用数据下判断,是看似简单,实则极大影响数据分析结果的一个问题。同样是本月销售业绩1000万,如果判断是:业绩很好。那么下一步的分析就是总结成功经验。如果判断是:业绩很差。那么下一步的分析就是发现问题,寻找方案。
一 、数据诊断问题,为啥那么难
这一点看似简单,可网上90%的文章教的是错的。
网文的逻辑,一般是:
- 环比下跌了,所以不好,要搞高
- 同比下跌了,所以不好,要搞高
- 你去问问业务,业务说好就是好
谁规定的跌就是不好?如果是自然波动呢,如果是计划内的调整呢,如果是营销之后调整期呢?如果是生命周期末尾呢?如果下跌但是KPI仍然达标呢?太多情况了。然后一堆网文还在一本正经的《指标下跌六大分析方法》连啥指标,啥场景都不细讲,分析个屁。
问业务同样有问题。因为你挡不住业务浑水摸鱼。丫今天说好,明天说不好,后天说:请数据分析深入分析到底好不好,大后天再说:你这分析不符合业务直觉。甚至明明KPI达标了,丫还让“你深入分析KPI达标背后的隐藏危机……”
O(╯□╰)o
那么,到底该咋办呢。
二 、核心问题:诊断标准
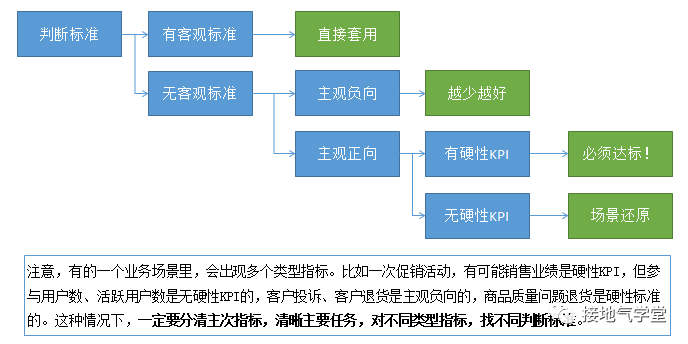
做判断的核心是:找标准。标准涉及到后续轻重缓急及原因判断。一定要事先分清楚。而上文讲到的网文的各种错误,本质上都是来自于不考虑业务场景,瞎胡判断。如果结合业务场景来看的话,有四类典型的场景(如下图)。
 图片
图片
1、有客观要求。供应链上大部分指标都有物流、化学、交付周期等等客观要求。比如生产质量、产品尺寸、交货时间。这些也被称作硬指标。这种情况下是可以直接拿来做评价标准的。
2、主要要求,但是负向指标。比如客户投诉,虽然大家都知道投诉是不可避免的,但是还是希望越少越好,负向指标标准也好找,只要一直处于下跌趋势,不反弹,就算是好。
3、主观,正向,但是有上一级KPI压力。类似销售业绩,GMV,新用户数,很有可能上一级领导、部门直接塞了个指标给我们。这时候想保住自己的年终奖,就得不惜一切代价地搞掂指标。这个标准可以直接拿来用(这也算硬指标)。
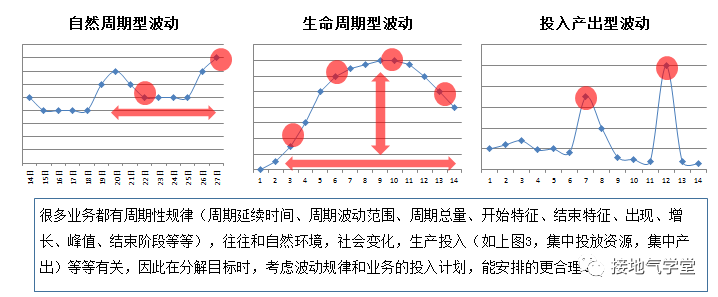
这时候要做好的是硬指标的分配。因为指标达成不是一蹴而就的,可能与业务自然周期、生命周期有关,也有可能与业务作战部署有关系。因此分解任务的时候不要简单地按时间平均,而是根据业务走势,分摊成一个合理数值。
 图片
图片
4、主观,正向,需要你自己定KPI。这是最纠结的状况,老板让你做开放题。虽然明知道自己做了他不用会用,但是他还是让你讲一堆道理,不然就怪你:没有深度分析!如果一定要凭空定指标,怎么办呢?
答:用场景还原法,去找一个标杆。
三、 关键方法:场景还原
场景还原,是从业务场景中提炼出数据标准,主要用于营销、运营这种缺少硬指标且指标间相互关联多的场景。你问业务方指标是多少,估计他想不出来。
但是你问他上一次老板龙颜大悦,上一次被表彰,上一次顺风顺水什么时候,他一清二楚。同样,你问上一次他手忙脚乱,上一次被痛骂,上一次跟头流希是啥时候,他也一清二楚。这样我们就能得到正面场景和负面场景。
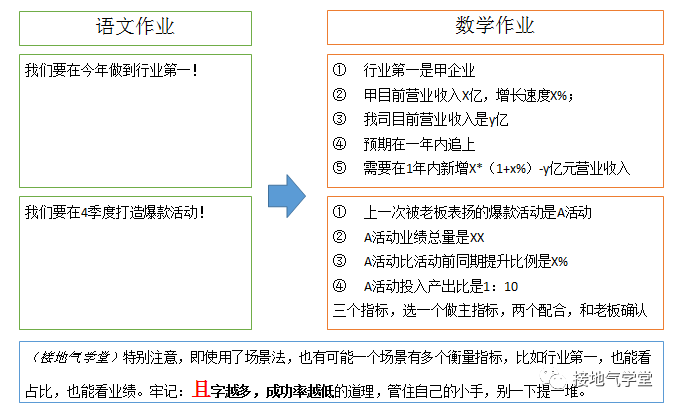
正面场景,用来做整体的预计目标。这是个把语文作业转化为数学作业的过程。比如:
- 我们要在三年内成为行业第一
- 我们要在1年内扭亏为赢
- 我们要在4季度做出爆款活动
有了这些场景,可以转化为具体标准(如下图)。
 图片
图片
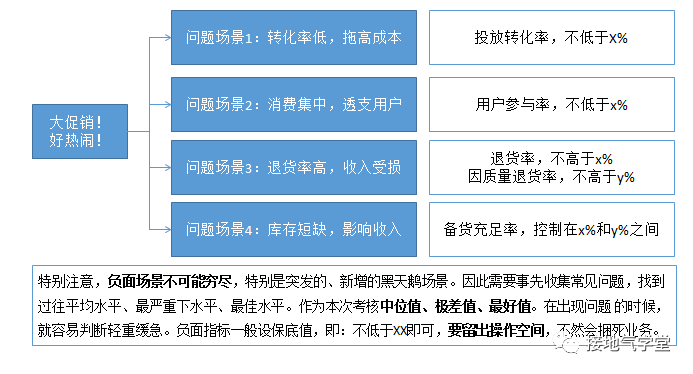
负面场景,用来设定保障型指标的标准。比如:
- 新用户注册很多,但是转化太低
- 业绩增长很快,库存涨的更快
- 收入指标达标,成本超支严重
有了这些场景,可以转化为具体标准(如下图)。
 图片
图片
经过梳理,输出的判断标准,就是一个有逻辑的系列组合(如下图)。
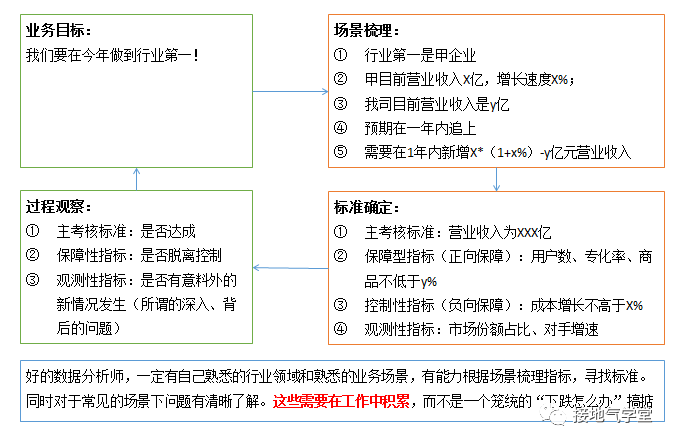 图片
图片
这样面对业务方或者老板质疑的时候,也能理直气壮地说:既然要达成这个美好愿景,就得做到XX数值。如果不做到XX数值,业务就会出问题。这样面对上文中,业务方反复横跳的场面时,也能拿出白纸黑字来对峙,不要让他把锅甩给我们。可以甩给外部突发因素吗,真是的,干嘛非难为数据分析师。
四 、为什么不用算法模型
算法模型不是一个处理标准问题的好办法。用机器学习算法,如果用无监督方法,比如Kmean聚类,本身输出的结果就随着聚类中心变化而变化,不稳定结果不能做标准。如果用有监督的方法,那一开始的“好/坏”标注谁来打?还是得老板来打。看似复杂的算法又变成:请老板酌定。
AHP方法有类似问题,看似两两比较打分很科学,可本质还是:请老板酌定。而且AHP的局部打分,很容易导致整体结果不可控。万一老板不认最终评定结果,非让你改,就非常狼狈了。
这时候还不如直接让老板们坐一桌,拍每个指标权重给多少。这样更简单、高效、不纠结。所以:如果待评价的问题中,正向、非硬指标很多,那还是用场景还原法更好。
标准问题的真正难点是:最后的标准始终要过老板这一关,因此就不可能100%客观。老板自己也会疑虑、纠结、后怕。所以才有了前边说的:虽然老板心里有数,但他还是会让你提标准,并且在你提了以后反复质疑你。其实他是通过这种手段消除自己的疑惑。做数据分析,就是要当老板的贴心小助理,这些问题帮老板想在前头,也是大功一件。
有同学会问:日常遇到的判断问题很多,一个个都这么细致沟通效率太低,很有没有一些简单的方法做判断,答:有。比如我们常说的二八分类,十分位法,趋势分析法,矩阵法,都是简单粗暴的判断方法。


