为什么用数据库?
数据库比记事本强在哪?
答案很明显,你的文件很多时候都只能被一个人打开,不能被重复打开。当有几百万数据的时候,你如何去查询操作数据,速度上要快,看起来要清晰直接
数据库比我之前学的XML好在哪?
XML表写索引的时候,很容易被中间断电就打断了,两个表对不上号了咋办?
安全和备份处理上数据库都有自己的考虑。

前言
python学习之路任重而道远,要想学完说容易也容易,说难也难。
很多人说python最好学了,但扪心自问,你会用python做什么了?
刚开始在大学学习c语言,写一个飞行棋的小游戏,用dos界面来做,真是出力不讨好。
地图要自己一点一点画出来,就像这样:
================ | | | | |===============
从此讨厌编程,不想继续学下去。每次作业应付。
算法考试,数据结构考试随便背代码,只求通过。
最后呢?我学会变成了吗?只能对一些概念侃侃而谈,但真的会几行代码,能写出实用工具吗?
答案变得模糊。
所以我们要从现在开始,学好python,不要再糊弄下去!!!
数据库DB

可长期存计算机里面的、有组织、可共享的数据集合。
关系型
Relational Database。
以行、列结构化关系表存储数据
SQL查询语言提供数据读写、事务处理数据的多表操作,支持并发访问
非关系型
NoSQL-Not Only SQL
非行、列结构的数据结构
提供分布式处理技术,用来解决大数据处理问题
没提供统一的SQL语言类似的操作标准
新型
介于DBMS和NoSQL之间的NewSQL类的数据库
啥都能干,还有分布式处理技术
其他数据库分类
基于内存数据库
主要在内存驻留。
执行速度快,数据容易丢失
SQLite、Redis基于内存数据库
基于硬盘数据库
大规模读写速度慢,但是不容易丢失数据。
MySQL、Oracle、MongoDB基于硬盘数据库
凡事不绝对
也都支持对方的数据存储方式。
现实是复杂的。
访问数据库基本原理

ODBC
Open Database Connectivity
开放数据库连接,是用于访问数据库管理系统的API
支持各种OS下的数据库
ADO
ADO是微软的windows上的数据库高级接口
常堆叠在ODBC驱动程序之上
进一步简化访问技术处理过程。
关系型数据库

通用数据库系统:MYSQL…
数据仓库数据库系统:IBM Netezza
嵌入式数据库系统:SQLite、ThinkSQL
连接SQLite
SQLite是python自带的基于内存或者硬盘的轻量数据库系统。
操作步骤
第一步,建立应用系统与数据库的连接;
第二步,需要建立数据库实例,通俗理解是建立一个存储数据库的文件;
第三步,建立对应的表结构;
第四步,往表里写记录,读记录;
第五步,关闭与数据库的连接。
建立基于内存的数据库
import sqlite3 #导入sqlite3模块 conn = sqlite3.connect(":memory:")#建立一个基于内存的数据库 conn.close() #关闭与数据库的连接
当对数据库操作完成时,建议养成及时关闭数据库连接的好习惯,避免打开数据库连接过多,消耗内存存储空间。
建立基于硬盘的数据库
import sqlite3 #导入sqlite3模块 conn = sqlite3.connect("First.db")#建立一个基于硬盘的数据库实例 conn.close() #关闭与数据库的连接
基本操作-增删改查
import sqlite3 #conn=sqlite3.connect(":memory:") conn=sqlite3.connect("First.db") cur=conn.cursor()#建立游标 # 建立表结构对象 cur.execute('''Create table fish(date text,name text,nums int,price real,Explain text)''') # cur.execute("insert into fish VALUES ('2018-3-22','黑狗',10,28.2,'jacky')") cur.execute("insert into fish VALUES ('2222-3-22','无敌狗',88,28.2,'kk')") # cur.execute("select * from fish") # for row in cur.fetchall(): # print(row) # cur.execute("delete from fish where nums=10") conn.commit() conn.close()
连接MySQL
首先,需要在电脑上安装pymysql这个库,可以通过pip install pymysql命令进行安装。
接着,在Python中导入该库并编写连接数据库的代码:
import pymysql # 连接数据库 mydb = pymysql.connect( host="localhost", user="root", password="123456", database="test" ) # 创建数据库表 mycursor = mydb.cursor() mycursor.execute("CREATE TABLE customers (name VARCHAR(255), address VARCHAR(255))") # 插入数据到数据库表中 sql = "INSERT INTO customers (name, address) VALUES (%s, %s)" val = ("John", "Highway 21") mycursor.execute(sql, val) # 提交更改 mydb.commit() # 输出数据库中的数据 mycursor.execute("SELECT * FROM customers") myresult = mycursor.fetchall() for x in myresult: print(x)
以上代码实现了连接到本地主机的MySQL服务器,并且创建了一个名为"customers"的数据库表。之后,可以将数据插入到该表中,并从表中读取数据并输出到命令行窗口。
你需要将上述代码中的yourusername、yourpassword和mydatabase分别替换为你的用户名、密码和数据库名称。
在程序里面显示数据
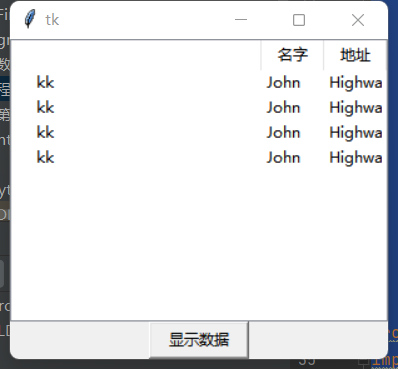
def turn_property(event): getSQLDate() def getSQLDate(): import pymysql import sys # 连接数据库 mydb = pymysql.connect( host="localhost", user="root", password="123456", database="test" ) # 创建数据库表 mycursor = mydb.cursor() # mycursor.execute("CREATE TABLE customers (name VARCHAR(255), address VARCHAR(255))") # # # 插入数据到数据库表中 # sql = "Select * from customers" # val = ("John", "Highway 21") # mycursor.execute(sql) # 提交更改 # mydb.commit() # 输出数据库中的数据 mycursor.execute("SELECT * FROM customers") myresult = mycursor.fetchall() for x in myresult: print(x) tree.insert("",0,text="kk", values=(x[0],x[1])) from tkinter import ttk import tkinter as tk root=tk.Tk() # root.geometry("200x200") # root.title("事情") tree=ttk.Treeview(root) tree["columns"]=("name","address") tree.column("name",width=50) tree.column("address",width=50) tree.heading("name",text="名字") tree.heading("address",text="地址") tree.pack(side="top") bs=tk.Button(root,text="显示数据",width=10) bs.bind('<Button-1>',turn_property) bs.pack(side="top") root.mainloop() # root.mainloop()
NoSQL数据库
连接mongoDB
MongoDB是一个非关系型数据库,它的数据以BSON(二进制JSON)格式存储。Python中使用pymongo库来连接MongoDB数据库,并编写相关操作的代码。
首先,需要在电脑上安装pymongo库,可以通过pip install pymongo命令进行安装。
接着,在Python中导入该库并编写连接数据库的代码:
import pymongo # 连接数据库 myclient = pymongo.MongoClient("mongodb://localhost:27017/") mydb = myclient["mydatabase"] mycol = mydb["customers"] # 插入数据到数据库中 mydict = { "name": "John", "address": "Highway 37" } x = mycol.insert_one(mydict) # 输出插入数据的ID print(x.inserted_id) # 查询数据 for x in mycol.find(): print(x)
以上代码实现了连接到本地主机的MongoDB服务器,并且创建了一个名为"mydatabase"的数据库和一个名为"customers"的集合(类似于关系型数据库中的表)。之后,可以将数据插入到该集合中,并从集合中读取数据并输出到命令行窗口。
以上代码中的mongodb://localhost:27017/表示连接到本地主机的MongoDB服务器,默认端口号为27017。你需要将该地址替换成自己所连接的MongoDB服务器地址。
另外,为了更好地管理MongoDB数据库,在Python中还可以使用mongoengine库。该库提供了更高级别的API,使得对于MongoDB数据库的操作更加简单和直接。如果对于MongoDB的使用更加深入和全面的掌握,可以进一步了解该库。
启动mongo
在Windows上简单启动MongoDB,可以按照以下步骤:
- 下载MongoDB的Windows安装程序:从MongoDB官网下载Windows版的安装程序(msi格式),下载后运行安装程序进行安装。
- 配置MongoDB的数据存储目录:在安装完成后,需要手动配置MongoDB的数据存储目录。默认情况下,MongoDB将存储数据在C:\data\db目录下,如果该目录不存在,需要手动创建。
- 启动MongoDB服务:在安装目录中找到bin目录,其中包含了MongoDB的启动程序。用Windows命令提示符(CMD)进入该目录,并执行以下命令开启MongoDB服务:
mongod.exe --dbpath="C:\data\db"
其中,“–dbpath”参数指定了数据存储目录的路径。例如,以上命令中指定了C:\data\db目录为数据存储目录。
- 连接MongoDB服务器:在MongoDB服务启动成功后,在另一个命令提示符窗口不需要关闭服务,执行以下命令连接到MongoDB服务器:
mongo
这将打开一个MongoDB shell窗口,可以在该窗口内执行相关的MongoDB操作命令。
以上就是在Windows上启动MongoDB以及连接MongoDB服务器的简单步骤,适合于初学者快速入门。当然,在实际使用过程中,还需要掌握更加深入和全面的MongoDB操作知识。
总结
不管怎么样,我们要在我们的项目中应用数据库技术。
不要把文件数据随便上传一些、应付了事!

