云数据仓库AnalyticDB PostgreSQL 版发布了最新自研的云原生架构实例,实现了跨实例间的数据共享能力。允许进行跨实例间的实时数据共享且无需进行数据迁移,可支持构建安全、高效、灵活的数据分析场景。本文介绍了依托数据共享实现云数仓跨多业务实例的敏捷数据分析方案。
业务介绍
背景
我们选取了最为常用的数仓架构下,数据工程师将业务数据库上的数据通过ETL整合入仓,开放给企业内的客户进行使用。 为方便理解,本文选取了TPC-DS的销售数据作为样本进行场景描述。
目前该企业内的组织架构存在着多个独立的业务部门,他们由于业务的独立性故配置了不同的资源实例。本文描述对于业务(市场部)和数据科学两个独立的业务两个部门的进行描述。
业务场景
业务部门主要的使用场景为运营大屏及业务分析师,需要使用市场投放数据和销售结果进行实时效果追踪,同时支持分析师基于业务需求进行Ad-hoc(一次性)业务分析;
数据科学部门主要使用场景为销售预测模型搭建及模型效果评估BI。
而基于企业内部的组织架构和实例使用特征,不同的业务部门保有独立的实例来实现业务,现在需要对销售数据分析时,各个业务团队需维护数据同步链路,将ETL实例上准备好的数据同步至业务实例才可进使用。
当前解决方案
目前两个业务部门将数据导出至OSS, 在导出后copy各自的业务实例中,整个链路的同步速度较慢,同时该链路无工具帮助用户观察实时进度,维护工作非常繁琐。
当前方案的痛点
数据的导入导出同步速度较慢,数据的实时性交较难保证。
该同步方式无工具支持,过程涉及人工干预,显著的增加了运维工作。
对于一次性分析的业务,数据的搬迁人工介入,工作量较大,分析效率大幅受影响。
数据的多次copy造成了企业的存储空间浪费, 成本较高。
方案架构图:

数据共享方案详解
AnalyticDB PostgreSQL为此场景提供了数据共享的解决方案。在对于ETL上的数据源,向下游各个业务实例需要使用的数据库进行数据共享链路的搭建,使其可以实时的访问ETL实例的数据源并与本地的业务进行Join分析。
数据共享架构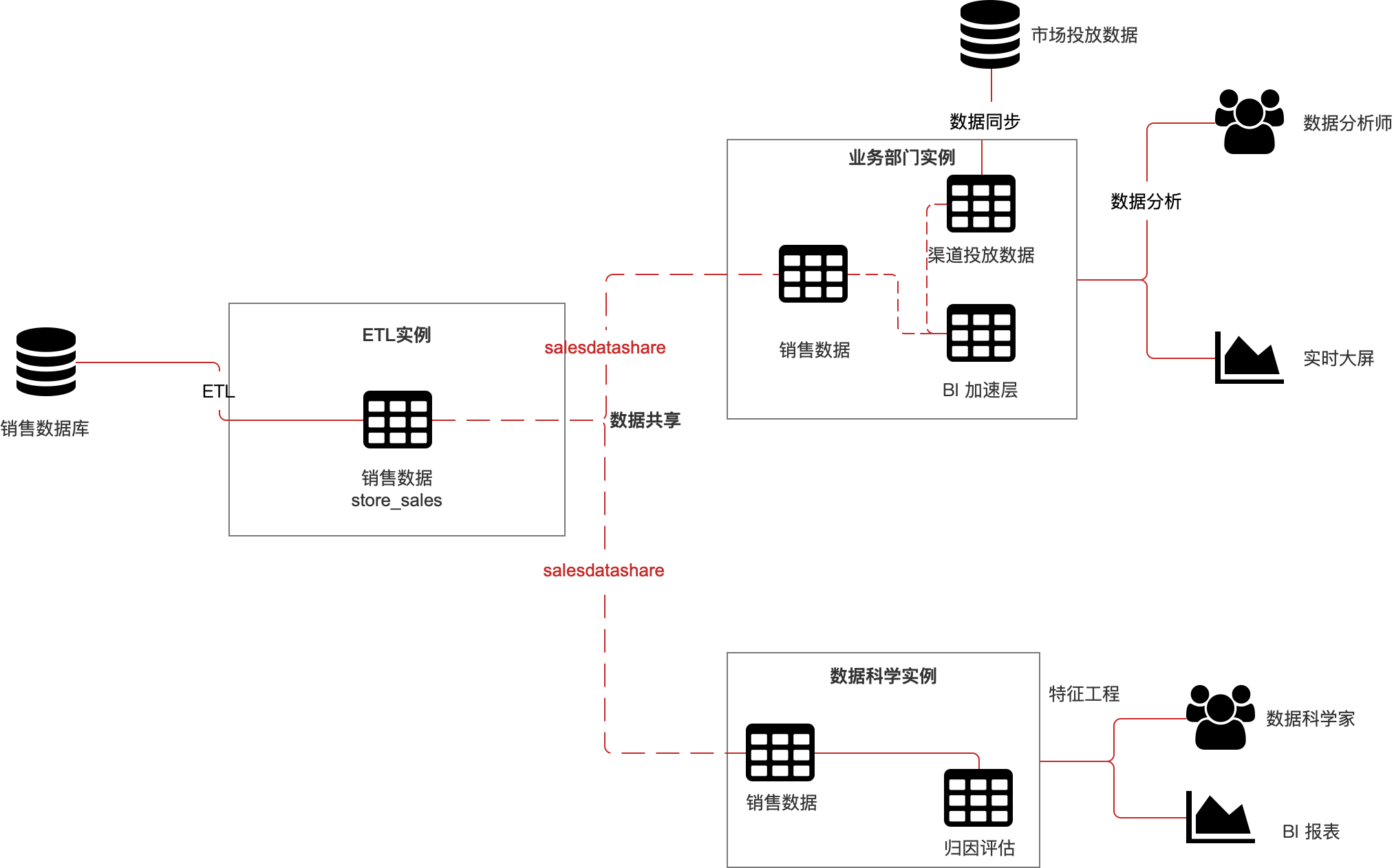
实施步骤
此次实施为一个典型的中心辐射型业务模型,在ETL集群中进行ETL,这个集群可以为BI工程师,业务分析师以及数据科学家提供分析所需的数据,为了业务独立性和资源隔离的需要,在不同的集群中运行业务分析和数据科学分析。由ETL集群作为数据生产者,业务分析集群和数据科学分析集群作为数据消费者。
在本案例中,使用TPC-DS中的6个表作为基础表进行演示:
CUSTOMER_ADDRESS
CUSTOMER_DEMOGRAPHICS
DATE_DIM
ITEM
CUSTOMER
STORE_SALES
步骤1:模拟ETL集群中建表
在ETL集群中创建6个基础表。这些表数据为业务数据,一般情况为通过DTS等工具导入到ADB PG中,这里模拟业务数据建表。
create schema sales;
set search_path = sales;
create table customer_address
(
ca_address_sk integer not null,
ca_address_id char(16) not null,
ca_street_number char(10) ,
ca_street_name varchar(60) ,
ca_street_type char(15) ,
ca_suite_number char(10) ,
ca_city varchar(60) ,
ca_county varchar(30) ,
ca_state char(2) ,
ca_zip char(10) ,
ca_country varchar(20) ,
ca_gmt_offset decimal(5,2) ,
ca_location_type char(20)
)
distributed by (ca_address_sk);
create table customer_demographics
(
cd_demo_sk integer not null,
cd_gender char(1) ,
cd_marital_status char(1) ,
cd_education_status char(20) ,
cd_purchase_estimate integer ,
cd_credit_rating char(10) ,
cd_dep_count integer ,
cd_dep_employed_count integer ,
cd_dep_college_count integer
)
distributed by (cd_demo_sk);
create table date_dim
(
d_date_sk integer not null,
d_date_id char(16) not null,
d_date date ,
d_month_seq integer ,
d_week_seq integer ,
d_quarter_seq integer ,
d_year integer ,
d_dow integer ,
d_moy integer ,
d_dom integer ,
d_qoy integer ,
d_fy_year integer ,
d_fy_quarter_seq integer ,
d_fy_week_seq integer ,
d_day_name char(9) ,
d_quarter_name char(6) ,
d_holiday char(1) ,
d_weekend char(1) ,
d_following_holiday char(1) ,
d_first_dom integer ,
d_last_dom integer ,
d_same_day_ly integer ,
d_same_day_lq integer ,
d_current_day char(1) ,
d_current_week char(1) ,
d_current_month char(1) ,
d_current_quarter char(1) ,
d_current_year char(1)
)
distributed by (d_date_sk);
create table item
(
i_item_sk integer not null,
i_item_id char(16) not null,
i_rec_start_date date ,
i_rec_end_date date ,
i_item_desc varchar(200) ,
i_current_price decimal(7,2) ,
i_wholesale_cost decimal(7,2) ,
i_brand_id integer ,
i_brand char(50) ,
i_class_id integer ,
i_class char(50) ,
i_category_id integer ,
i_category char(50) ,
i_manufact_id integer ,
i_manufact char(50) ,
i_size char(20) ,
i_formulation char(20) ,
i_color char(20) ,
i_units char(10) ,
i_container char(10) ,
i_manager_id integer ,
i_product_name char(50)
)
distributed by (i_item_sk);
create table customer
(
c_customer_sk integer not null,
c_customer_id char(16) not null,
c_current_cdemo_sk integer ,
c_current_hdemo_sk integer ,
c_current_addr_sk integer ,
c_first_shipto_date_sk integer ,
c_first_sales_date_sk integer ,
c_salutation char(10) ,
c_first_name char(20) ,
c_last_name char(30) ,
c_preferred_cust_flag char(1) ,
c_birth_day integer ,
c_birth_month integer ,
c_birth_year integer ,
c_birth_country varchar(20) ,
c_login char(13) ,
c_email_address char(50) ,
c_last_review_date char(10)
)
distributed by (c_customer_sk);
create table store_sales
(
ss_sold_date_sk integer ,
ss_sold_time_sk integer ,
ss_item_sk integer not null,
ss_customer_sk integer ,
ss_cdemo_sk integer ,
ss_hdemo_sk integer ,
ss_addr_sk integer ,
ss_store_sk integer ,
ss_promo_sk integer ,
ss_ticket_number integer not null,
ss_quantity integer ,
ss_wholesale_cost decimal(7,2) ,
ss_list_price decimal(7,2) ,
ss_sales_price decimal(7,2) ,
ss_ext_discount_amt decimal(7,2) ,
ss_ext_sales_price decimal(7,2) ,
ss_ext_wholesale_cost decimal(7,2) ,
ss_ext_list_price decimal(7,2) ,
ss_ext_tax decimal(7,2) ,
ss_coupon_amt decimal(7,2) ,
ss_net_paid decimal(7,2) ,
ss_net_paid_inc_tax decimal(7,2) ,
ss_net_profit decimal(7,2)
)
distributed by (ss_item_sk, ss_ticket_number);步骤2:在ETL集群创建共享
在ETL集群中使用如下的语句创建共享”salesdatashare”。
create datashare salesdatashare;创建完共享后,在ETL集群侧可以向共享中添加下游需要使用的数据表,这些个添加操作将数据表的元数据封装入数据共享并授权下游直接使用,数据无拷贝或挪动。
alter datashare salesdatashare add table customer_address;
alter datashare salesdatashare add table customer_demographics;
alter datashare salesdatashare add table date_dim;
alter datashare salesdatashare add table item;
alter datashare salesdatashare add table customer;
alter datashare salesdatashare add table store_sales;步骤3:将共享赋权给市场业务实例和数据科学分析实例
在ADB PG产品内,会使用GUID对数据库进行唯一标识,GUID在不同的实例间也不重复。
数据共享需要对目标数据库的GUID进行白名单授权,故两个目标实例需要向ETL实例提供GUID。
GUID获取方法,可在数据库内使用以下语句获取该库的GUID。
select dbuuid as guid from pg_database d, rds_share_identifier si
where d.oid = si.dboid and d.datname = current_database();本案例假定3个涉及的数据库GUID分别为:
名称 |
GUID |
ETL集群 |
821a235c-85b2-4fed-aa35-bbe6123e8e56 |
BI分析集群 |
668862c4-e55a-4ab6-8d10-1c8ab5b8f48a |
数据科学分析集群 |
e6fc2a5e-07bd-4ae4-af94-dd917a3e6a13 |
在ETL集群中,将共享赋权给业务分析实例和数据科学分析实例,授权语句如下:
-- BI分析集群
grant usage on datashare salesdatashare to database "668862c4-e55a-4ab6-8d10-1c8ab5b8f48a";
-- 数据科学分析集群
grant usage on datashare salesdatashare to database "e6fc2a5e-07bd-4ae4-af94-dd917a3e6a13";步骤4:在业务分析集群中导入共享并使用共享数据
当授权完成后,需要在消费的实例内进行数据共享的导入后才可使用。
导入ETL集群中共享salesdatashare的语句如下:
import datashare salesdatashare from database "821a235c-85b2-4fed-aa35-bbe6123e8e56";导入完成后,就可以在业务分析集群中查询到ETL端共享的数据并进行业务分析。
参考如下语句:
select
c_customer_sk,
c_customer_id,
c_birth_year,
c_birth_country,
c_last_review_date_sk,
ca_city,
ca_state,
ca_zip,
ca_country,
ca_gmt_offset,
cd_gender,
cd_marital_status,
cd_education_status
from salesdatashare.sales.customer c, salesdatashare.sales.customer_address ca, salesdatashare.sales.customer_demographics cd
where
c.c_current_addr_sk=ca.ca_address_sk
and c.c_current_cdemo_sk=cd.cd_demo_sk;
select
i_item_id,
i_product_name,
i_current_price,
i_wholesale_cost,
i_brand_id,
i_brand,
i_category_id,
i_category,
i_manufact,
d_date,
d_moy,
d_year,
d_quarter_name,
ss_customer_sk,
ss_store_sk,
ss_sales_price,
ss_list_price,
ss_net_profit,
ss_quantity,
ss_coupon_amt
from salesdatashare.sales.store_sales ss, salesdatashare.sales.item i, salesdatashare.sales.date_dim d
where ss.ss_item_sk=i.i_item_sk
and ss.ss_sold_date_sk=d.d_date_sk;步骤5:在数据科学分析集群中导入共享并使用共享数据
同样的,在数据科学实例中也可同样导入ETL集群中共享的salesdatashare,
语句如下:
import datashare salesdatashare from database "821a235c-85b2-4fed-aa35-bbe6123e8e56";这样在数据科学分析集群中也可以对ETL集群中的数据进行数据科学的分析,数据科学家可以随意地根据关注点编写SQL语句,对数据进行挖掘,分析其中的销售数据。
方案评估
实时性对比
这里对传统数据拷贝方式与数据共享方式进行实时性的对比,一下以32节点实例1TB数据量为例:
操作 |
OSS外表方式 |
数据共享 |
源端导出 |
数据导出 10MB/节点/s,约0.87小时 |
创建共享 毫秒级 |
目标端导入 |
外表导入 10MB/节点/s,约0.87小时 |
导入共享 毫秒级 |
易用性对比
在易用性方面,数据拷贝与数据共享方式的有较大区别,数据共享整体仅需1~2分钟即可持续的稳定的提供一条数据跨实例使用的链路。数据拷贝链路需要大量的人工介入,并等待几个小时完成数据准备工作。
中转存储介质:
数据拷贝: 在数据实例间拷贝时,需要额外使用OSS作为数据中转存储,在数据导出和导入后还需清理冗余的中转存储。
数据共享:无需任何中转存储介质。
目标库建表:
数据拷贝: 传统方式需在目标端建表,OSS外表方式还需要在源端和目标端建外表。
数据共享: 无需关心建表,导入即可用。
存储成本评估
额外存储类型 |
数据拷贝方式 |
数据共享 |
中转存储 |
1TB数据OSS存储 1.74小时 |
无 |
数据冗余 |
1TB数据本地存储 价格:2048 元/月 |
无 |
方案总结
大幅减轻了业务团队的数据运维压力,无需维护ETL实例和业务实例间的数据同步链路,可更专注于管理域内数据面向BI的数据工程工作。
数据共享开通过程极简化化,可实现快速的数据共享支持Ad-hoc分析。
避免了数据拷贝导致的数据冗余。
实时数据同步,即数据源完成数据清洗工作后,所有的数据消费实例可实时进行分析,无需等待。
结束语
本文介绍了一个典型的多业务间数据分析的场景, 对于已构筑在ADBPG上的企业来说,随着业务的增长和业务件独特性的需要,需要进行底层基础架构的拆分以简化管理复杂度和低成本支持每个业务支持。由于ADBPG的数据共享能力, 企业无需担心架构的独立性会导致数据孤岛,数据共享可持续保证技术架构的灵活性和跨业务的数据连通性。
.