向量检索服务 DashVector 免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector
本文介绍向量检索服务如何通过控制台、SDK、API三种不同的方式创建Partition。
向量检索服务中,同一个Collection下的向量可通过不同的Partition进行分区,实现向量数据的分区管理。在查询过程中通过指定Partition来缩小查询范围,提高查询效率。
控制台方式
前提条件
- 已开通服务。
- 已创建Collection。
步骤
- 登录向量检索服务控制台。
- 单击Cluster列表,选中Cluster下需要创建Partition的Collection,单击详情。

- 在左侧二级导航栏,单击Partition管理。
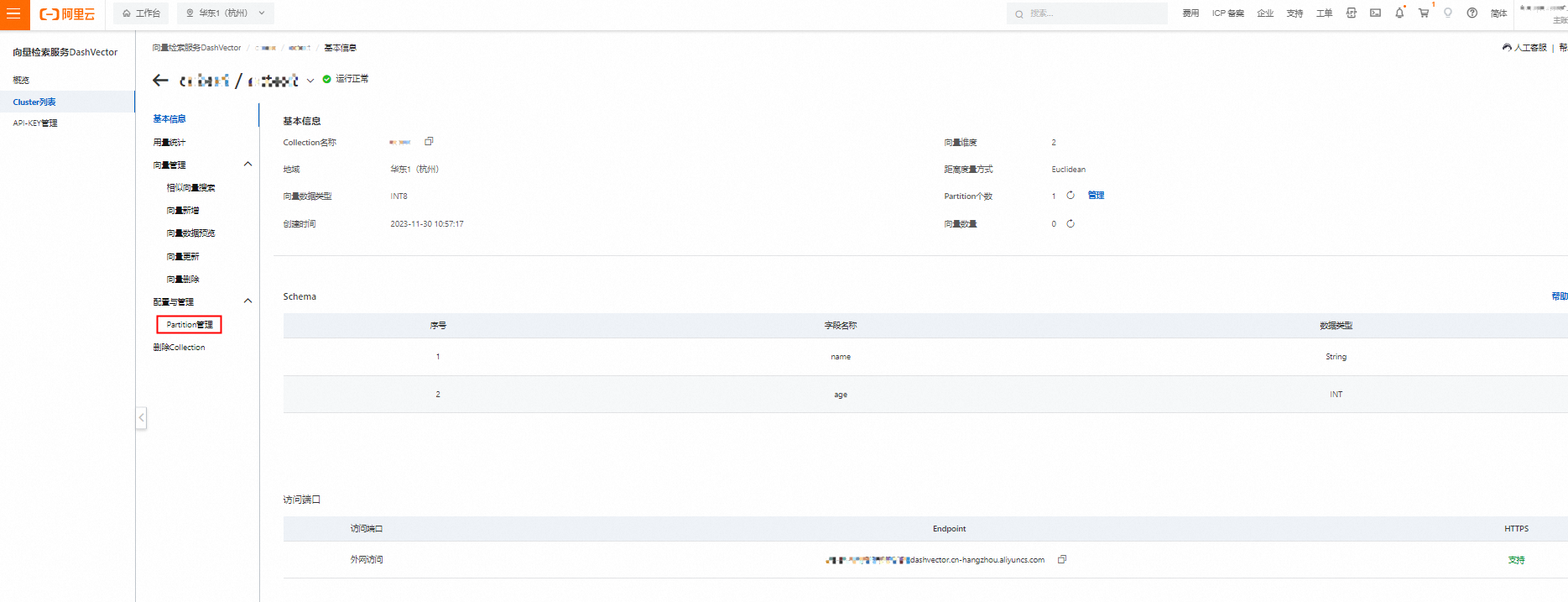
- 单击新建Partition,然后在弹窗填写Partition名称,单击创建完成Partition创建。
 说明
说明
- Partition名称不能超过32个字符。
- Partition名称必须以大小写字母、数字和符号(_,-)组成,且必须以字母开头。
- 同一个Collection中不能存在两个同名的Partition。
- Collection会默认新建一个名称为default的Partition,且不能被删除。
- Partition的相关说明即使用方法,请参见分区Partition。
SDK方式
Python SDK
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
接口定义
Collection.create_partition(name: str) -> DashVectorResponse
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection。
import dashvector client = dashvector.Client( api_key='YOUR_API_KEY', endpoint='YOUR_CLUSTER_ENDPOINT' ) collection = client.get(name='quickstart') # 创建一个名称为shoes的Partition ret = collection.create_partition('shoes') # 判断create_partition接口是否成功 if ret: print('create_partition success')
Java SDK
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
接口定义
// class DashVectorCollection public Response<Void> createPartition(String name, Integer timeout);
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection。
import com.aliyun.dashvector.DashVectorClient; import com.aliyun.dashvector.DashVectorCollection; import com.aliyun.dashvector.common.DashVectorException; import com.aliyun.dashvector.models.responses.Response; public class Main { public static void main(String[] args) throws DashVectorException { DashVectorClient client = new DashVectorClient("YOUR_API_KEY", "YOUR_CLUSTER_ENDPOINT"); DashVectorCollection collection = client.get("quickstart"); // 创建一个名称为shoes的Partition Response<Void> response = collection.createPartition("shoes"); // 判断createPartition方法是否成功 if (response.isSuccess()) { System.out.println("createPartition success"); } } }
API方式
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
Method与URL
POST https://{Endpoint}/v1/collections/{CollectionName}/partitions
使用示例
说明
- 需要使用您的api-key替换示例中的YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
- 本示例需要参考新建Collection-使用示例提前创建好名称为
quickstart的Collection。
curl -XPOST \ -H 'dashvector-auth-token: YOUR_API_KEY' \ -H 'Content-Type: application/json' \ -d '{ "name": "shoes" }' https://YOUR_CLUSTER_ENDPOINT/v1/collections/quickstart/partitions # example output: # {"request_id":"19215409-ea66-4db9-8764-26ce2eb5bb99","code":0,"message":""}
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector