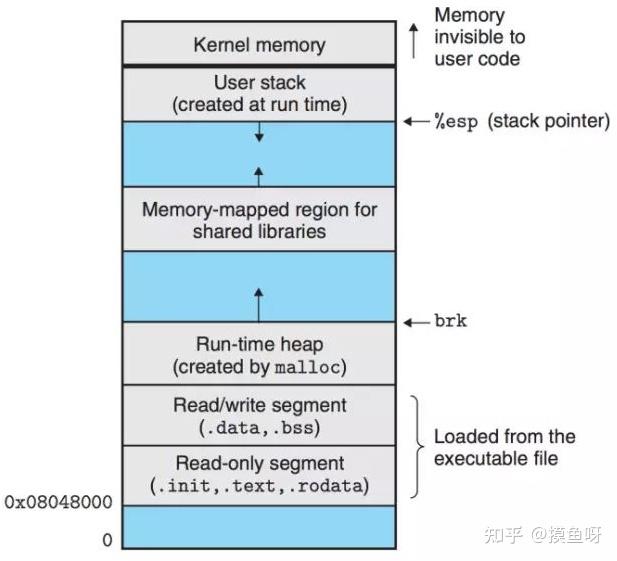
虚拟地址空间
- 内核空间:进程管理、设备管理、虚拟文件管理
- 用户空间
- 栈空间 stack:存储局部变量,函数参数
- 内存映射段 mmap:静态库与动态库,文件映射,匿名映射
- 堆空间 heap:malloc / calloc / new
- 读写段:全局变量、静态变量
- 只读段:文字常量区(字符串常量)和程序代码区(二进制代码)
* 堆和栈的区别
| 堆 | 栈 | |
| 管理方式 | 程序员手动控制,memory leak | 编译器管理 |
| 空间大小 | 内存区域不连续(空闲链表),受限于虚拟地址空间,例如:32 位系统 4 G | 内存区域连续,空间大小固定。操作系统预设,一般是 2 M。 |
| 内存管理 | 系统遍历内存空闲链表,寻找第一个大于所需空间的空闲结点,将其分配给程序。 | 栈的剩余空间大于申请空间,系统为程序提供内存,否则异常栈溢出。 |
| 碎片问题 | 频繁的内存申请释放,造成内存空间不连续,产生大量的碎片 | 栈后进先出,没有内存碎片 |
| 生长方向 | 堆向上生长,向高地址方向增长 | 栈向下生长,向低地址空间增长 |
| 分配方式 | 动态分配 | 系统提供静态和动态的方式 |
| 分配效率 | 效率低,间接寻址,第一次访问指针,第二次访问指针指向的内存 | 效率高,计算机底层提供支持(寄存器、指令等) |
内存分配
动态内存分配系统调用
int brk(void *addr); // 返回对的顶部地址 void *sbrk(intptr_t increment); // 扩展堆,increment 指定要增加的大小
先通过 sbrk 扩展堆,将这部分空闲内存空间作为缓冲池,然后通过 malloc/ free 管理缓冲池中的内存。
* malloc 原理
malloc 使用空闲链表组织堆中的空闲区块,每个内存区块由内存控制块 mem_control_block + 可用内存空间组成。malloc 返回的是内存控制块后的地址,即可用内存空间的起始地址。
struct mem_control_block { int is_available; // 是否可用(如果还没被分配出去,就是 1) int size; // 实际空间的大小 };
malloc 分配时遍历空闲链表,以首次适应算法为例,寻找第一个大于所需空间的空闲区块,然后将其分配给程序,返回这可用空间的指针。如果没有这样的内存块,则向操作系统申请扩展堆内存。若空闲区块空间有剩余,系统自动将多余的部分重新放入空闲链表。
常见的内存匹配算法有
- 首次适应法
- 最佳适应法
- 最差适应法
- 下一个适应法
* free 原理
free 将内存区块重新插入到空闲链表,free 只接受一个指针,却可以释放恰当大小的内存,这是因为在内存控制块保存了该区域的大小。
被 free 回收的内存首先被 ptmalloc 使用双向链表保存起来,当用户下一次申请内存时,会尝试从这些内存中寻找合适的返回,避免了频繁的系统调用,占用过多的系统资源。同时 ptmalloc 也会尝试对小块内存进行合并,避免产生过多的内存碎片。
内存对齐
内存的自然对齐:按照结构体中最大数据成员对齐。
- 结构体内成员按照声明顺序存储,第一个成员地址和整个结构体地址相同。
- 结构体的首地址必须是最大数据成员大小的整数倍
- 每个成员相对于结构体首地址的偏移量必须是该成员大小的整数倍,否则填充字节。
- 整个结构体的大小必须是最大数据成员大小的整数倍,否则填充字节。
对齐系数:#pragma pack(n)
#pragma pack(n) // 按照 n (2 的 n 次幂)个字节对齐 #pragma pack() // 取消自定义字节对齐方式
* 内存对齐的规则
- 数据成员对齐规则:第一个数据成员放在偏移 0 的地方,每个数据成员的对齐按照#pragma pack(n)和该数据成员自身长度,比较小的那个进行
- 结构(或联合)的整体对齐规则:数据成员对齐后,结构(或联合)整体也要进行对齐,对齐按照#pragma pack(n)和结构(联合)最大数据成员长度中,比较小的那个进行
- 结构体作为成员:内部结构体成员从最大元素的整数倍和#pragma pack(n)最小的一个的整数倍地址开始存储。
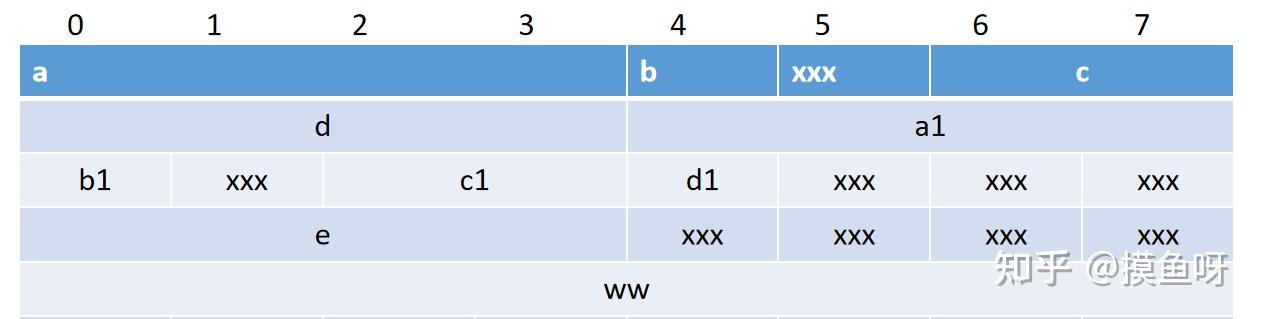
例如:
struct SS { int a; char b; short c; int d; struct FF { int a1; char b1; short c1; char d1; } MyStructFF; int e; double ww; } MyStructSS;
其内存对齐方式如下:
测试代码:
#include <iostream> /* #pragma pack(4) */ using std::cout; using std::endl; struct x { char a; int b; short c; char d; } MyStructX;//12 struct y { int b; char a; char d; short c; } MyStructY; // 8 struct SS { int a; char b; short c; int d; struct FF { int a1; char b1; short c1; char d1; } MyStructFF; #if 1 /* char e; // 28 */ int e; double ww; // 40 #endif } MyStructSS; struct DD { int a; char b; short c; int d; struct FF { double a1; char b1; short c1; char d1; } MyStructFF; char e; // 40 } MyStructDD; struct GG { char e[2]; short h; struct A { int a; double b; float c; } MyStructA; } MyStructGG; // 32 int main(int argc, char **argv) { cout <<"sizeof(MyStructX) = " << sizeof(MyStructX) << endl; cout <<"sizeof(MyStructY) = " << sizeof(MyStructY) << endl; cout <<"sizeof(MyStructSS) = " << sizeof(MyStructSS) << endl; cout <<"sizeof(MyStructDD) = " << sizeof(MyStructDD) << endl; cout <<"sizeof(MyStructGG) = " << sizeof(MyStructGG) << endl; return 0; }

