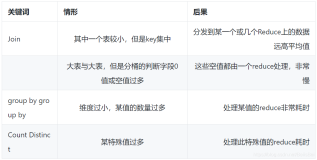
一、背景
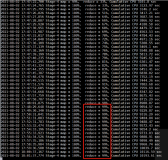
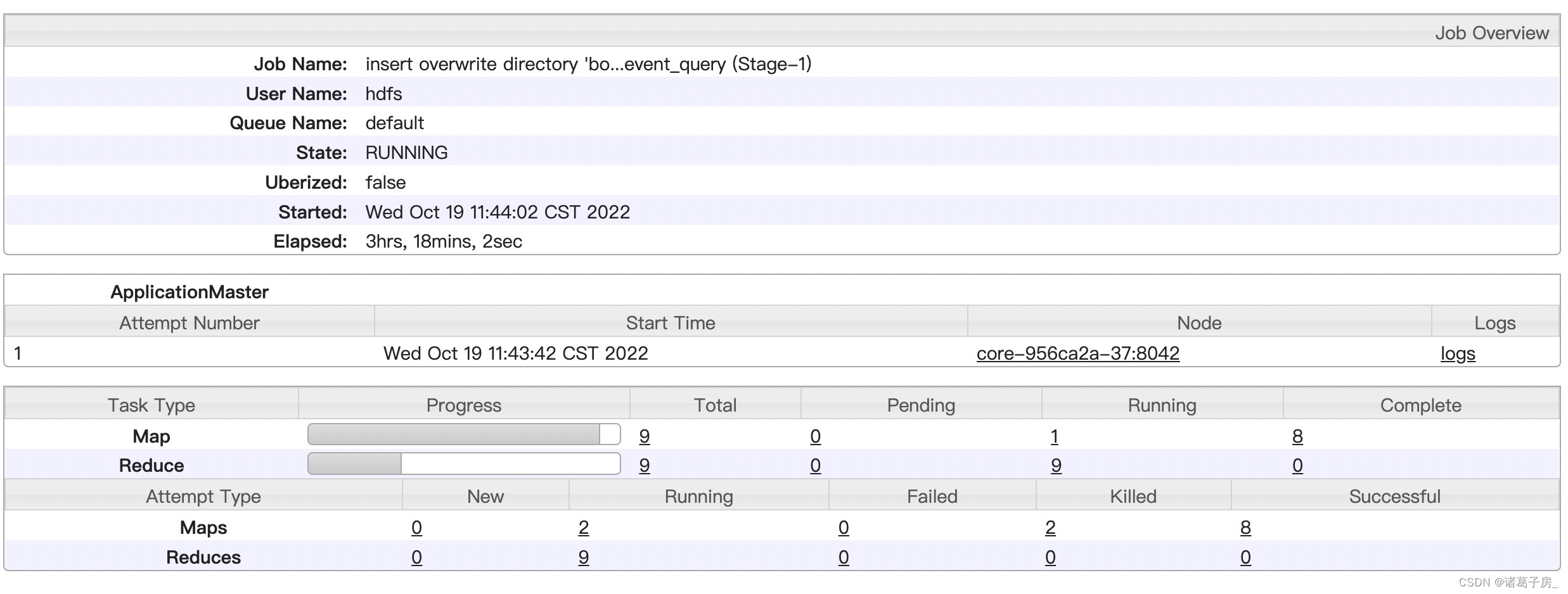
发现一个10.19号的任务下午还没跑完,正常情况下,一般一个小时就已经跑完,而今天已经超过3小时了,因此去观察实际的任务,发现9个map 其中8个已经完成,就一个还在run,说明有明显的数据倾斜
二、数据倾斜问题处理和Hive SQL 优化
原始sql
insert overwrite table raw_search_behavior partition(dt='2022-10-19') select cookie_id,event_query,count(*) as cnt, max(from_unixtime(unix_timestamp(event_time), 'yyyyMMddHHmmss')) as last_dt from raw_query where dt >= '20220718' and dt <= '20221019' and event_query is not null group by cookie_id,event_query
发现有使用group by
优化后sql
insert overwrite table raw_search_behavior partition(dt='2022-10-19') select split(tkey,'_')[1] as cookie_id,event_query, sum(cnt) as cnt,max(last_dt) as last_dt from ( select concat_ws('_', cast(ceiling(rand()*99) as string), cookie_id) as tkey,event_query, count(*) as cnt, max(from_unixtime(unix_timestamp(event_time), 'yyyyMMddHHmmss')) as last_dt from raw_query where dt >= '20220718' and dt <= '20221019' and event_query is not null group by concat_ws('_', cast(ceiling(rand()*99) as string), cookie_id),event_query ) temp group by split(tkey,'_')[1],event_query;
三、观察任务
在一小时内结束,并且没有哪个节点耗时较长