【计算机系统基石与Linux进程管理深度解析】(二):https://developer.aliyun.com/article/1425712
3.5.通过系统调用创建进程-fork初识
- 运行 man fork
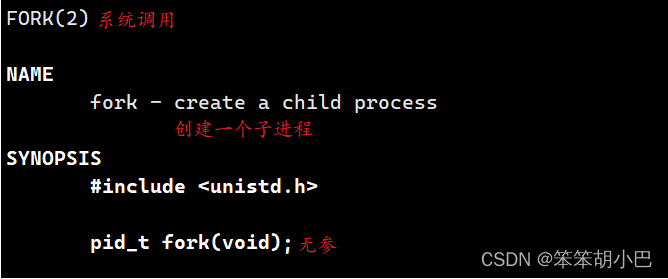
然后我们来初步使用一下fork函数。

运行一下,看一下会输出什么?

我们发现before输出了一遍,而after输出了两遍,我们可以得到一旦fork函数执行后,存在两个执行分支的,所以after会执行两次,我们发现第一次after输出的pid和ppid和before相同,说明它俩是同一个进程,第二次after输出的ppid和第一次输出的pid是一样的,说明第二次after是第一次after的子进程,它们之间存在父子关系。
上面的31564是命令行的进程,也就是我们的bash。

fork执行后有两个进程,父和子都会运行。那我们怎么知道哪一个是父进程,哪一个是子进程呢?
- 认识fork,fork有两个返回值

按照这个返回值的意义,那是不是有两个返回值,我们来验证一下

这里就要问一下,这里访问的是同一个变量,为什么能返回两个值呢?这个我们暂时当成这个函数的特性。我们待会讲。这里要提一个问题,我们为什么要创建子进程?
通过创建子进程,可以在一个程序中并行执行多个任务。每个子进程都有自己的独立内存空间和执行上下文,因此它们可以同时执行不同的代码块,与自己的父进程互补干扰,这样我们的子进程和父进程就能执行不同的任务。
- 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
那怎么分别执行呢?通过返回值使用if进行分流即可,让父子执行不同的代码块
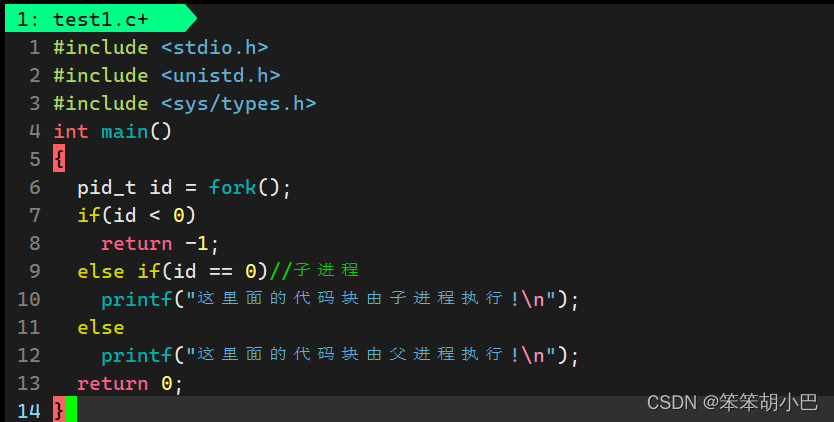
于是这样就执行了我们子进程和父进程的代码。

我们知道代码无法执行两个死循环,但是今天我们可以通过父子进程去实现,fork 之后通常要用 if 进行分流。

我们可以看到父子进程中两个死循环同时执行了,可以证明fork后此时有两个执行流。那我们怎么理解上面的父子进程代码共享呢?
进程 = 内核数据结构 + 可执行程序和数据。当父进程创建一个进程的时候,系统中就多了一个进程,系统调用使用 fork 创建子进程时,子进程将会复制父进程的可执行程序的代码。这种复制是通过写时复制(Copy-on-Write,COW)实现的,同时PCB相关的属性子进程也会拷贝父进程的task_struct属性。

上面的这个代码都是又父进程提供的,只不过通过fork函数的返回值来让父子执行不同的代码块。子进程被创建,是以父进程为模板的!!!现在再来讲一下fork函数。

关于第三点,我们可以验证一下,父子进程共享代码,因此父进程挂掉了,子进程还可以运行,说明父子进程之间运行具有独立性,且在运行期间不能相互影响。当我们对应的父进程或者子进程尝试对某一个变量做写入的时候,因为子进程拷贝了父进程的代码,且如果这个数据是父子进程共享的,那么就会在操作系统发生写时拷贝,此时父子进程使用两个不同的地址空间。此时就可以用同一个变量名,表示不同的内存,而fork的返回值,实际上就是写入,本质也就是写入到id变量中,这也就是上面提到的数据各自开辟空间,私有一份(采用写时拷贝)。

注:写时拷贝通常应用于数据的共享,而不是可执行程序的共享。
我们现在来写一个代码从创建到退出的过程。

我们上面的代码时创建10个进程,让每个进程执行一下worker函数,当每个进程执行完worker函数后,自行退出程序。

4.进程状态
4.1.轻量级的聊一下排队 --- 队列
我们首先来了解一下进程排队,进程 = 内核数据结构 + 可执行程序代码和数据,但是进程不是一直运行的,我们可以验证一下。

上面的进程就没有一直运行,可能在等待某种软硬件资源,我们上面的程序就在等待键盘资源的输入,如果键盘资源没有准备好,这个进程就不会被调度,不会往后运行,所以上面的进程才会卡住。所以我们的程序加载到内存后,并不会一直运行。
即使进程虽然放在了CPU上,但也不是一直运行的。这里举一个例子我们就可以知道,我们现在的电脑是一个CPU的话,当我们写一个死循环的代码时,当CPU调度这个死循环进程的时候,此时CPU应该就被占满了,其他进程应该就不会被CPU执行,可事实上,我们发现CPU调度这个死循环进程的时候,电脑可能稍微会卡顿一下,但是其他应用软件依然能被执行。我们的进程一旦被CPU调用的时候,并不一定要等这个进程执行完才能调度下一个进程。
操作系统使用一种叫做时间片轮转的调度算法。每个进程被分配一个小的时间片,称为时间片量,来在CPU上运行。当时间片用尽时,操作系统会挂起当前运行的进程,将CPU分配给下一个等待执行的进程。这种切换会在短时间内发生很多次,使得每个进程都有机会执行。
我们再来回归本题:进程为什么要排队?
进程排队一定是在等待某种资源(CPU或者软硬件资源),进程 = 内核数据结构 + 可执行程序代码和数据,进程排队实际上是内核数据结构,也即是task_struct在排队,因为它是描述进程结构体的一个对象。比如在未来我们找工作的时候,我们将我们的简历投递给公司,本身是将我们的属性数据给到hr,当我们的hr看第一份简历的时候,其余九个人的简历就在排队,等待hr这个资源,说是简历在排队,实际上就是我们的属性数据在排队。只要是排队,一定是进程的task_struct进行排队。
一个进程的PCB已经链入到链表里,排队的时候又要链入到队列里,这是不是就有点绕?
一个task_struct可以被链入多种数据结构。其实上面这个很好解释,我们在数据结构里面就学习了链表的相关操作,而在队列的学习过程,我们的队列就是使用链表去实现"先进先出"的这个特性,所将一个进程的PCB首先链接到PCB链表,然后再将其链接到队列,可能看起来有些绕,但这是为了灵活性和效率考虑的一种设计。PCB链表用于维护系统中所有进程的信息,而队列则用于管理进程的调度和执行顺序。将PCB链接到链表是为了方便系统整体的管理,而将其链接到队列则是为了按照一定的策略进行调度。
在Linux内核中,每一个进程task_struct不是被链入到单链表中,而是我们的双链表中。
这里双链表和数据结构的双链表有一些区别,我们来画一下。

通过上面的双链表结构我们可以访问到struct listnode n,但是我们要使用的是task_struct t,我们需要获得整个PCB的属性信息呀,那这样怎么处理呀!我们下面举一个例子

所以求想知道整个PCB的属性信息,我们只需要找到task_struct t的地址即可。首先我们可以知道struct listnode n是task_struct t里面的一个变量,我们可以知道struct listnode n的地址,再求出struct listnode n的偏移量,就可以求出task_struct t的地址。
即可推出公式:&t = (int)&n - (int)&((task_struct*)0)->n;
一个task_struct可以被链入多种数据结构。我们现在再看这句话就好懂很多了。

一个进程的PCB已经链入到链表里,排队的时候又要链入到队列里,这是不是就有点绕?
再看这个问题就很简单了,虽然它是链表,但是我们可以改造一下它的插入和删除的特点,这样就是我们的队列,而队列的底层实现也是链表,所以task_struct可以被链入多种数据结构,我们可以将链入的众多链表中的一个当成我们的队列使用即可。此时PCB插入到链表中,就链接task_struct中的struct listnode双链表即可,排队的时候根据实现队列新的struct listnodel双链表链入即可。整个过程不用对task_struct进行任何修改。如果未来我们要删除一个进程,只需要在这个双链表中把当前进程这个节点 删除即可。
4.2.教材上关于进程的描述 ---运行、阻塞和挂起

我们先来了解"状态"这个名词

那何为运行状态呢?

一个进程只要在CPU的运行队列上,那么该进程就处于运行状态。一个进程处于运行状态并不是当前进程正在CPU上跑,当让,一个进程正在CPU上跑的时候这个进程一定是属于运行状态的。大部分操作系统中,只要进程被链入运行队列上排队,我们就可以称这个进程处于运行状态。
R:进程已经准备好随时被调度了。(此时就绪状态 等同于 运行状态,两个同为一个概念)
现在我们再来理解一下阻塞状态,要理解它,必须要从硬件方面谈起。首先第一个问题:硬件是如何管理的。先管理,再描述。
那我们就先管理呗!

然后再描述呗!!!

所以对硬件的管理就转化为对特定数据结构的管理。
当未来一个程序,内部有scanf函数,处于运行队列并且已经已经在CPU上跑了,当CPU执行到程序scanf函数,此时这个进程就不能再往后执行,因为当前scanf还没有收到用户输入,此时操作系统就将该进程从运行队列,状态由R变成非R(阻塞),然后将这个进程链入到键盘队列,所以这里的描述还要加一个设备队列。未来有其他程序需要网卡,就链入网卡队列。

设备也有队列哟!这不奇怪,CPU就有一个运行队列,CPU也是设备!!!CPU调度的时候不会调度scanf函数的那个进程,CPU只会调度运行状态的进程。所以当我们执行scanf函数的时候,终端就卡在那里,即没有被运行。那什么时候唤醒这个进程呢?硬件的就续状态只有操作系统最清楚!因为操作系统是硬件的管理者!当操作系统检测到键盘已经就绪,就会找键盘里面的队列,把该进程的阻塞状态改为运行状态,然后再将队列里面的第一个进程链入到CPU运行队列上,后面就静等CPU的调度,当CPU运行到该进程时,然后再执行scanf,此时键盘资源已经准备就绪(操作系统已经将scanf数据搬到内存了->就绪),所以就能直接获取到用户的输入,继续执行后面的代码。
当我们的进程在进行等待软硬件资源的时候,资源如果没有就绪,我们的进程task_struct只能将自己设置为阻塞状态,同时将自己的PCB连入等待软硬件资源提供的等待队列。状态的变迁, 引起的是PCB会被OS变迁到不同的队列中。
谈完阻塞状态,我们再来谈谈挂起状态。
我们先不说挂起状态是什么,但是挂起状态都有一个前提:计算机内存资源已经比较吃紧了,当我们的一个进程被连入等待软硬件资源提供的等待队列,变成阻塞状态,此时这个进程是不会执行的,此时计算机的内存已经很吃紧了,而这个进程代码和数据还占用内存,所以操作系统认为当前进程不会被调度,代码也不会被运行,操作系统此时会把代码和数据交换到外设磁盘中,当要被调度的时候,再换回内存,这个就是阻塞挂机,也就是阻塞的状态下,操作系统已经吃紧了。

在我们唤入(把数据拷贝到外设)唤出(数据从外设唤入到内存)【外设访问速度较慢:本质是拿计算机的效率换系统内存本身的可用性】的时候,我们的PCB不会被唤入唤出,如果我们唤入唤出的话,这个进程就不在当前内存执行队列中,我们就无法管理了,只有通过PCB我们才知道当前进程被唤入唤出,知道它是否再内存还是外设磁盘中。
创建进程是先创建我们的内核数据结构(PCB),然后再加载代码和数据,还是先加载代码和数据,再创建我们的内核数据结构(PCB)呢?
这里我们举一个例子,我们手机上的王者荣耀在手机磁盘上有20多个G,而我们的手机内存通常都是比磁盘空间小,就拿我的手机举例,手机运行内存只有8个G,我们如果想要运行王者荣耀的时候,那我们手机的运行内存直接就占满了,那么有的人说可以批量加载,确实可以,但是如果我们没有先创建我们的内核数据结构(PCB),我们怎么知道王者荣耀小程序被加载了多少,还有多少需要加载,当前进程应不应该调度呢?在这里我们可以用上面的挂起状态解释,当我们的进程创建了内核数据结构(PCB),没有代码和数据也不影响,因为我们这个进程没有代码和数据的时候,这个进程在未来操作系统不紧张的时候还可以被唤入,此时再调度就行。所以先创建我们的内核数据结构(PCB),然后再加载代码和数据。只有创建一个进程的内核数据结构(PCB),操作系统内部就知道这个进程已经有了。此时有PCB我们就知道王者荣耀小程序被加载了多少,还有多少需要加载,当前进程应不应该调度,然后在慢慢加载后面的代码。
4.3.Linux下具体的进程状态,具体看看什么是运行,什么是阻塞,什么是挂起
看看Linux内核源代码怎么说
为了弄明白正在运行的进程是什么意思,我们需要知道进程的不同状态。一个进程可以有几个状态(在 Linux内核里,进程有时候也叫做任务)。 下面的状态在kernel源代码里定义:
/* * The task state array is a strange "bitmap" of * reasons to sleep. Thus "running" is zero, and * you can test for combinations of others with * simple bit tests. */ static const char * const task_state_array[] = { "R (running)", /* 0 */ "S (sleeping)", /* 1 */ "D (disk sleep)", /* 2 */ "T (stopped)", /* 4 */ "t (tracing stop)", /* 8 */ "X (dead)", /* 16 */ "Z (zombie)", /* 32 */ };
- R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
- S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptible sleep))。
- D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的 进程通常会等待IO的结束。
- T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可 以通过发送 SIGCONT 信号让进程继续运行。
- X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
【计算机系统基石与Linux进程管理深度解析】(四):https://developer.aliyun.com/article/1425722


