本次主要来聊聊关于切片的扩容是如何扩的,还请大佬们不吝赐教
切片,相信大家用了 Go 语言那么久这这种数据类型并不陌生,但是平日里聊到关于切片是如何扩容的,很多人可能会张口就来,切片扩容的时候,如果老切片的容量小于 1024 那么就再扩容 1倍,也就是新的切片容量是老切片容量的两倍,同理,如果老切片容量大于 1024,那么就扩容1.25 倍
一个人这么说,多个人这么说,你可能就信了😂😂,可是大家都这么认为,我们就应该盲从吗?还是要自己去确认真实的扩容逻辑和实现方式,那就开始吧😁
结论先行,切片对于扩容并不一定是 2 倍,1.25倍,这个要看实际情况
本文分别从如下几点来聊聊切片的扩容
- 扩容是针对切片的,数组无法扩容
- 切片扩容到底是扩容到原来的几倍?
- 我们一般使用切片的时候可以如何避免频繁的扩容?
扩容是针对切片的,数组无法扩容
首先需要明确,数组是不能扩容的,数组定义的时候就已经是定长的了,无法扩容
切片是可以扩容的,我们可以通过 append 追加的方式来向已有的切片尾部进行追加,若原有切片已满,那么就会发生扩容
另外,我们知道数组是一段连续的内存地址,同一种数据类型的数据集合,例如这样
func main() { log.SetFlags(log.Lshortfile) var demoArray = [5]int{1, 2, 3, 4, 5} log.Print("unsafe.sizeof(int) == ",unsafe.Sizeof(demoArray[0])) for i, _ := range demoArray { log.Printf("&demoAraay[%d] == %p", i, &demoArray[i]) } }

可以看到在这个案例的环境中,一个 int 类型的变量占用 8 个字节,自然对于 demoArray 数组中,地址是连续的,每一个元素占用的空间也是我们所期望的
那么切片的数据地址也是连续的吗??
如果有人问这个问题,实际上是想问切片的底层数组的地址是不是也是连续的
我们知道,切片 slice 在 Go 中是一个结构体,其中 array 字段是一个指针,指向了一块连续的内存地址,也就是底层数组
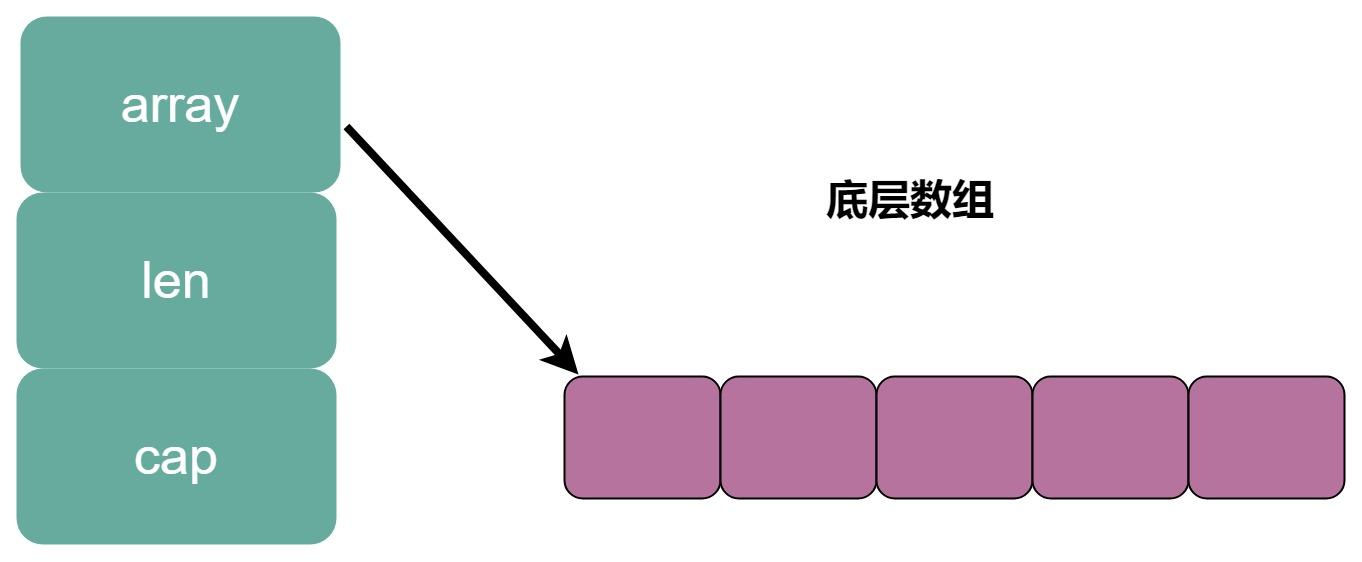
type slice struct { array unsafe.Pointer len int cap int }
其中 len 字段记录了当前底层数组的实际有的元素个数,cap 表示底层数组的容量,自然也是切片slice 的容量
func main(){ var demoSli = []int{1,2,3,4,5} log.Printf("len == %d,cap == %d",len(demoSli),cap(demoSli)) for i, _ := range demoSli { log.Printf("&demoSli[%d] == %p", i, &demoSli[i]) } }

自然,demoSli 中的元素打印出来,地址也是连续的,没有毛病
此处 xdm 模拟的时候,切勿去打印拷贝值的地址,例如下面这种方式是相当不明智的

现在简单的去给 切片追加一个元素
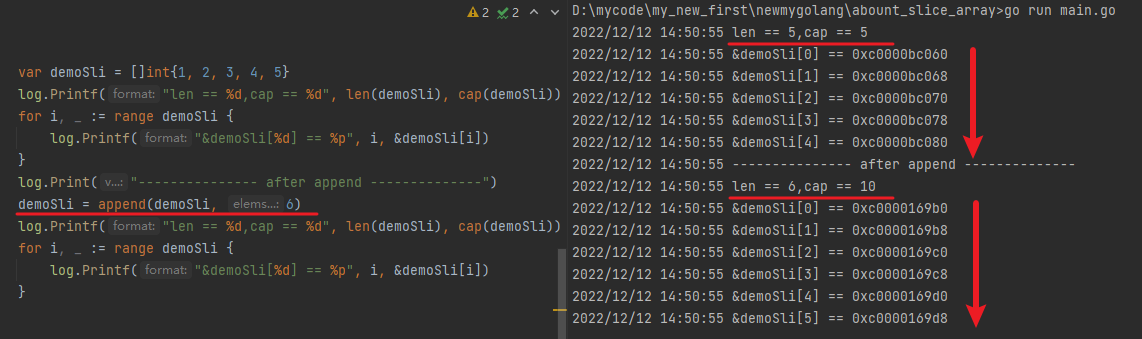
可以看到切片的容量变成了原来的两倍(容量从 5 扩容成 10),且切片中底层数组的元素地址自然也是连续的,不需要着急下结论,继续往下看,好戏在后头
切片扩容到底是扩容到原来的几倍?
案例1 向一个cap 为 0 的切片中追加 2000 个元素,查看被扩容了几次
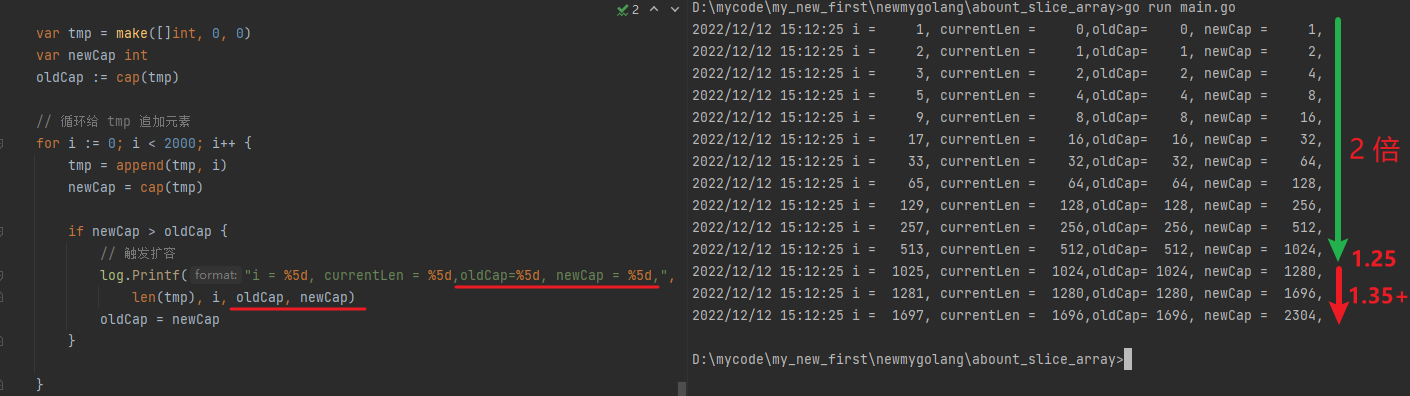
总共是扩容了 14 次
可以看到切片容量小于 1024 时,触发扩容都是扩容到原来的 2 倍,但是 大于 1024 之后,有的是 1.25 倍,有的是 1.35 倍,有的大于 1.35 倍,那么这是为什么呢?后面统一看源码
案例2 再次验证切片容量小于 1024,触发到扩容就一定是扩容 2 倍吗
- 先初始化一个切片,里面有 5 个元素,len 为 5,cap 为 5
- 再向切片中追加 6 个元素,分别是
6,7,8,9,10,11 - 最终查看切片的容量是多少
func main(){ var demoSli = []int{1, 2, 3, 4, 5} log.Printf("len == %d,cap == %d", len(demoSli), cap(demoSli)) for i, _ := range demoSli { log.Printf("&demoSli[%d] == %p", i, &demoSli[i]) } demoSli = append(demoSli,6,7,8,9,10,11) log.Printf("len == %d,cap == %d",len(demoSli),cap(demoSli)) for i, _ := range demoSli { log.Printf("&demoSli[%d] == %p", i, &demoSli[i]) } }
通过这一段代码,我们可以看到,讲一个 len 为 5,cap 为 5 的切片,追加数字 6 的时候,切片应该要扩容到 10,然后追加到数字 11 的时候,切片应该扩容到 20,可实际真的是这样吗?

xdm 可以将上述 demo 贴到自己环境试试,得到的结果仍然会是切片的容量 cap 最终是 12,并不是 20
那么这一切都是为什么呢?我们来查看源码一探究竟
源码赏析
查看公共库中 runtime/slice.go 的 growslice 函数就可以解开我们的疑惑

可以看出在我们使用 append 对切片追加元素的时候,实际上会调用到 growslice 函数, growslice 中的核心逻辑我们就可以理解为计算基本的 newcap 和进行字节对齐
- 进行基本的新切片容量计算
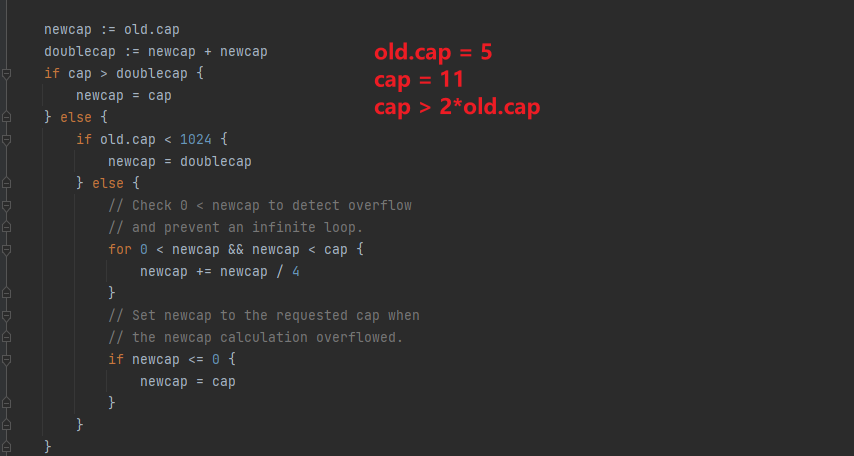
// 省略部分 newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.cap < 1024 { newcap = doublecap } else { // Check 0 < newcap to detect overflow // and prevent an infinite loop. for 0 < newcap && newcap < cap { newcap += newcap / 4 } // Set newcap to the requested cap when // the newcap calculation overflowed. if newcap <= 0 { newcap = cap } } } // 省略部分
此处逻辑可以知道
- 如果当前传入的 cap 是比原有切片 cap 的 2 倍还要大,那么就会按照当前传入的 cap 来作为新切片的容量
- 否则去校验原有切片的容量是否小于 1024
- 若小于 1024 ,则按照原有的切片容量的 2 倍进行扩容
- 若大于等于 1024 ,那么就按照原有切片的 1.25 倍继续扩容
然后是否看到这里就就结束了呢?就下定论来呢?并不,我们切莫断章取义,需要看全整个流程
- 进行基本的字节对齐
growslice 函数 计算出基本的 newcap 之后,还需要按照类型进行基本的字节对齐,此处字节对齐之后主要是 roundupsize 的函数实现,顺便将其涉及到的常量放到一起给大家展示一波
const ( _MaxSmallSize = 32768 smallSizeDiv = 8 smallSizeMax = 1024 largeSizeDiv = 128 _NumSizeClasses = 68 _PageShift = 13 ) func roundupsize(size uintptr) uintptr { if size < _MaxSmallSize { if size <= smallSizeMax-8 { return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]]) } else { return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]]) } } if size+ _PageSize < size { return size } return alignUp(size, _PageSize) } func divRoundUp(n, a uintptr) uintptr { // a is generally a power of two. This will get inlined and // the compiler will optimize the division. return (n + a - 1) / a } var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, ...}
光看这个函数,没啥感觉,函数逻辑比较简单,就是基本的计算和索引,那么我们讲上述的案例2带入,来计算一下

此处很明确,当前旧的切片的 cap 为 5
也就是 growslice 函数 中 old.cap 为 5,传入的 cap 为 11,因此 cap > 2*old.cap
因此 newcap 此处等于 11
开始计算字节对齐之后的结果
- roundupsize(uintptr(newcap) * sys.PtrSize) ,其中 newcap = 11,sys.PtrSize = 8,则 roundupsize 参数传入 88 ,此环境指针占用 8 字节
- 按照如下逻辑进行计算
- divRoundUp(88, 8) = 11
- size_to_class8[11] = 8
- class_to_size[8] = 96
此处环境我们的 int 类型是占用 8 个字节,因此最终的 newcap = 96/8 = 12

经过上述源码的处理,最终我们就可以正常的得到最终切片容量被扩容到 12 ,xdm 可以去看实际的源码
小结
使用 append 进行切片扩容的时候,先会按照基本的逻辑来计算 newcap 的大小
- 如果当前传入的cap是比原有切片cap的2倍还要大,那么就会按照当前传入的cap来作为新切片的容量,否则去校验原有切片的容量是否小于 1024
- 若小于1024,则按照原有的切片容量的2倍进行扩容
- 若大于等于 1024,那么就按照原有切片的 1.25 倍继续扩容
最终再进行字节对齐
那么实际上,最终的切片容量一般是会等于或者大于原有的 2倍 或者是 1.25 倍的
我们一般使用切片的时候可以如何避免频繁的扩容?
一般在使用切片的时候,尽量避免频繁的去扩容,我们可以对已知数据量的数据,进行一次性去分配切片的容量
例如,数据量有 1000 个,那么我们就可以使用 make 的方式来进行初始化
sli := make([]int, 0, 1000)
本次就是这样,如果对源码还挺感兴趣的话,xdm 可以去实际查看一下源码哦,希望对你有帮助
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
文中提到的技术点,感兴趣的可以查看这些文章:
