Loki介绍
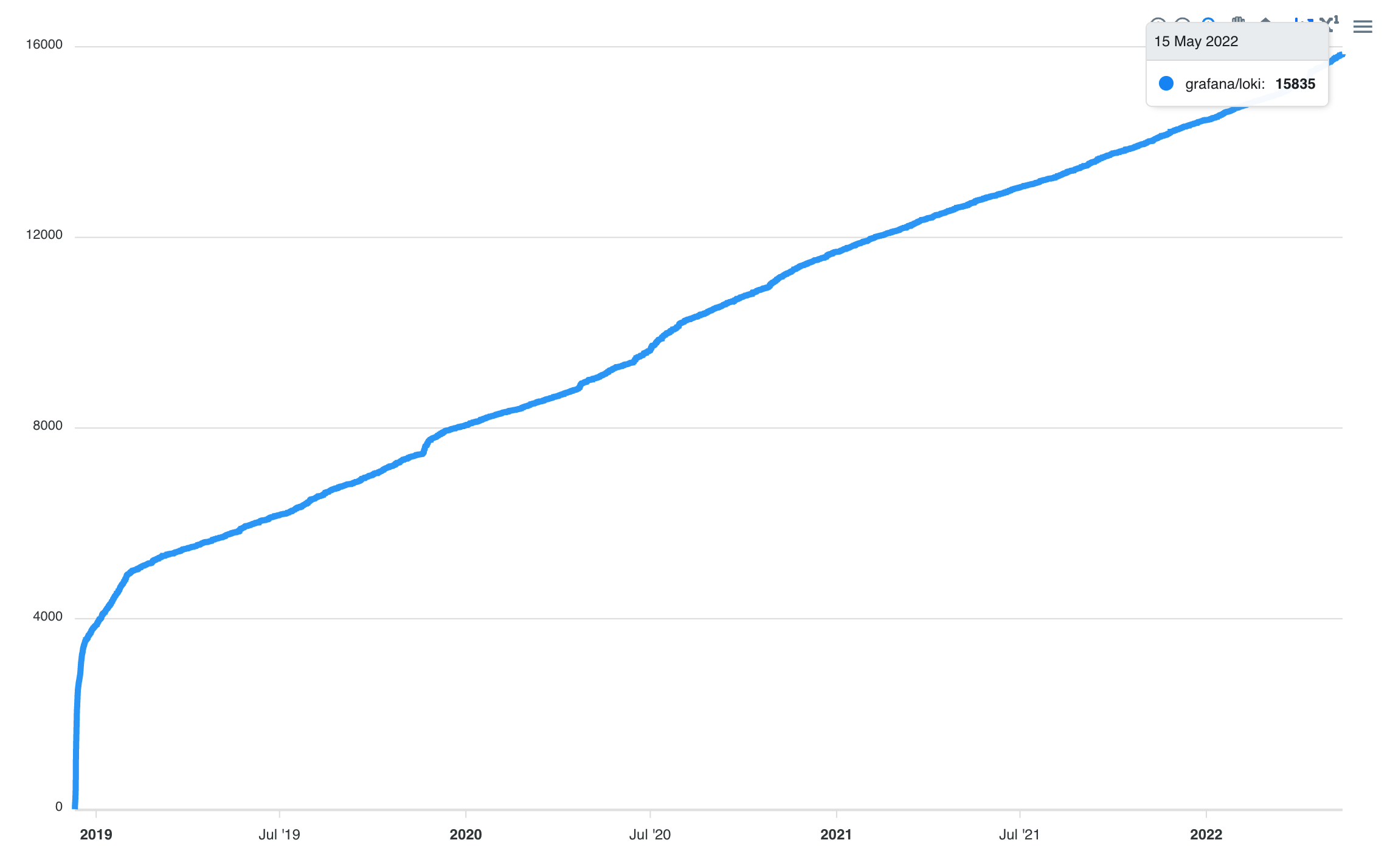
Loki是Grafana Labs在2018年开始研发的一款日志系统,使用的开源协议是AGPLv3,Github Star数目前是15.8k。 过去几年Star的趋势增长稳定。 属于日志存储领域的一颗新星。
Grana Loki的应用架构

采集侧使用 Promtail
Loki核心程序(单一二进制)
外围使用Loki,有Grafana/LogcLi/AlertManager。 其中Grafana提供了轻量级的日志可视化组件对接Loki,使用起来能感受到简洁&轻量
Loki的使用
特点一 便宜的索引方案
官网介绍了一些特点,比如多租户、水平扩展、高可用、云原生、简单易运维,上面的优点好像和其他日志系统比,没有特别的优点。 它的核心优点或者设计理念是什么呢?
我觉得可以引用官网的这句话

在当今日志系统建索引比较稀疏平常的时代,Loki却选择只对Meta类的信息进行索引,这样索引的存储量可以做到非常小,相比于原文。可以忽略不计。在查询的时候,先做Meta数据过滤,再做数据Scan(硬扫),然后计算出结果。

那么,哪些数据算是Loki说的Meta数据呢?常见的有这几类
日志的时间字段
主机名/IP地址
k8s中的pod信息
业务定义的一些类型,往往可以枚举
这些Meta数据可以在采集的时候指定。
特点二 拥抱云时代的存储
Loki在设计产品的时候,充分利用到了云时代的存储。当下Object Storage越来越成为标准化的存储服务,海外的AWS S3、国内 阿里云OSS等都提供了领先的对象存储服务。 作为新生代的日志存储软件,也完全拥抱了云上的存储方案。
据笔者测试,通过简单配置,Loki可以将日志以Gzip压缩的方式存储在对象存储上。 价格低廉
特点三 Promtheus 风格的采集和查询
Grafana 在官网表明,Loki受到了Prometheus的启发。 我们也在两个部分看到了Loki的Prometheus的风格。
采集的组件叫Promtail,配置和Prometheus非常相似
查询的时候,Loki的LogQL和PromQL 如出一辙,比如类似label过滤,指标的agg计算
使用Loki
我们以操作日志作为例子,看一下Loki在日志采集、查询等方面的表现情况。
测试用的机器为aliyun ecs,规格是ecs.c6.6xlarge 24 vCPU 48 GiB
部署Loki
使用当前最新的Loki 2.5.0,docker镜像部署; 我们把loki的日志存储写入放到阿里云OSS上
docker pull grafana/loki:2.5.0
docker run --name loki \
-d -v/tmp/data/:/data/
-v $(pwd):/mnt/config
-p 3100:3100 grafana/loki:2.5.0
-config.file=/mnt/config/loki-config.yaml其中loki的配置文件loki-config.yaml 如下, OSS-*和ACCESS_KEY*部分请改为真实的配置(注意以下配置是单机部署,不适合生产环境,仅供参考)
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
path_prefix: /data/
replication_factor: 1
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
schema_config:
configs:
- from: "2020-10-24"
index:
period: 24h
prefix: index_
object_store: aws
schema: v11
store: boltdb-shipper
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
ingestion_rate_mb: 100
ingestion_burst_size_mb: 100
per_stream_rate_limit: 100MB
per_stream_rate_limit_burst: 200MB
max_query_series: 10000000
max_streams_per_user: 0
max_label_names_per_series: 10000000
storage_config:
boltdb_shipper:
active_index_directory: /data/loki/boltdb-shipper-active
cache_location: /data/loki/boltdb-shipper-cache
cache_ttl: 24h
shared_store: s3
aws:
s3forcepathstyle: false
bucketnames: OSS-BUCKET-NAME
endpoint: OSS-ENDPOINT
access_key_id: ACCESS_KEY_ID
secret_access_key: ACCESS_KEY_SECRET
insecure: true
analytics:
reporting_enabled: falsePromtail采集
我们的日志是json格式的。因为我们希望在采集的时候,对部分字段进行抽取,提取为Label,比如Status字段。
原始日志的内容长这样,单行日志大小约700 Byte
{"User" : "xxx","RequestId" : "xxx", "Status": "xxx" , "Method" : "xxx",...}promtail的采集配置如下
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: system
pipeline_stages:
- json:
expressions:
content:
- labels:
Status: # 将Status字段从json格式抽取出来
- output:
source: content
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/operation.LOG # 指定本机采集的文件路径配置完成后,promtail开始工作。我们的日志产生速率大概是2MB/s。 在这个日志产生,无查询的情况下
promtail cpu0.15core,内存 56MB
loki 0.04core,内存2G
从资源使用率看,采集端和服务端都比较合理。
测试期间遇到的问题,由于开始时promtail采集日志有burst的流量,导致loki被限流。查询相关材料,需要调大loki的相关limit,做了对应的激进调整后,限速消失。
limits_config:
ingestion_rate_mb: 100
ingestion_burst_size_mb: 100
per_stream_rate_limit: 100MB
per_stream_rate_limit_burst: 200MBGrafana日志查询控制台
grafana是用docker部署的是latest版本,当前是v8.5.0
docker run -d -p 3000:3000 --name=grafana8 grafana/grafana:latest在添加完Loki的数据源之后,可以很方便地使用grafana的explore进行日志的查询。

点击 “Log browser” ,可以快速浏览采集上来的label信息
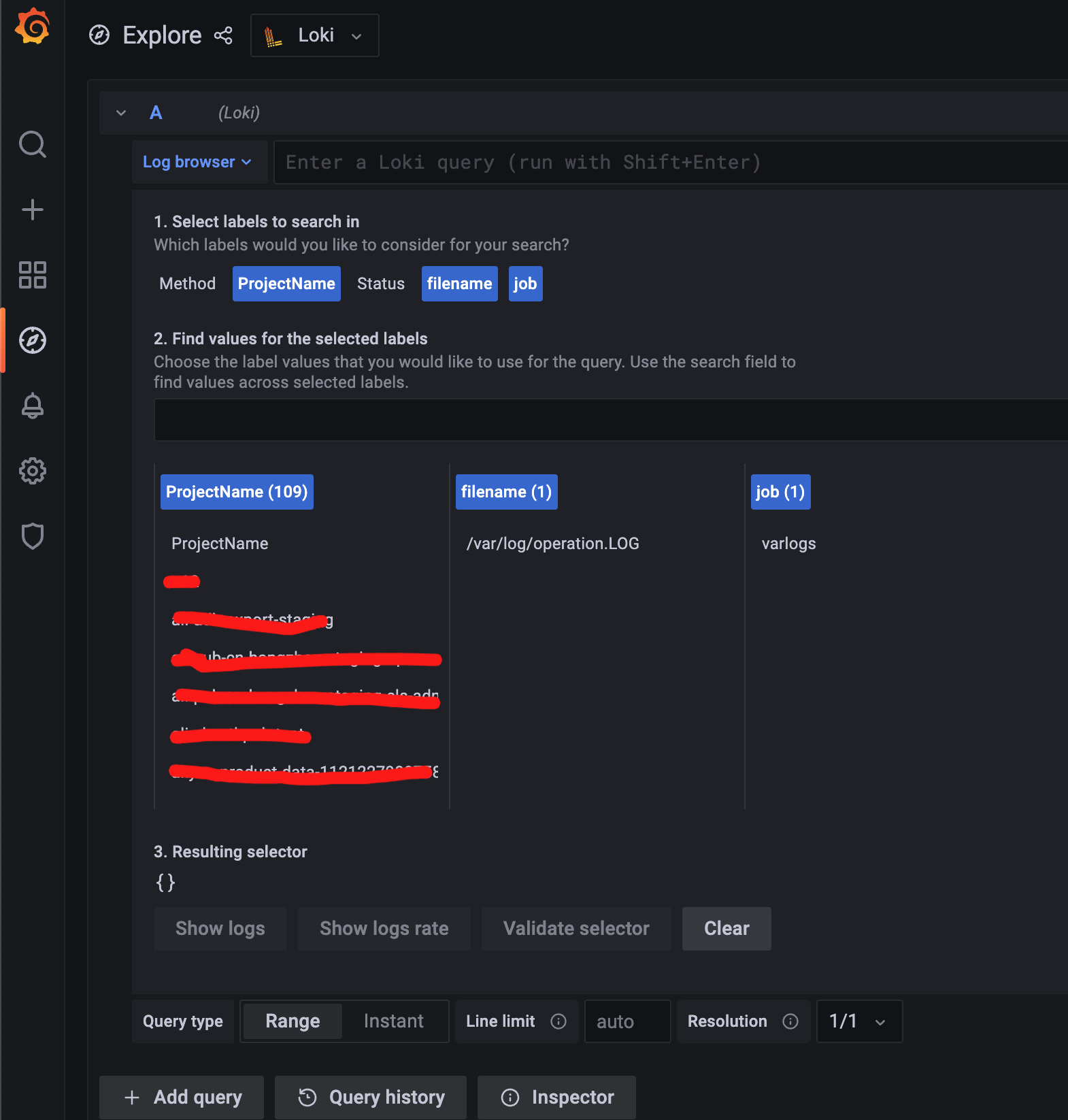
点击某个label值,grafana会自动生成对应的LogQL的查询语句, 即可显示对应查询的结果
上面能显示日志统计的数量,下面是log的具体列表

如果是LogQL的Metric Query,则会显示对应的曲线

Loki的查询DSL
前面提到了Loki的查询语言LogQL支持两种查询类型
Log Queries
Metric Queries
Log Queries 可以理解是日志的行处理,比如日志场景 过滤、格式化、字段提取等能力
举2个例子:
全文匹配一个关键词abc的日志,可以这样写
{filename="/var/log/operation.LOG"} |="abc"对日志做json格式后(我们的日志原文本身就是json,可以直接抽取),抽取一个字段匹配值, 比如我们匹配一个Status 不是200的请求
{filename="/var/log/operation.LOG"} |
json | Status!="200"Metric Queries 可以理解为日志的agg处理,比如统计一个时间窗口内某个关键词的数量等操作, 一般 Metric Queries是跟在Log Queries后面。 比如我们要统计1m的Status非200的数量曲线,可以这样写
sum by (Status) (
count_over_time({filename="/var/log/operation.LOG"}
| json [1m]))上面这条查询语句可以这么理解,
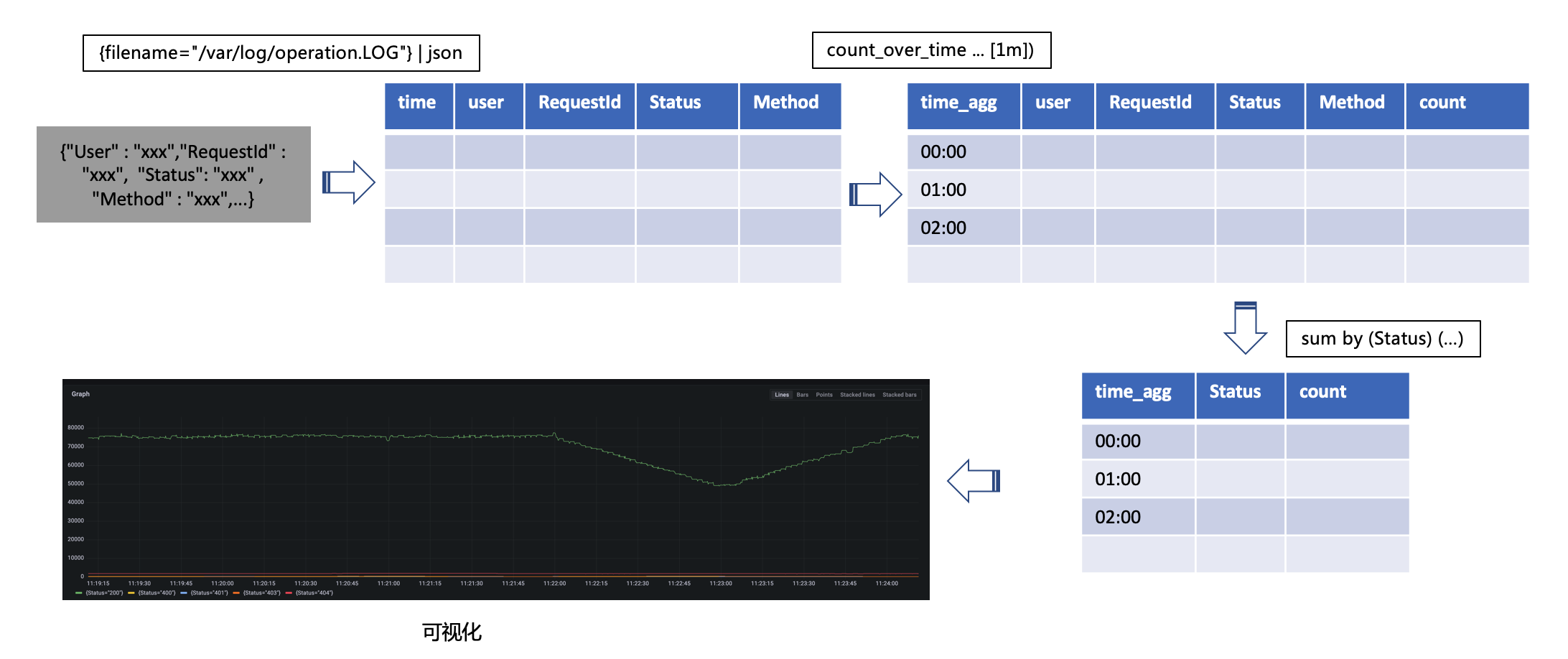
一般Loki查询语句的范式是这样的。

更多的LogQL查询的算子,可以参考官方文档https://grafana.com/docs/loki/latest/logql/
Loki的查询速度
构造了3种日志查询的场景,来看一下Loki在查询侧的表现
查询1 Log Query:硬扫一个requestId
{filename="/var/log/operation.LOG"} |="aabbccxx"查询2 Log Query: json抽取RequestId字段,进行精准匹配
{filename="/var/log/operation.LOG"} |
json RequestId="RequestId" |
RequestId="fasdfasdfae"查询3 Metric Query:对Status字段是200的进行统计, 使用instant 方式查询
sum by (Method, Status) (
count_over_time({filename="/var/log/operation.LOG"}
| json
| Status != "200" [15m]))3种查询场景测试下来,Loki表现是比较优秀的。
查询 |
Loki 最大CPU |
Loki Mem范围 |
Grafana 30s超时最大可扫描数据量 |
查询1 |
约 5core |
2G ~ 8G |
约2800万行 |
查询2 |
约 6core |
2G ~ 8G |
约1300万行 |
查询3 |
约 6core |
3G ~ 7G |
约1300万行 |
测试查询3的时候遇到Loki的限制,单个查询的series数量超过上限(Method+Status组合数量超过500种),通过下面参数调整解决。
limits_config:
max_query_series: 10000000从查询语句的体验上而言,Loki在日志的行处理(过滤/格式解析方面)还是很棒的。尤其是管道式的风格,对于程序员可以天然理解和接受。 在聚合分析方面,Loki目前只支持时序的分析方式,虽然很多聚合查询是可以用聚合Query完成的。但今天对于日志而言,还有很多OLAP分析的场景,时序的查询模式有点力不从心。
Loki在OSS上的存储情况
从oss侧看到,一天存储的日志总量约6G,原始大小约72G,压缩比达到12倍左右。
PS:loki使用gzip压缩,测试的日志相似度较高,达到了不错的压缩比。
总结
Loki作为新生代日志方案,在低成本、简单易用上有较大优势。 对于中小日志规模、查询响应时间、日志分析能力(AGG)能力要求不高的场景,较为适合。
