Sharding-JDBC将订单数据按照用户ID或订单ID进行分片存储,提高系统的并发处理能力。
社交网络
在社交网络应用中,用户数据和关系数据量巨大,可以通过Sharding-JDBC将用户数据和关系数据分散存储到不同的数据库节点上,提高系统的扩展性和性能。
物联网
在物联网领域,设备数据产生速度快,数据量大,可以通过Sharding-JDBC将设备数据按照地理位置或设备类型进行分片存储,实现数据的分布式管理和查询。
总结
通过本文的介绍,读者对于Sharding-JDBC的基本概念、核心功能以及使用方法有了深入的了解。作为一款优秀的分库分表中间件,Sharding-JDBC在分布式数据库领域有着广泛的应用前景,能够为开发人员带来极大的便利和效率提升。希望本文能够帮助读者快速上手并灵活应用Sharding-JDBC于实际项目中,实现数据的分布式存储和管理,提升系统的性能和扩展性。