向量检索服务 DashVector 免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector
理解Partition
向量检索服务DashVector的Collection具有分区(Partition)的能力,同一个Collection下的Doc可通过不同的Partition进行物理和逻辑上的分区。各种Doc操作(如插入Doc、检索Doc等)若指定Partition,则该操作将限定在该指定的Paritition内进行。通过合理的Partition设置,可有效提升Doc操作的效率。
- 同一个Collection下,可以创建若干个Partition,具体限制见约束与限制;
- 每个Partition通过唯一的名称进行标识,同一个Collection下的Partition名称不可重复;
- 同一个Collection下的所有Partition,具有相同的Schema,如向量维度、向量数据类型、度量方式、Fields定义等;
- 每个Collection默认自带一个无法删除的Partition,当各种Doc操作(如插入Doc、检索Doc等)不指定Partition时,等价于使用该默认Partition;
- Partition需通过API调用显示的创建和删除。
Partition使用场景举例
在Collection中使用Partition能显著提高Query的性能,但并非所有场景都建议使用。当数据量较小时,使用Partition收益不明显。当数据量较大、但没有合适的划分字段时,同样不建议使用Partition。例如,如果没有合适的划分字段但又设置了多个Partition时,检索时可能需要跨多个Partition进行多次Query,检索性能将低于单个Partition的一次Query。
下面列举几个典型的适合Partition场景供参考:
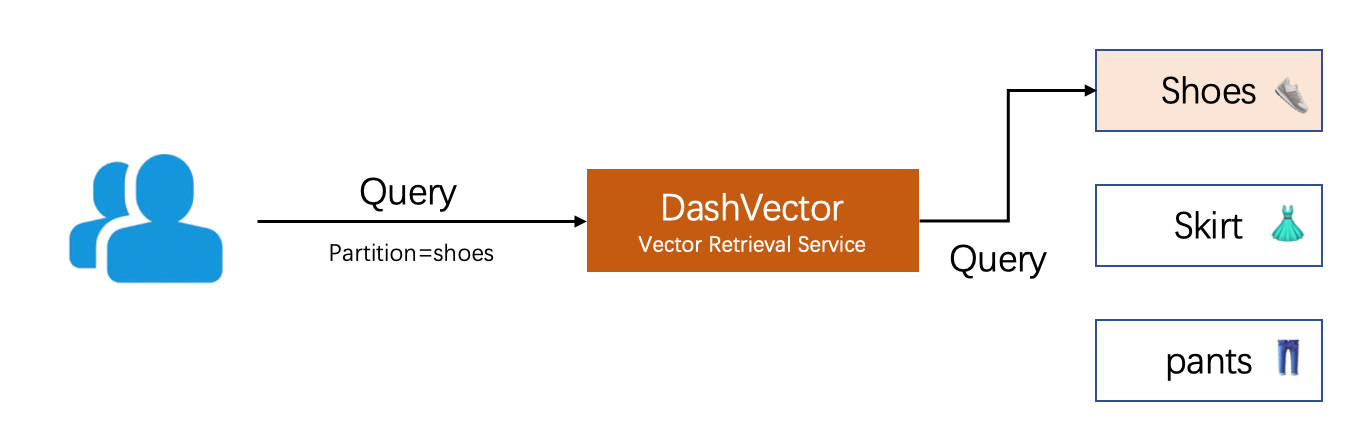
电商图搜场景
例如某跨境电商用户,有2000w服装商品图片,需要实现以图搜图业务场景。商品有固定多个分类(鞋子,裙子,裤子等),商品提特征后按类别入库,每个分类对应一个Partition,查询时用户显示指定类别或用户不指定由分类模型确定类别。
视频监控场景
例如某视频监控厂商,需要对一工业园区的1000个摄像头采集的视频进行抽帧,识别提取车辆特征后,导入DashVector向量库用于后续搜索,生成车辆轨迹等业务场景,但数据只需保留30天,按日期每天创建Partition,并定期删除过期的Partition。

商标侵权检测
例如某商标代理商收集了一个5000w规模的商标数据库,需要快速查询相似商标判定是否侵权。按结构分为文本商标、图形商标、数字商标、字母商标等9个分类,每个分类数据入库DashVector时对应一个Partition。查询时指定Partition,只从特定类别中查询。
多语言问答系统
某电商国际化知识库团队,需要根据用户所使用的语言类别来查询对应语言的相似问题,比如要支持中文、英文、法文三种语言。在知识库内容经过Embedding后,分别导入Chinese、English、French三个Partition中,查询时,根据用户所使用的语言类别选择对应的Partition进行查询。
多租户
Partition也可用来支持多租户场景。例如某电商服务商为其下小微电商提供以图搜图能力,可在一个Collection中创建多个Partition对应多个客户,实现了数据的物理隔离、保证安全的同时,又节约了成本。
Partition使用示例
前提条件
- 已创建Cluster:创建Cluster。
- 已获得API-KEY:API-KEY管理。
- 已安装最新版SDK:安装DashVector SDK。
代码示例
说明
需要使用您的api-key替换示例中的 YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
import dashvector # 创建Client client = dashvector.Client( api_key='YOUR_API_KEY', endpoint='YOUR_CLUSTER_ENDPOINT' ) assert client # 创建Collection client.create(name='understand_partition', dimension=4) collection = client.get('understand_partition') assert collection # 创建Partition,Partition名称为shoes collection.create_partition(name='shoes') # 描述Partition ret = collection.describe_partition('shoes') print(ret) # 查看Partition列表 partitions = collection.list_partitions() print(partitions) # 插入Doc至Partition collection.insert( ('1', [0.1,0.1,0.1,0.1]), partition='shoes' ) # 向量相似性检索时指定Partition docs = collection.query( vector=[0.1, 0.1, 0.2, 0.1], partition='shoes' ) print(docs) # 从指定Partition中删除Doc collection.delete(ids=['1'], partition='shoes') # 查看Partition统计数据 ret = collection.stats_partition('shoes') print(ret) # 删除Partition collection.delete_partition('shoes')
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

