1. 背景
自ChatGPT崛起以来,作为强大的大语言模型(Large Language Model, LLM),它引发了自然语言处理领域研究和应用的新浪潮。尤其是随着ChatGLM、LLaMA等开源的较小规模LLM的出现,更多的人都能够运行和应用这些模型。
在模型训练中,高质量的数据集变得越来越重要。然而,当前中文数据集的缺乏对于中文大模型和业界模型的支持产生了很大的影响,为了解决这个问题,阿里云计算巢数据集特别整理了一些业界开源的中文数据集供大家下载和使用。我们还将逐步拓展更多分类和场景的数据集,并欢迎大家上传和维护自己的数据集。
计算巢数据集是一个高效获取数据集的解决方案,旨在加速企业在人工智能、大数据和云计算(AIGC)创新转型过程中的数据处理环节。本文将介绍计算巢数据集在加速企业AIGC创新转型中的重要价值和应用场景。
在快速发展的AIGC领域中,数据集的获取和处理对于训练和定制化大模型来说至关重要。然而,传统的数据集获取方式面临着诸多挑战,如数据来源分散、获取效率低下、数据质量难以保证等。这些问题严重影响了企业的创新转型和模型训练的效率。
2. 计算巢数据集优势
计算巢数据集通过提供高效、智能的数据集获取和管理方式,能够显著加速企业AIGC创新转型过程中的数据处理工作。其核心优势包括:
1)高效数据集获取:计算巢数据集通过集成多种数据源和采集方式,能够快速获取所需的数据集,避免了企业在不同平台和系统中分散查找的麻烦,大大提高了数据获取的效率。
2)数据集自动化管理:计算巢数据集提供智能的数据集管理功能,能够自动处理数据集的清洗、去重、转换等任务,减轻了企业在数据预处理方面的工作量,提高了数据集的质量和可用性。
3)快速定制化大模型训练:计算巢数据集支持对数据集进行灵活的定制和筛选,帮助企业快速构建适合自身业务场景的训练数据集。这种高度定制化的训练数据集能够为企业的大模型训练提供更准确且有效的数据支持,加速了模型的训练和优化过程。
计算巢数据集在加速企业AIGC创新转型过程中具有广泛的应用场景。例如,在金融领域,企业可以利用计算巢数据集快速获取和处理大量的金融数据,用于建模和预测分析;在医疗领域,计算巢数据集可以协助医疗机构快速获取病例数据,支持精准医疗的研究和应用;在物流行业,企业可以利用计算巢数据集快速获取和处理交通、货物等数据,优化物流运营等。
接下来,让我们先介绍一下已经集成的数据集。然后,我们将详细介绍如何订阅并使用这些数据集,并展示在阿里云百炼平台上如何利用这些数据集进行常用或自定义模型的微调工作。
3. 数据集市场
3.1 中文医学指令精调数据集
简介:医学知识库围绕疾病、药物、检查指标等构建,字段包括并发症,高危因素,组织学检查,临床症状,药物治疗,辅助治疗等,可以利用该数据集对ChatGLM或者LLaMA模型进行训练,提高模型在医疗领域的问答效果。示例数据:
{"context": "问题:患者反复出现反酸、烧心等症状,考虑为Barrett食管,需要注意哪些并发症?\n回答: ", "target": "根据知识,Barrett食管的并发症包括消化性溃疡、反流食管炎、胃肠道出血、贫血、肿瘤等,需要引起注意。"} {"context": "问题:两岁女童出现发热、呼吸浅而快等症状,经过检查诊断为毛细支气管炎,治疗措施是什么?\n回答: ", "target": "给予鼻导管吸氧等方式进行支持治疗,并视情况使用抗生素治疗"} {"context": "问题:患者赵先生最近出现恶心、呕吐等症状,经过检查发现患有胆石性胰腺炎,是否会影响生育和生活?\n回答: ", "target": "胆石性胰腺炎对于生育和生活的影响并不大,但是如果没有得到及时和有效的治疗,病情可能会不断恶化,对患者的生活和健康造成更严重的影响。因此,需要及时进行治疗,并根据医生的建议进行饮食和生活方面的调整,以保持良好的身体状态和生活质量。"}
3.2 知乎问题答案数据集
简介:知乎问题答案,一个问题,多个答案,根据赞同数量排序。示例数据:

3.3 CMMLU - 中文多任务语言理解评估
简介:CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
示例数据:数据集中的每个问题都是一个多项选择题,有4个选项,只有一个选项是正确答案。数据以逗号分隔的.csv文件形式存在
Question |
A |
B |
C |
D |
Answer |
|
0 |
商业伦理学最早出现在 |
英国 |
法国 |
美国 |
意大利 |
C |
1 |
伦理学的核心是 |
宗教伦理学 |
描述伦理学 |
元伦理学 |
规范伦理学 |
D |
2 |
下列不属于人的基本权利的时 |
人格平等 |
独立 |
生命 |
自由 |
B |
3 |
关税的课税客体是 |
进出境的货物 |
消费者 |
海关 |
进出口商 |
A |
4 |
区域经济从本质上讲是 |
商品经济 |
一体化经济 |
信用经济 |
市场经济 |
D |
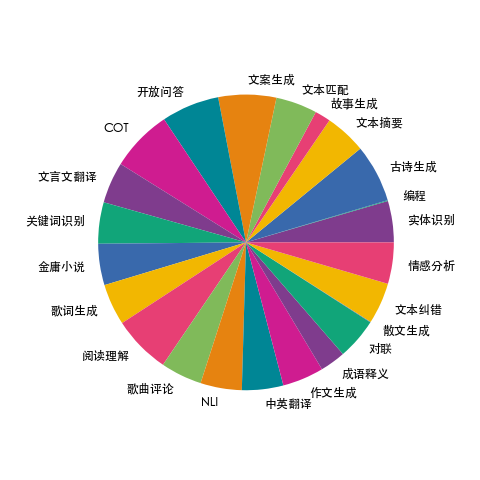
3.4 firefly-train-1.1M
简介:收集了23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万本数据应用于项目:Firefly(流萤): 中文对话式大语言模型,训练后得到的模型firefly-1b4
示例数据:
{"kind": "NLI", "input": "自然语言推理:\n前提:家里人心甘情愿地养他,还有几家想让他做女婿的\n假设:他是被家里人收养的孤儿", "target": "中立"} {"kind": "Summary", "input": "在上海的苹果代工厂,较低的基本工资让工人们形成了“软强制”的加班默契。加班能多拿两三千,“自愿”加班成为常态。律师提示,加班后虽能获得一时不错的报酬,但过重的工作负荷会透支身体,可能对今后劳动权利造成不利影响。\n输出摘要:", "target": "苹果代工厂员工调查:为何争着“自愿”加班"} {"kind": "Couplet", "input": "上联:把酒邀春,春日三人醉\n下联:", "target": "梳妆佩玉,玉王点一娇"} {"kind": "MusicComment", "input": "生成音乐热评", "target": "1、感謝大家支持!然後就是Jane的人聲真的太好聽了,remix很自然就做出來了哈哈。為了讓人聲情感突出,這版本並沒有用太多搶耳的音色,只保留了一點點自己bass風格的律動感,然後我拿起一把Fender吉他就已經是主旋律了。Anyway , 超榮幸能參與這張專輯的! Enjoy!\n2、这首\n有种退一步现世安稳,进一步天地广阔的感觉\n好适合拿去当剪辑的BGM\n在成长逐渐变得温柔又坚强的那种"}
数据分布如下
3.5 维基百科 - 中文
简介:104万个词条(1,043,224条; 原始文件大小1.6G,压缩文件519M;数据更新时间:2019.2.7) ,可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。示例数据:

3.6 百科类问答 - 中文
简介:含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。 可以做为通用中文语料,训练词向量或做为预训练的语料;也可以用于构建百科类问答;其中类别信息比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。
示例数据:

3.7 社区问答类 - 中文
简介:含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。
用途:
1)构建百科类问答:输入一个问题,构建检索系统得到一个回复或生产一个回复;或根据相关关键词从,社区问答库中筛选出你相关的领域数据 2)训练话题预测模型:输入一个问题(和或描述),预测属于话题。 3)训练社区问答(cQA)系统:针对一问多答的场景,输入一个问题,找到最相关的问题,在这个基础上基于不同答案回复的质量、 问题与答案的相关性,找到最好的答案。 4)做为通用中文语料,做大模型预训练的语料或训练词向量。其中类别信息也比较有用,可以用于做监督训练,从而构建更好句子表示的模型、句子相似性任务等。 5)结合点赞数量这一额外信息,预测回复的受欢迎程度或训练答案评分系统。
示例数据:

3.8 中英文翻译数据集
简介:中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。
示例数据:

3.9 新闻语料 - 中文
简介:包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。新闻内容跨度:2014-2016年
可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料;也可以用于训练【标题生成】模型,或训练【关键词生成】模型(选关键词内容不同于标题的数据); 亦可以通过新闻渠道区分出新闻的类型。
示例数据:

4. 数据集最佳实践
4.1 数据集订阅
选择对应的数据集卡片,点击进入详细介绍页面,在该页面可以看到数据集的详细介绍,点击右上角【订阅】按钮 同意订阅协议,即可完成该数据集的订阅,


4.2 数据集下载
访问计算巢官方网址,点击【数据集管理】菜单, 选择【我的订阅】,即可看到已经订阅的数据集,点击【详情】按钮,进入数据集详情页面,切换到数据集tab标签,可以看到所有的数据集,选中其中一个数据集,可以看到该数据集所有的版本记录,在此处可以进行导出数据集到OSS,或者点击【查看资产】进入版本详情页面下载数据集到本地




4.3 数据集使用
下面以中文医学指令精调数据集为例,展示在阿里云百炼大模型服务平台上进行微调的案例。
4.3.1 训练模型
- 首先访问阿里云百炼-> 模型中心 -> 模型管理-> 训练新模型

- 按照提示逐步进行操作。在第三步:训练数据, 将下载好的本地数据集上传,继续配置验证数据集、参数配置,然后就可以开始训练了。


4.3.2 模型部署和应用
- 等待模型训练状态为“训练成功”,点击“模型部署”部署训练的自定义模型

- 切换到应用中心:应用管理Tab,点击新增应用。找到上一步部署的自定义模型并完成创建。这里我们创建了一个名为“医学助手”的大模型应用。

- 点击“测试”可以验证训练效果。输入“中文医学指令精调数据集”中的问题,发现模型的回答与数据集一致,证明模型已经掌握了相关知识。




