免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

如果你是 ChatGPT 的重度用户,你可能会感受到当今 AI 产品有许多的局限性:幻觉,过时的信息,领域知识的缺乏,机密数据的处理等等。 这一年来,有一个技术在硅谷引起了越来越多的关注,那就是检索增强生成(RAG)。
本文将介绍 RAG 究竟是什么,以及硅谷创业者和科研人如何看待它的未来。
大语言模型的局限性
- 幻觉:模型可能会生成不正确或捏造的信息,影响其可靠性。
- 过时的信息:由于模型是在静态数据集上训练的,因此无法提供训练日期之后发生的事件的信息。
- 缺乏领域知识:模型可能对专业领域没有深入的了解,导致答案过于简单或不准确。
- 处理机密数据:使用大语言模型对于涉及公司数据或个人信息的任务具有挑战性。
所有这些都表明一个需求,就是要把额外的信息合并到预先训练好的大语言模型中。
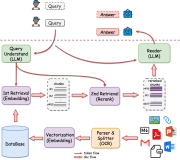
技术解析
RAG 最简单的例子
RAG 论文由 Facebook AI Research 于 2020 年 10 月首次提出,旨在提高处理自然语言任务的性能。
一个最简单的例子: 比如现在我们有一份旅游景点打卡清单,希望大语言模型能够谈论这些内容,我们把每一行看作一个文本文档。

旅游景点打卡清单:“在公园里悠闲地散步,呼吸新鲜空气。”“参观当地博物馆并发现新事物。”“参加现场音乐会并感受节奏。”“去徒步旅行,欣赏自然风光。”“和朋友一起野餐,分享欢笑。”
当用户输入这个:
user_input = “我喜欢徒步”
系统可以搜索刚才那个列表,找出最相关的文档。这里我们定义相似度为拥有最多重复的字好了。
relevant_document = “去徒步旅行,欣赏自然风光。”
然后把用户输入和搜到的最相关文档替换进准备好的提示词里。

“你是一个为活动提供建议的机器人。 你需要用非常短的句子回答,并且不包含额外的信息。这是推荐的活动:{relevant_document} 用户输入是:{user_input} 根据推荐的活动和用户输入,向用户推荐好玩的景点。”
现在系统可以将新的提示词发送给大语言模型,等它回复个啥出来:
“赞! 根据您对徒步旅行的兴趣,我建议您尝试附近的步道,享受充满挑战且有益的体验,欣赏壮丽的景色,享受有趣且富有挑战性的冒险。”
这就是 RAG 技术的基本理念。
潜在的改进
这是最简化的版本,实际上,有一些潜在的改进——

每个词都是高维空间中的向量:
- 点积:两个向量的相乘
- 余弦相似度:测量两个向量之间的角度
- 欧氏距离:测量两个向量之间的距离
此外,还有具有更多模块和不同组件的高级 RAG。

应用落地场景
自 2023 年夏季以来,RAG 受到了广泛关注。如下图为Retrieval Augmented Generation 一词的谷歌搜索热度:

我们看到各家科技巨头已经开始提供工具,来辅助他们的客户构建 RAG 应用程序。
英伟达的人工智能软件副总裁 Kari Briski 在官网上说:“随着企业在 2024 年采用这些 AI 框架,预计我们会听到更多有关 RAG 的信息。”
想象一下在这些现实场景中使用 RAG,其中一些已经成为现实——
- 教育:教育平台使用 RAG 生成学习材料,并创建学科题目的详细解释。
- 聊天机器人:由 RAG 驱动的聊天机器人和虚拟助理,可为用户提供更准确更得体的回复。(例:CastChat)
- 游戏:RAG 可根据玩家的选择和行动,生成动态的游戏叙事、对话和故事情节。(例:Inworld)

RAG 可根据玩家的选择和行动,生成动态的游戏叙事、对话和故事情节。
什么时候选择用 RAG
2024 年的一篇文章得出结论,RAG 最适合高外部知识和低模型适应的场景。

学界讨论
RAG vs. 长上下文窗口
现在硅谷的一个热门辩论话题是, RAG 是否会因为大模型上下文窗口变长而变得过时。 由于内存和计算能力的限制,大语言模型只能记住最近的用户输入,这个长度又叫作上下文窗口长度。这两年来,大语言模型的上下文窗口长度变得越来越长。大语言模型的上下文窗口长度:

尤其是上个月,谷歌发布了Gemini 1.5,上下文窗口长达十万。许多人看了直呼 RAG 将会被历史抛弃,因为我们想要的附加信息可以成为输入提示词的一部分。
也很多专业人士表达了反对的看法——
Gemini 的联合负责人 Oriol Vinyals 说:“RAG 有一些很好的特性,可以增强长上下文,也可以被长上下文增强。”这说明他相信 RAG 和长上下文将在未来相辅相成。
AI 初创公司创始人 Siva Surendira 则提醒大家,RAG 更便宜、更快。
爱丁堡大学计算机科学博士 Yao Fu 看好长上下文模型的潜力。他认为,虽然长上下文的成本较高且当前存在局限性,但它能提供超强的即时检索和推理能力,并猜测未来大语言模型可能可以直接访问普通的数据库,就像谷歌索引一样。
英伟达的 Jim Fan 表示赞同,并设想了一种将 RAG 与长上下文窗口相结合的方法,也许是“在巨大的非结构化数据库中传播神经激活的某种形式”。
AI 初创公司创始人 Elvis Saravia,也同意结合的这个路径。 他指出,“用不同的大语言模型可以解决不同的问题。 我们要摆脱这种想法,就是我们必须用同一种模型处理所有问题。”
长期替代方案
微软的高级首席云解决方案架构师 James Nguyen,在他的文章提到了 RAG 的一些局限性。 例如,检索、增强和生成的过程是独立处理的,这意味着负责检索的部分和负责生成的部分,对于用户的意图可能有不同的理解。 如果在检索阶段由于打开方式不对,造成了低质量或不相关的结果,那么模型可能在生成的时候又开始乱编,这样就又产生幻觉了。
他提议了一种基于 agent 的方法,“当 agent 需要查找它不具备的知识时,会自己谷歌一下答案。”
ActGPT能从谷歌搜索最新信息并执行发文任务:

哪些替代解决方案将会成为主流? 他希望更多地关注混合专家模型 (MoE),这是一种结合了多个 LLM 模块和一个控制最终输出的架构。

结论
从研究成果和创业实践来看,RAG 仍然是目前解决很多问题最有效的方式,至少在未来五年内不会被取代。 长远来看,更智能的架构会不断发展,最终超越 RAG。
了解阿里云向量检索服务DashVector的使用方法,请点击:
https://help.aliyun.com/product/2510217.html?spm=a2c4g.2510217.0.0.54fe155eLs1wkT