前言
每天,企业和组织产生大量的数据。这些数据可能来自各种来源,包括日志、数据库、传感器等等。处理这些海量数据通常需要高效、可靠的方法,这就是Spring批处理的用武之地。无论你是数据工程师、数据科学家还是应用程序开发者,了解Spring批处理如何工作以及如何在你的项目中应用它都是非常有价值的。在这篇博客中,我们将带你深入探讨Spring中的批处理,从基础概念到高级技巧,为你揭示数据处理的奥秘。
第一:什么是Spring批处理
Spring批处理是Spring Framework中的一个模块,用于处理大规模数据批量处理任务的框架。它提供了一种有效的方式来执行大规模数据操作,如ETL(Extract, Transform, Load)任务、数据迁移、报表生成等。下面我们来介绍Spring批处理的基本概念和用途,并讨论它的优势。
基本概念:
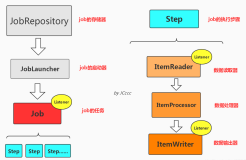
- Job(作业):Job是Spring批处理的顶层概念,表示一个完整的批处理任务。它可以包含多个Step,定义了批处理的执行顺序和条件。
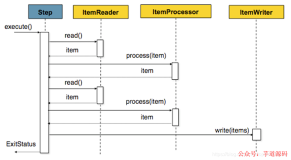
- Step(步骤):Step是Job中的一个单独步骤,它包含了数据读取、处理和写入的逻辑。每个Step可以定义一个ItemReader、ItemProcessor和ItemWriter。
- ItemReader(数据读取器):ItemReader用于从数据源中读取数据。Spring Batch提供了多种ItemReader的实现,包括从数据库查询、文件、XML、JSON、消息队列等数据源中读取数据。你也可以自定义ItemReader以满足特定需求。
- ItemProcessor(数据处理器):ItemProcessor用于对读取的数据进行处理和转换。这是一个可选组件,通常用于数据清洗、数据转换和数据筛选等操作。
- ItemWriter(数据写入器):ItemWriter用于将处理后的数据写回到目标数据源或文件。类似于ItemReader,Spring Batch提供了多种ItemWriter的实现,也可以自定义。
用途:
Spring批处理在以下应用场景中非常有用:
- 数据迁移和同步:当你需要将数据从一个数据源迁移到另一个数据源,或者保持多个数据源的同步时,Spring批处理可以帮助你实现这一目标。
- 报表生成:定期生成报表是企业应用的一部分。Spring批处理能够从多个数据源中提取数据,并生成报表。
- ETL任务:ETL(抽取、转换、加载)是将数据从一个位置提取、转换并加载到另一个位置的常见任务。Spring批处理提供了强大的工具来执行这些任务。
- 大规模数据处理:无论是处理大型数据集还是大规模数据导入,Spring批处理能够有效地处理大量数据。
优势:
Spring批处理的优势包括:
- 可伸缩性:你可以配置批处理任务以在多个线程或分布式环境中运行,以处理大规模数据。
- 容错性:Spring批处理支持故障恢复,任务可以在失败后自动重新启动,并且提供了事务管理以确保数据一致性。
- 高性能:Spring Batch经过优化,可以处理大数据集而不会占用过多内存或资源。
- 可管理性:提供了监控和管理工具,可以查看任务的状态、进度和日志,以便管理和维护批处理作业。
总之,Spring批处理是一个强大的工具,适用于需要处理大规模数据的应用场景,提供了可伸缩性、容错性和高性能,以简化数据处理任务的开发和管理。同时,在代码实现中,可以使用注释来说明每个步骤的具体功能和逻辑,以提高代码的可读性和可维护性。
第二:Spring Batch入门
Spring Batch的入门涉及配置和启动批处理作业,以及理解一些关键概念。下面是一个入门指南:
1. 配置Spring Batch作业:
Spring Batch作业的配置通常涉及以下步骤:
a. 添加Spring Batch依赖: 首先,在你的项目中添加Spring Batch的依赖,通常可以通过Maven或Gradle来实现。以下是一个Maven依赖的示例:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency>
b. 创建Job配置类: 创建一个Java配置类,用于定义Spring Batch的作业。这个配置类应该使用@Configuration注解,并通过@EnableBatchProcessing注解启用Spring Batch。
@Configuration @EnableBatchProcessing public class BatchJobConfig { // Define your job and steps here }
c. 定义Job和Step: 在作业配置类中,定义一个或多个Job和它们的Step。一个Job通常包括一个或多个Step。定义Job和Step的示例:
@Bean public Job myJob() { return jobBuilderFactory.get("myJob") .start(myStep()) .build(); } @Bean public Step myStep() { return stepBuilderFactory.get("myStep") .<InputType, OutputType>chunk(10) .reader(itemReader) .processor(itemProcessor) .writer(itemWriter) .build(); }
d. 配置ItemReader、ItemProcessor、和ItemWriter: 在Step的定义中,配置ItemReader用于读取数据,ItemProcessor用于处理数据,ItemWriter用于写入数据。你可以使用Spring Batch提供的现成组件,或者自定义这些组件以满足你的需求。
e. 启动作业: 最后,你可以使用Spring的ApplicationContext来获取作业并启动它:
JobLauncher jobLauncher = context.getBean(JobLauncher.class); Job job = context.getBean("myJob", Job.class); JobParameters jobParameters = new JobParametersBuilder() .addString("jobID", String.valueOf(System.currentTimeMillis())) .toJobParameters(); JobExecution jobExecution = jobLauncher.run(job, jobParameters);
这将启动名为"myJob"的作业,并将其执行。
2. 关键概念的解释:
- Job(作业):表示一个完整的批处理任务,包含一个或多个Step。作业定义了批处理任务的名称、参数等信息。
- Step(步骤):表示作业中的一个单独步骤,包括数据读取、处理和写入的逻辑。每个步骤由一个或多个ItemReader、ItemProcessor和ItemWriter组成。
- JobInstance(作业实例):表示作业的一次实际运行。每次启动作业时,都会创建一个新的JobInstance。
- JobExecution(作业执行):表示作业的一次执行。每次启动作业时,都会创建一个新的JobExecution,其中包含了作业执行的详细信息,如执行状态、开始时间、结束时间等。
- ItemReader(数据读取器):用于从数据源中读取数据,如数据库、文件等。
- ItemProcessor(数据处理器):用于对读取的数据进行处理和转换。
- ItemWriter(数据写入器):用于将处理后的数据写回到目标数据源或文件。
这些概念共同构成了Spring Batch的核心,允许你定义和管理复杂的批处理作业。每个概念都有其特定的任务和角色,而Spring Batch提供了许多内置组件,使配置和管理作业变得相对容易。
第三:item读取和写入
在Spring Batch中,ItemReader用于从数据源读取数据,而ItemWriter用于将数据写入目标存储。这些组件是批处理作业中的核心部分。以下是它们的解释和示例:
ItemReader(数据读取器)
ItemReader用于从数据源中读取数据,可以是数据库、文件、消息队列或任何其他数据源。Spring Batch提供了不同的ItemReader实现,可以根据需求选择适当的实现,或者自定义一个ItemReader。
以下是一个示例,使用JdbcCursorItemReader从数据库中读取数据:
@Bean public ItemReader<MyData> myDataReader(DataSource dataSource) { JdbcCursorItemReader<MyData> reader = new JdbcCursorItemReader<>(); reader.setDataSource(dataSource); reader.setSql("SELECT id, name, age FROM my_table"); reader.setRowMapper(new BeanPropertyRowMapper<>(MyData.class)); return reader; }
在上述示例中,我们配置了一个JdbcCursorItemReader来读取数据库中的数据,通过SQL查询获取数据,然后使用BeanPropertyRowMapper将查询结果映射到MyData对象。
ItemWriter(数据写入器)
ItemWriter用于将处理后的数据写入目标存储,这可以是数据库、文件、消息队列等。和ItemReader一样,Spring Batch提供了多种ItemWriter的实现,也支持自定义ItemWriter。
以下是一个示例,使用JdbcBatchItemWriter将数据写入数据库:
@Bean public ItemWriter<MyData> myDataWriter(DataSource dataSource) { JdbcBatchItemWriter<MyData> writer = new JdbcBatchItemWriter<>(); writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()); writer.setDataSource(dataSource); writer.setSql("INSERT INTO my_target_table (id, name, age) VALUES (:id, :name, :age)"); return writer; }
在上述示例中,我们配置了一个JdbcBatchItemWriter来将处理后的数据写入目标数据库表中。我们指定了SQL语句,以及如何将MyData对象的属性映射到SQL参数。
批处理Step配置
通常,ItemReader和ItemWriter会在Step中一起使用。下面是一个Step的配置示例,将ItemReader和ItemWriter组合在一起:
@Bean public Step myStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myStep") .<MyData, MyData>chunk(10) // 每次处理10条数据 .reader(reader) .processor(myDataProcessor) // 可选,用于数据处理 .writer(writer) .build(); }
在这个示例中,我们创建了一个Step(步骤)并使用ItemReader从数据源读取数据,可以使用ItemProcessor对数据进行处理,然后使用ItemWriter将数据写入目标存储。
通过这种方式,你可以配置复杂的数据处理流程,包括读取、处理和写入,以满足各种数据处理需求。Spring Batch的优点之一是它的可扩展性和灵活性,使你能够适应不同的数据处理场景。
第四:数据转换和处理
在Spring Batch中,你可以使用ItemProcessor来对读取的数据进行转换和处理。ItemProcessor是一个中间组件,它接收从ItemReader读取的数据,执行自定义的逻辑,然后将处理后的数据传递给ItemWriter进行写入。下面是演示如何使用ItemProcessor进行数据转换和应用自定义逻辑的示例:
1. 创建自定义的ItemProcessor:
首先,你需要创建一个自定义的ItemProcessor类,实现ItemProcessor<InputType, OutputType>接口,其中InputType和OutputType是你要处理的数据类型。下面是一个示例的ItemProcessor,它用于将字符串转为大写:
public class MyDataProcessor implements ItemProcessor<String, String> { @Override public String process(String item) throws Exception { // 在这里编写自定义逻辑,这里示例将字符串转为大写 return item.toUpperCase(); } }
2. 在Step中应用自定义Processor:
接下来,在Step的配置中,将自定义的ItemProcessor应用于数据处理。以下是Step的配置示例:
@Bean public Step myStep(ItemReader<String> reader, ItemWriter<String> writer, ItemProcessor<String, String> processor) { return stepBuilderFactory.get("myStep") .<String, String>chunk(10) // 每次处理10条数据 .reader(reader) .processor(processor) // 使用自定义的ItemProcessor .writer(writer) .build(); }
在这个示例中,我们将自定义的MyDataProcessor应用于Step的processor部分。这意味着在读取数据后,每个数据项都会被送到MyDataProcessor中进行处理,然后将处理后的结果传递给ItemWriter进行写入。
3. 完整示例:
这是一个完整的示例,演示了如何在Spring Batch中使用自定义的ItemProcessor来处理数据:
@Configuration @EnableBatchProcessing public class BatchConfig { @Bean public ItemReader<String> myDataReader() { // 定义ItemReader,读取数据源 } @Bean public ItemProcessor<String, String> myDataProcessor() { return new MyDataProcessor(); // 使用自定义的ItemProcessor } @Bean public ItemWriter<String> myDataWriter() { // 定义ItemWriter,将数据写入目标存储 } @Bean public Step myStep(ItemReader<String> reader, ItemWriter<String> writer, ItemProcessor<String, String> processor) { return stepBuilderFactory.get("myStep") .<String, String>chunk(10) // 每次处理10条数据 .reader(reader) .processor(processor) // 使用自定义的ItemProcessor .writer(writer) .build(); } @Bean public Job myJob(JobCompletionNotificationListener listener, Step myStep) { return jobBuilderFactory.get("myJob") .incrementer(new RunIdIncrementer()) .listener(listener) .flow(myStep) .end() .build(); } }
在这个示例中,我们定义了一个自定义的MyDataProcessor用于数据转换和处理,然后将它应用于Step的配置中。整个作业由Job包装,用于启动和执行。
通过这种方式,你可以应用自定义逻辑来处理数据,例如数据转换、验证、计算等,以满足具体的业务需求。
第五:作业流程控制
在Spring Batch中,作业流程控制是一种强大的方式,可以根据不同的条件、决策以及在作业生命周期中的各个阶段插入监听器来实现复杂的作业逻辑。以下是关于作业流程控制的讨论,包括条件步骤、决策器和监听器。
条件步骤(Conditional Steps):
条件步骤允许你在作业执行期间根据特定条件来决定是否执行某个步骤。你可以使用Flow和JobExecutionDecider来实现条件步骤。以下是一个简单的示例:
@Bean public Job myJob(JobBuilderFactory jobBuilderFactory, Step step1, Step step2) { return jobBuilderFactory.get("myJob") .start(step1) .next(decider()) // 使用决策器来决定下一步是step2还是其他步骤 .from(decider()).on("YES").to(step2) .from(decider()).on("NO").end() .end() .build(); } @Bean public JobExecutionDecider decider() { return new MyDecider(); }
在上述示例中,MyDecider是一个自定义的决策器,根据某些条件返回不同的结果(例如,“YES"或"NO”)。作业在执行时,将依据这个决策来决定是执行step2还是结束作业。
决策器(Decider):
决策器是一个自定义的组件,实现JobExecutionDecider接口,用于根据条件来决定下一个步骤。你可以在决策器中编写任何逻辑,根据你的需求来决定下一步的执行。下面是一个简单的决策器示例:
public class MyDecider implements JobExecutionDecider { @Override public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) { if (someCondition) { return new FlowExecutionStatus("YES"); } else { return new FlowExecutionStatus("NO"); } } }
监听器(Listeners):
Spring Batch提供了各种类型的监听器,用于在作业执行的不同阶段触发自定义逻辑。监听器包括JobExecutionListener、StepExecutionListener和ChunkListener等。你可以使用这些监听器来监控和干预作业的执行。
例如,你可以创建一个JobExecutionListener来在作业开始或结束时执行某些操作:
public class MyJobListener implements JobExecutionListener { @Override public void beforeJob(JobExecution jobExecution) { // 在作业开始前执行的逻辑 } @Override public void afterJob(JobExecution jobExecution) { // 在作业结束后执行的逻辑 } }
实现复杂的作业逻辑:
通过组合条件步骤、决策器和监听器,你可以实现复杂的作业逻辑。例如,你可以创建一个作业,根据某些条件决定执行不同的步骤,同时在作业的不同阶段使用监听器来执行特定的操作。
复杂的作业逻辑可能涉及多个条件步骤,决策器可以帮助你在不同步骤之间做出决策。同时,监听器可以用于记录、通知或执行额外的逻辑。
总之,Spring Batch提供了强大的工具和灵活性,允许你在作业流程中实现复杂的逻辑。这对于需要复杂条件控制和定制行为的数据处理任务非常有用。
第六:容错处理
Spring Batch提供了强大的容错处理机制,以处理作业执行过程中的故障和异常情况。两个常见的容错处理方式包括重试和跳过,下面是关于这些机制的介绍:
重试(Retry)
重试是一种容错处理机制,允许在发生异常时重新执行某个步骤或任务。Spring Batch允许你配置在什么情况下以及如何进行重试。以下是一个示例:
@Bean public Step myStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .faultTolerant() .retry(Exception.class) // 在遇到Exception时进行重试 .retryLimit(3) // 最多重试3次 .build(); }
在上述示例中,我们使用faultTolerant()来启用容错处理,然后配置了重试机制。这表示如果在步骤执行时抛出了Exception,将最多重试3次。你可以根据需要自定义异常类型和重试次数。
跳过(Skip)
跳过是另一种容错处理机制,它允许在遇到异常时跳过一定数量的记录,然后继续执行。你可以配置哪些异常会导致跳过以及跳过的记录数。以下是一个示例:
@Bean public Step myStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .faultTolerant() .skip(Exception.class) // 在遇到Exception时跳过 .skipLimit(10) // 最多跳过10次 .build(); }
在上述示例中,我们使用faultTolerant()启用容错处理,并配置了跳过机制。这表示如果在步骤执行时抛出了Exception,将最多跳过10次。
处理故障和异常情况
在Spring Batch中,你还可以使用监听器来处理故障和异常情况。例如,你可以实现SkipListener,RetryListener或StepExecutionListener等监听器来记录、通知或执行特定的逻辑,以响应重试或跳过操作。
下面是一个简单的示例,如何实现SkipListener来处理跳过操作:
public class MySkipListener implements SkipListener<MyData, MyData> { @Override public void onSkipInRead(Throwable t) { // 在读取数据时发生跳过时执行的逻辑 } @Override public void onSkipInWrite(MyData item, Throwable t) { // 在写入数据时发生跳过时执行的逻辑 } @Override public void onSkipInProcess(MyData item, Throwable t) { // 在处理数据时发生跳过时执行的逻辑 } }
然后,你可以在步骤的配置中添加这个监听器,以处理跳过情况:
@Bean public Step myStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .faultTolerant() .skip(Exception.class) .skipLimit(10) .listener(mySkipListener) // 添加跳过监听器 .build(); }
通过配置重试、跳过以及使用监听器,你可以有效地处理作业执行期间的故障和异常情况,确保数据处理作业在出现问题时仍然能够顺利进行。这对于处理不稳定数据源或复杂数据处理逻辑非常有用。
第七:批处理监控和管理
监控和管理Spring Batch作业是确保批处理系统稳定运行的关键部分。以下是使用Spring Boot Actuator和其他工具来监控和管理批处理作业的方法:
使用Spring Boot Actuator
Spring Boot Actuator是Spring Boot的子项目,它提供了监控和管理Spring Boot应用程序的功能,包括Spring Batch作业。你可以使用Actuator来监控作业的运行状态、指标和端点。以下是如何配置Spring Boot Actuator以监控Spring Batch作业:
a. 添加Spring Boot Actuator依赖:
在pom.xml中添加Spring Boot Actuator依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>
b. 配置Actuator端点:
在application.properties或application.yml中,配置Actuator端点的启用和安全性。例如,你可以启用/actuator路径下的job-executions端点以监控作业执行情况:
management: endpoints: web: exposure: include: job-executions
c. 使用Actuator监控:
启动应用程序后,你可以通过访问/actuator/job-executions端点来监控作业的执行情况。这将提供有关作业执行状态、持续时间和其他相关信息的数据。
使用Spring Batch Admin
Spring Batch Admin是一个Web应用程序,用于管理和监控Spring Batch作业。它提供了图形用户界面(GUI),允许你查看作业、启动作业、监控作业执行进度和查看作业执行历史。以下是如何使用Spring Batch Admin:
a. 添加Spring Batch Admin依赖:
在pom.xml中添加Spring Batch Admin依赖:
<dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-admin-resources</artifactId> <version>2.0.0.BUILD-SNAPSHOT</version> <!-- 请使用适当的版本 --> </dependency>
b. 配置Spring Batch Admin:
创建一个Spring Boot配置类,用于配置Spring Batch Admin:
@Configuration @EnableAutoConfiguration @ComponentScan public class BatchAdminConfiguration { // 配置Spring Batch Admin }
c. 启动Spring Batch Admin应用:
启动应用程序后,你可以访问Spring Batch Admin的Web界面,通常是http://localhost:8080/spring-batch-admin/,然后登录并使用GUI来管理和监控作业。
Spring Batch Admin提供了一种更全面的方式来管理和监控批处理作业,适合那些需要集中管理和监控大量作业的场景。
无论你选择使用Spring Boot Actuator还是Spring Batch Admin,都能帮助你更有效地监控和管理Spring Batch作业,以确保作业正常运行并及时处理问题。
第八:并行处理
在Spring Batch中,可以通过多种方式实现并行处理以加速大规模数据处理。以下是一些方法和技巧:
1. 多线程Step处理:
一种常见的并行处理方式是将作业中的步骤(Step)配置为多线程处理。通过将一个步骤拆分为多个线程,每个线程可以独立处理数据的一部分。这可以显著提高处理速度,特别是在具有多核CPU的系统上。
以下是一个示例,如何配置一个多线程Step:
@Bean public Step myParallelStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myParallelStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .taskExecutor(taskExecutor()) // 配置任务执行器以实现多线程处理 .throttleLimit(4) // 设置并行处理的线程数 .build(); } @Bean public TaskExecutor taskExecutor() { ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor(); taskExecutor.setCorePoolSize(4); // 设置线程池的核心线程数 taskExecutor.setMaxPoolSize(8); // 设置线程池的最大线程数 taskExecutor.afterPropertiesSet(); return taskExecutor; }
在上述示例中,我们配置了一个myParallelStep步骤,使用taskExecutor()定义的任务执行器来实现多线程处理。throttleLimit(4)指定了并行处理的线程数。
2. 分区步骤(Partitioning):
Spring Batch还提供了分区步骤,允许将大数据集拆分成多个分区,并在不同的线程上并行处理这些分区。这对于大规模数据处理非常有用。
以下是一个示例,如何配置一个分区步骤:
@Bean public Step myPartitionStep() { return stepBuilderFactory.get("myPartitionStep") .partitioner("workerStep", partitioner()) // 配置分区器 .step(workerStep()) .gridSize(4) // 设置分区的数量 .taskExecutor(taskExecutor()) // 配置任务执行器 .build(); } @Bean public Partitioner partitioner() { return new MyPartitioner(); // 自定义分区器 } @Bean public Step workerStep() { return stepBuilderFactory.get("workerStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .build(); }
在上述示例中,我们配置了一个分区步骤myPartitionStep,使用自定义分区器MyPartitioner将数据集分为多个分区,并配置多线程执行。
3. 远程分区(Remote Partitioning):
对于更复杂的并行处理需求,可以使用远程分区,将不同步骤的分区分布在不同的计算节点上执行。这对于分布式系统中的大规模数据处理非常有用。
远程分区的配置比较复杂,需要使用Spring Batch的远程分区支持以及消息中间件等技术来实现。你需要定义分区步骤、远程工作节点和通信机制等。
以上是一些在Spring Batch中实现并行处理的方法。具体的选择取决于你的应用场景和需求。无论你选择哪种方法,都可以加速大规模数据处理,并更有效地利用多核系统的性能。
第九:数据验证和校验
在Spring Batch中,你可以执行数据验证和校验以确保数据的完整性和质量。数据验证和校验通常在读取数据(ItemReader)后,但在数据写入(ItemWriter)之前进行。以下是一些方法和技巧,以实现数据验证和校验:
使用ItemProcessor进行数据验证
你可以创建一个自定义的ItemProcessor,并在其中编写数据验证和校验逻辑。ItemProcessor允许你在处理数据之前对每个数据项进行验证和转换。
以下是一个示例,如何创建一个ItemProcessor来验证数据:
public class DataValidator implements ItemProcessor<MyData, MyData> { @Override public MyData process(MyData item) throws Exception { // 进行数据验证和校验 if (item.isValid()) { return item; // 数据有效,返回原始数据 } else { return null; // 数据无效,跳过该数据 } } }
在上述示例中,我们创建了一个DataValidator,它验证MyData对象是否有效,如果无效则返回null,从而跳过该数据。
使用Skip机制
Spring Batch提供了跳过(Skip)机制,允许你在遇到无效数据时跳过它们。你可以配置哪些异常会导致跳过以及跳过的记录数。
以下是一个示例,如何配置Step来使用跳过机制:
@Bean public Step myStep(ItemReader<MyData> reader, ItemWriter<MyData> writer) { return stepBuilderFactory.get("myStep") .<MyData, MyData>chunk(10) .reader(reader) .processor(myDataProcessor) .writer(writer) .faultTolerant() .skip(DataValidationException.class) // 配置要跳过的异常类型 .skipLimit(10) // 最多跳过10次 .build(); }
在上述示例中,我们配置了myStep步骤,使用跳过机制来跳过DataValidationException异常,最多跳过10次。
自定义验证器
除了ItemProcessor和Skip机制,你还可以创建自定义验证器来进行更复杂的数据验证。自定义验证器可以在Step的监听器中执行,例如StepExecutionListener。
以下是一个示例,如何创建自定义验证器:
public class DataValidatorListener implements StepExecutionListener { @Override public void beforeStep(StepExecution stepExecution) { // 在步骤开始前执行的逻辑 } @Override public ExitStatus afterStep(StepExecution stepExecution) { // 在步骤结束后执行的逻辑,包括数据验证和校验 for (MyData item : stepExecution.getReadSkipCount()) { if (!item.isValid()) { // 数据无效,执行处理逻辑,例如记录日志或通知 } } return stepExecution.getExitStatus(); } }
在上述示例中,我们创建了一个DataValidatorListener,它在步骤结束后对数据进行验证和校验,并执行相应的逻辑。
通过以上方法,你可以在Spring Batch中执行数据验证和校验,确保数据的完整性和质量。这对于处理不完整或无效数据非常有用,可以帮助保持数据一致性和质量。
第十: 最佳实践和性能优化
编写高效的批处理作业和性能优化是非常重要的,特别是在处理大规模数据时。以下是一些最佳实践和性能优化策略:
1. 使用适当的数据源:
选择适合你数据量和性能需求的数据源。如果数据存储在关系型数据库中,考虑使用合适的数据库引擎和索引来提高读取和写入性能。使用连接池来管理数据库连接,以减少连接开销。
2. 合理设置Chunk大小:
在Step中,合理设置chunk的大小是很重要的。chunk定义了一次处理的数据记录数,设置合适的chunk大小可以最大程度地利用系统资源,避免过多的内存占用。通常,chunk的大小应根据系统内存和数据处理需求进行调整。
3. 启用并行处理:
如前所述,在大规模数据处理中启用并行处理是一种有效的性能优化策略。你可以使用多线程Step处理、分区步骤或远程分区等方法来实现并行处理,以更充分地利用多核CPU。
4. 缓存和数据预加载:
在批处理作业开始前,考虑预加载一部分数据到内存中,以减少读取外部数据源的频率。这可以提高数据访问速度。同时,合理使用缓存来减少数据库或外部数据源的访问。
5. 数据过滤和清洗:
在批处理开始前,进行数据过滤和清洗,排除不需要处理的数据或处理无效数据。这可以减少数据处理的复杂性和资源占用。
6. 监控和日志记录:
实施有效的监控和日志记录策略,以及时发现问题并进行性能分析。Spring Batch提供了许多监控选项,也可以使用第三方监控工具。
7. 异常处理和重试:
实现适当的异常处理和重试策略,以应对可能的错误情况。在配置步骤时,使用faultTolerant()和skip等机制来处理异常和错误数据。
8. 批处理分区和分片:
将作业分成多个批处理分区或分片,每个分区独立运行。这可以提高作业的并行性和性能。
9. 使用索引和查询优化:
如果你使用关系型数据库,确保数据库表中有适当的索引以加速数据读取。同时,编写高效的SQL查询,避免不必要的查询和数据加载。
10. 定期优化数据库:
定期执行数据库维护操作,如索引重建和表优化,以保持数据库性能。
11. 增量加载和增量处理:
考虑实施增量加载和处理策略,只处理已更改的数据,而不是整个数据集。
12. 资源管理:
有效地管理系统资源,包括内存、CPU和磁盘空间。确保批处理作业不会耗尽系统资源。
13. 并行提交:
如果可能,提交多个作业并行执行,以充分利用资源。
综合使用这些最佳实践和性能优化策略,可以帮助你编写高效的批处理作业,提高数据处理性能,减少资源占用,同时确保数据质量和完整性。不同的应用场景可能需要不同的优化策略,因此根据具体需求进行调整和优化。
第十一:批处理案例研究
批处理在各种领域都有广泛的应用,以下是一些实际的批处理应用案例:
1. 日志分析: 大型网站和应用程序通常生成大量的日志文件,记录用户活动、性能指标和错误信息。批处理可以用于定期分析这些日志,提取有用的信息,如用户行为趋势、访问量、错误分析等。分析结果可以用于改进应用程序性能和用户体验。
2. 报表生成: 企业通常需要生成各种报表,如销售报表、财务报表、库存报表等。批处理可以用于从不同数据源中提取和汇总数据,然后生成定期或按需的报表。这些报表通常需要满足法规要求,因此数据质量和完整性至关重要。
3. 数据迁移: 当企业需要从一个系统迁移到另一个系统时,数据迁移是一个常见的批处理应用。这可能涉及将数据从一个数据库或文件中提取,转换为新系统的格式,然后加载到新系统中。数据迁移通常需要高度的数据质量和完整性。
4. 批量支付处理: 金融机构和支付服务提供商使用批处理来处理大量的付款和交易。这包括工资支付、账单支付、电子转账等。批量支付处理需要高度的安全性和可靠性,以确保资金的正确分配。
5. 数据清洗和标准化: 组织通常需要将从不同来源获得的数据进行清洗和标准化,以确保数据的一致性和质量。批处理可以用于去重、格式化、校验和标准化数据,以满足特定的数据标准和规范。
6. ETL(提取、转换、加载)流程: ETL过程是将数据从一个系统提取、进行转换和最后加载到另一个系统的过程。这在数据仓库、商业智能和数据分析应用中非常常见。批处理作业用于执行ETL流程,以支持数据分析和决策。
7. 批量邮件发送: 市场营销团队使用批处理来发送大量的电子邮件,如广告、营销活动、新闻简报等。这些批处理作业需要高效地处理大量的邮件,并确保邮件的投递和反馈数据的记录。
8. 订单处理: 在电子商务和供应链管理中,订单处理是一个关键的批处理应用。订单通常需要验证、处理和记录,以确保及时交付和库存管理。
这些案例只是批处理应用中的一小部分示例。批处理在各种行业和领域都有广泛的应用,帮助组织处理大量数据、自动化重复任务和确保数据质量。每个案例都有其特定的需求和挑战,因此需要根据具体情况进行定制和优化。