1 什么是布隆过滤器
- 布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器本质上由一个长度为m的位向量组成。
- 基本的布隆过滤器支持两种操作:测试和添加。
- 用途:布隆过滤器可以用于检索一个元素是否在一个集合中。
- 它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
(误识别:元素不存在而说在,不会出现元素在而说不在,即在肯定在,不在可能在)
2 布隆过滤器和HashSet有什么不同
布隆过滤器:
- 基本思想:通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
- 优点:占用空间小,效率高。
- 缺点:存在误差率,不能删除元素。
HashSet:
- 基本思想:利用Hash函数将元素的HashCode取出,放在一个内部的数组或链表中,增删改查元素时一般都是根据元素的HashCode进行操作。
- 优点:使用简单,原理简单。
- 缺点:占用内存大,性能较低。
综上,布隆过滤器主要适用于大量数据的去重,而HashSet等数据结构适合中小量数据的去重和检验。
3 使用布隆过滤器
实现布隆过滤器的方式有很多种,比如:
- Guava实现
- Redis实现
- 自己实现
- …
这里我们使用Google Guava的内置布隆过滤器做演示:
依赖:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>23.0</version> </dependency>
代码:
public class Test { /** * 过滤器默认容量 */ private static final int DEFAULT_SIZE = 1000000; /** * 自定义误判率,默认0.03,区间(0,1) */ private static final double FPP = 0.02; public static void main(String[] args) { //初始化一个存储string数据的布隆过滤器,默认误判率是0.03 BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), DEFAULT_SIZE, FPP); //用于存放所有实际存在的key,用于是否存在 Set<String> sets = new HashSet<>(DEFAULT_SIZE); //用于存放所有实际存在的key,用于取出 List<String> lists = new ArrayList<>(DEFAULT_SIZE); //插入随机字符串 for (int i = 0; i < DEFAULT_SIZE; i++) { String uuid = UUID.randomUUID().toString(); //添加数据 bf.put(uuid); sets.add(uuid); lists.add(uuid); } int rightNum = 0; int wrongNum = 0; for (int i = 0; i < 10000; i++) { // 0-10000之间,可以被100整除的数有100个(100的倍数) String data = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString(); //这里用了might,看上去不是很自信,所以如果布隆过滤器判断存在了,我们还要去sets中实锤 if (bf.mightContain(data)) { if (sets.contains(data)) { rightNum++; continue; } wrongNum++; } } BigDecimal percent = new BigDecimal(wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP); BigDecimal bingo = new BigDecimal(9900 - wrongNum).divide(new BigDecimal(9900), 2, RoundingMode.HALF_UP); System.out.println("在100W个元素中,判断100个实际存在的元素,布隆过滤器认为存在的:" + rightNum); System.out.println("在100W个元素中,判断9900个实际不存在的元素,误认为存在的:" + wrongNum + ",命中率:" + bingo + ",误判率:" + percent); } }
运行结果:

原理:
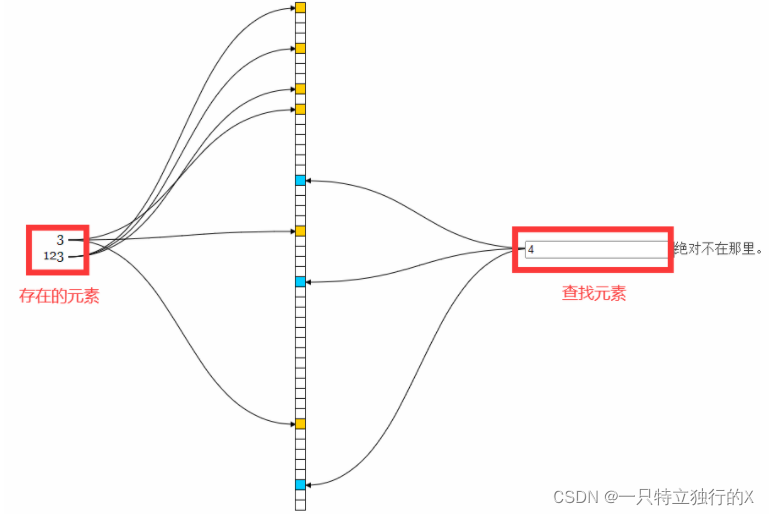
布隆过滤器的核心原理就是利用位数组,将元素利用多次Hash映射成位,当判断是否存在时,将被查找元素按相同操作映射,当一个元素可能有多个位,当每个位都为1时证明该元素存在,反之则不存在。
演示:
# 存储元素: abc ---> {2,3,4}都为1 def ---> {5,6,7}都为1 # 查找元素: abc ---> {2,3,4}都为1 1==1&&1==1&&1==1 --->true 存在 aaa ---> {2,3,3}都为1 1==1&&1==1&&0==1 --->false 不存在 # 存在误差: acf ---> {2,3,6}都为1 1==1&&1==1&&1==1 --->true 存在
4 手写简单的布隆过滤器
public class MyBloomFilter { /** * 使用加法hash算法,所以定义了一个3个元素的质数数组 */ private static final int[] primes = new int[]{2, 3, 5}; /** * 用八个不同的质数,相当于构建8个不同算法 */ private Hash[] hashList = new Hash[primes.length]; /** * 创建一个长度为10亿的比特位 */ private BitSet bits = new BitSet(1000000000); public MyBloomFilter() { for (int i = 0; i < primes.length; i++) { //使用3个质数,创建3种算法 hashList[i] = new Hash(primes[i]); } } /** * 添加元素 * @param value */ public void add(String value) { for (Hash f : hashList) { bits.set(f.hash(value), true); } } /** * 判断是否在布隆过滤器中 * @param value * @return */ public boolean contains(String value) { if (value == null) { return false; } boolean ret = true; for (Hash f : hashList) { //查看3个比特位上的值 ret = ret && bits.get(f.hash(value)); } return ret; } /** * 加法hash算法 */ public static class Hash { private int prime; public Hash(int prime) { this.prime = prime; } public int hash(String key) { int hash, i; for (hash = key.length(), i = 0; i < key.length(); i++) { hash += key.charAt(i); } return (hash % prime); } } public static void main(String[] args) { MyBloomFilter bloom = new MyBloomFilter(); System.out.println(bloom.contains("2222")); bloom.add("2222"); //维护1亿个在线用户 for (int i = 1; i < 100000000; i++) { bloom.add(String.valueOf(i)); } long begin = System.currentTimeMillis(); System.out.println(begin); System.out.println(bloom.contains("2222")); long end = System.currentTimeMillis(); System.out.println(end); System.out.println("判断2222是否存在使用了:" + (end - begin)); } }
运行结果:

参考文章:
https://blog.csdn.net/wuzhiwei549/article/details/106714765
https://www.jasondavies.com/bloomfilter/



