写给工程师的 MacBook 商用级大模型知识库部署方案(上):https://developer.aliyun.com/article/1443298
运行该程序所需的 Python 依赖项:
accelerate==0.24.1 aiofiles==23.2.1 aiohttp==3.8.6 aiosignal==1.3.1 altair==5.1.2 annotated-types==0.6.0 anyio==3.7.1 async-timeout==4.0.3 attrs==23.1.0 blinker==1.7.0 cachetools==5.3.2 certifi==2023.7.22 charset-normalizer==3.3.2 click==8.1.7 contourpy==1.2.0 cpm-kernels==1.0.11 cycler==0.12.1 fastapi==0.103.2 ffmpy==0.3.1 filelock==3.13.1 fonttools==4.44.0 frozenlist==1.4.0 fsspec==2023.10.0 gitdb==4.0.11 GitPython==3.1.40 gradio==3.50.2 gradio_client==0.6.1 h11==0.14.0 httpcore==1.0.2 httpx==0.25.1 huggingface-hub==0.19.1 idna==3.4 importlib-metadata==6.8.0 importlib-resources==6.1.1 Jinja2==3.1.2 joblib==1.3.2 jsonschema==4.19.2 jsonschema-specifications==2023.7.1 kiwisolver==1.4.5 latex2mathml==3.76.0 linkify-it-py==2.0.2 Markdown==3.5.1 markdown-it-py==2.2.0 MarkupSafe==2.1.3 matplotlib==3.8.1 mdit-py-plugins==0.3.3 mdtex2html==1.2.0 mdurl==0.1.2 mpmath==1.3.0 multidict==6.0.4 networkx==3.2.1 nltk==3.8.1 numpy==1.26.2 orjson==3.9.10 packaging==23.2 pandas==2.1.3 Pillow==10.1.0 protobuf==4.25.0 psutil==5.9.6 pyarrow==14.0.1 pydantic==2.1.1 pydantic_core==2.4.0 pydeck==0.8.1b0 pydub==0.25.1 Pygments==2.16.1 pyparsing==3.1.1 python-dateutil==2.8.2 python-multipart==0.0.6 pytz==2023.3.post1 PyYAML==6.0.1 referencing==0.30.2 regex==2023.10.3 requests==2.31.0 rich==13.6.0 rpds-py==0.12.0 safetensors==0.4.0 scikit-learn==1.3.2 scipy==1.11.3 semantic-version==2.10.0 sentence-transformers==2.2.2 sentencepiece==0.1.99 six==1.16.0 smmap==5.0.1 sniffio==1.3.0 sse-starlette==1.6.5 starlette==0.27.0 streamlit==1.28.2 sympy==1.12 tabulate==0.9.0 tenacity==8.2.3 threadpoolctl==3.2.0 tiktoken==0.5.1 tokenizers==0.13.3 toml==0.10.2 toolz==0.12.0 torch==2.1.0 torchvision==0.16.0 tornado==6.3.3 tqdm==4.66.1 transformers==4.30.2 typing_extensions==4.6.1 tzdata==2023.3 tzlocal==5.2 uc-micro-py==1.0.2 urllib3==2.1.0 uvicorn==0.24.0.post1 validators==0.22.0 websockets==11.0.3 yarl==1.9.2 zipp==3.17.0
- 搭建 One API 接口管理/分发系统
One API是一套兼容多种 LLM 接口规范的 API 路由方案,支持限额和计费管理,通过标准的 OpenAI API 格式访问所有的大模型,开箱即用,其多模型渠道接入、多用户管理、费用管理、额度管理、以及集群化部署支持等功能,对商用场景都很友好。项目使用 MIT 协议进行开源。
One API 基于 Go 和 Node.js 开发,搭建之前准备好,我的版本是:go1.21.4、Node.js v20.9.0,构建命令如下:
git clone https://github.com/songquanpeng/one-api.git # 构建前端 cd one-api/web npm install npm run build # 构建后端 cd .. go mod download go build -ldflags "-s -w" -o one-api
One API 里面预置了很多市面上的可用模型接口,好处是可以直接使用无需配置,缺点是没有添加自定义(本地)接口的能力。由于我们是自己搭建的 LLM 和 embedding 服务,需要修改其源代码,增加 ChatGLM3 和 m3e-base 的选项。
改动涉及两个文件,分别是 common/model-ratio.go 和 controller/model.go,改动内容如下图:


注意,改完文件后记得重新编译可执行文件。本地的元数据存储我使用了 MySQL,编译+启动命令是:
go build -ldflags "-s -w" -o one-apiexport SQL_DSN=oneapi:oneapi@tcp(localhost:3306)/oneapi && ./one-api --port 3001 --log-dir ./log
初始登录进去,创建一个新令牌用于权限管控和计费:

令牌可以从这里复制,下面有用:

One API 的渠道管理界面如下图,我已经配置了俩渠道,一个 chat 渠道,一个 embedding 渠道:

具体的配置值如下图,名称写实际的模型名 ChatGLM3,模型选刚才手动添加上去的 ChatGLM3: 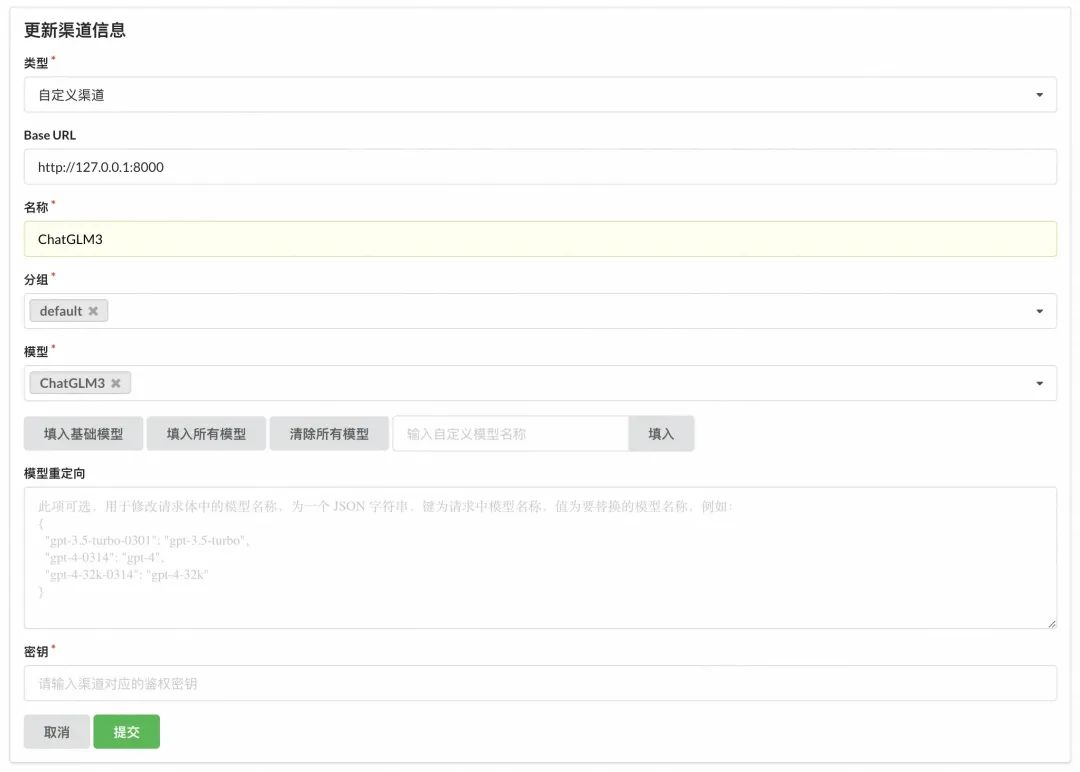

配置完后可以在列表页点一下测试验证,连通无问题就行,但现在似乎一测就会把模型API服务弄挂,不过没关系,不影响后面验证。
▐ 搭建知识库应用
在这个环节里,我们采用类似 Dify.ai (地址:https://dify.ai/)的国产化开源 FastGPT 方案搭建属于自己的本地知识库应用平台。FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。FastGPT 遵循 Apache License 2.0 开源协议,我们可以 Fork 之后进行二次开发和发布。
FastGPT 的核心流程图如下:

从 FastGPT 官网得知,这套开源系统基于以下几个基本概念进行知识库检索:
- 向量:将人类直观的语言(文字、图片、视频等)转成计算机可识别的语言(数组)。
- 向量相似度:两个向量之间可以进行计算,得到一个相似度,即代表:两个语言相似的程度。
- 语言大模型的一些特点:上下文理解、总结和推理。
结合上述 3 个概念,便有了 “向量搜索 + 大模型 = 知识库问答” 的公式。下图是 FastGPT V3 中知识库问答功能的完整逻辑:
 FastGPT 的向量存储方案是 PostgreSQL+pgvector,其他数据放在 MongoDB 里面,因此我们先把这两项依赖搞定。
FastGPT 的向量存储方案是 PostgreSQL+pgvector,其他数据放在 MongoDB 里面,因此我们先把这两项依赖搞定。
- 安装 MongoDB
MacBook 安装 MongoDB 很简单,如果没有特别的安全诉求,可以先不用设置用户名密码
brew install mongodb-community brew services start mongodb-community
FastGPT 基于 MongoDB 存储知识库索引、会话内容、工作流等管理数据: 
- 安装 PostgreSQL & pgvector
FastGPT 采用了 RAG 中的 Embedding 方案构建知识库,PostgresSQL 的 PG Vector 插件作为向量检索器,索引为HNSW。PostgresSQL 仅用于向量检索,MongoDB用于其他数据的存取。另外也可以采用第三方模型的 Embedding API,比如 ChatGPT embedding,不过为了实现完整的本地化部署,就没有用外部服务。
我们可以从 PostgreSQL 的官网下载 PostgreSQL 安装包:https://www.postgresql.org/download/macosx/从源码安装 pgvector:https://github.com/pgvector/pgvector
// 安装 pgvector 前指定 PostgreSQL 位置 export PG_CONFIG=/Library/PostgreSQL/16/bin/pg_config // 如果 pgvector 认错了 MacOS SDK 的位置,还得帮他软链一个 sudo ln -s /Library/Developer/CommandLineTools/SDKs/MacOSX13.sdk /Library/Developer/CommandLineTools/SDKs/MacOSX11.sdk // 或者用这个命令 export SDKROOT=$(xcrun --sdk macosx --show-sdk-path) // 源码编译安装 make make install # may need sudo // 确保插件已安装到 PostgreSQL 目录下 cd /Library/PostgreSQL/16/share/postgresql/extension/ ls | grep vector
完成以上步骤后,打开 PostgreSQL 控制台,随便建立一个连接,运行下面的查询:
CREATE EXTENSION vector; SELECT * FROM pg_extension WHERE extname = 'vector';
写给工程师的 MacBook 商用级大模型知识库部署方案(下):