系列文章:
上一篇我们讲到了处理器在执行时,会对指令进行重排序,而这会导致数据一致性问题。对指令重排的理解非常重要,这也是并发问题出现的最大原因。
一 数据依赖性
并发出现在两个线程的操作之间,如果两个操作访问的是同一个变量,且这两个操作中至少有一个是写操作,那么这两个操作之间就存在数据依赖。数据依赖包括以下三种类型:
1.1 写后读
对变量写之后,再读这个变量。代码示例(操作变量a):
a=1; b=a;
1.2 写后写
两个操作,第一个操作是写这个变量,然后另一个操作继续写这个变量。示例代码(变量a):
a=1; a=2;
1.3 读后写
两个操作,先读后写。示例代码(针对变量b):
a=b; b=1;
编译器和处理器对操作(指令)重排序,会遵守数据依赖性,而不会改变存在数据依赖关系的两个操作的执行顺序。这点至关重要。
另外需要注意的是,这里提到的数据依赖性,只针对单个处理器中执行的指令序列,和但线程中执行的操作,不同处理器之间,和不同线程之间的数据依赖性不会被考虑。
二 as-if-serial语义
这个语义是指,不论怎样重排序,(单线程)程序的执行结果不能被改变。编译器、处理器都必须遵守as-if-serial语义。
这个语义也就是上一章所说到的,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变结果。通过下面示例我们用以说明数据依赖情况:
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C
上面代码块中,A,B,C三个操作的依赖关系如下图所示:
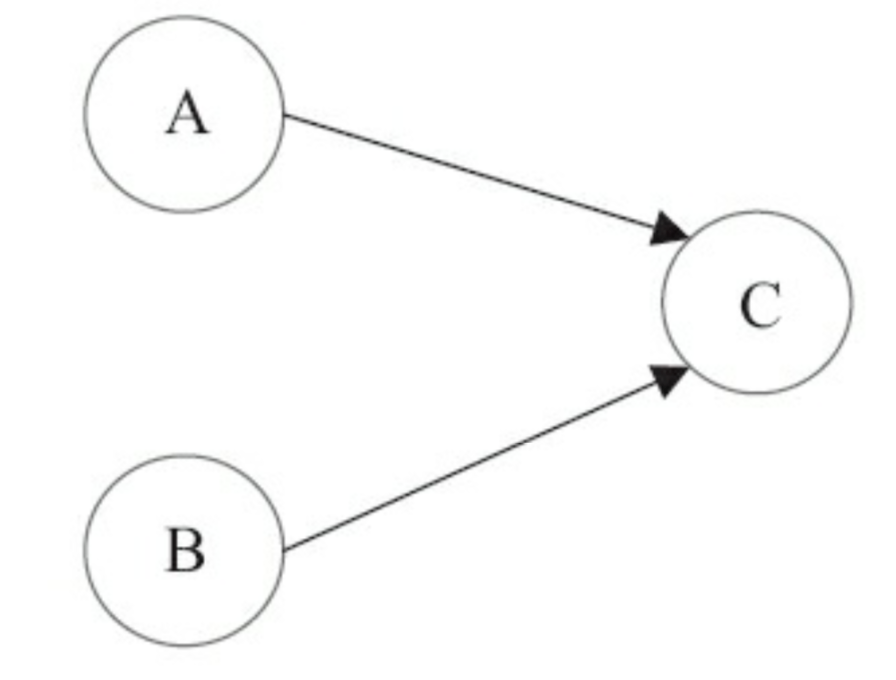
如上图所示,A、B两个操作都与C有依赖关系,所以C不能被重排到A、B操作之前。 但A与B之间没有依赖,所以编译器与处理器可以重排A、B之间的执行顺序。
(1)按照代码编写的顺序执行: A->B->C,执行结果area = 3.14;
(2)A、B之间重排,执行顺序为: B->A->C,执行结果依然是 area = 3.14
由此可见,正常情况下,我们认为代码是按照编写顺序执行只是一个幻觉。实际上即使是单线程中,实际执行顺序也可能与代码编写的顺序不同。但as-if-serial语义能够保证这些重排并不会影响执行结果。
三 程序顺序规则
即happens-before规则。上面的计算代码中存在3个happens-before关系:
1)A happens-before B;
2)B happens-before C;
3)A happens-before C;这个是基于1) 和 2)的传递得到的
这里的1),在实际执行时B是可能在A之前执行的。即使有A happens-before B,JMM也并不要求A一定要在B执行之前执行,而是只要求前一个操作(执行结果)对后一个操作可见。上面示例中,A的执行结果不需要对B可见;而且重排序A 和 B之后的结果,与A和B按照happens-before规则执行的结果一致,因此JMM认为这种重排序是合法的(not illegal),所以允许这样的中排序。
四 重排序对多线程的影响
前面提到,指令重排的规则是针对单线程的,以保证在单线程执行的情况下,重排序不影响执行结果。那么多线程下是否也是?会带来什么样的影响?下面示例代码中,flag是一个标记 变量,标记a是否被写入。
public class ReorderExample { int a = 0; boolean flag = false; public void writer(){ a = 1; // 1 flag = true; // 2 } public void reader(){ if(flag){ // 3 int i = a * a; // 4 ...... } } }
我们假设有两个线程A 和 B,a先执行writer(),然后B执行reader(),线程B在执行操作4时,不一定能看到A对共享变量a的写入!!!这是因为,操作1 和 2没有数据依赖,编译器和处理器可以对这两个操作重排;同样,3 和 4 没有数据依赖(尽管存在着控制依赖),所以也可以对这两个操作重排。也就是说,1 和 2发生重排时,程序可能会按照下面的时序图执行:
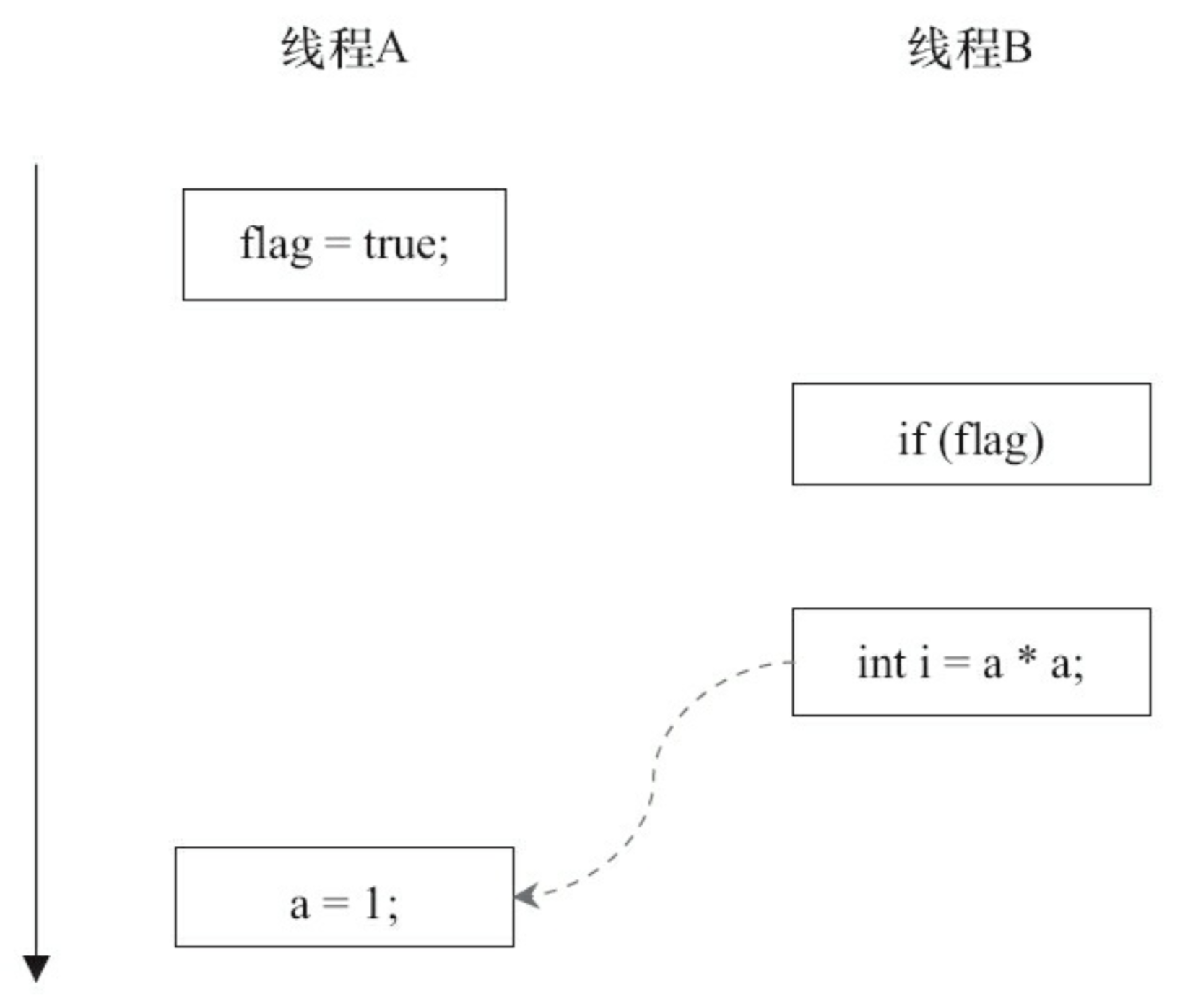
在这样的场景下,多线程程序的语义被重排破坏了。
3 和 4重排时:
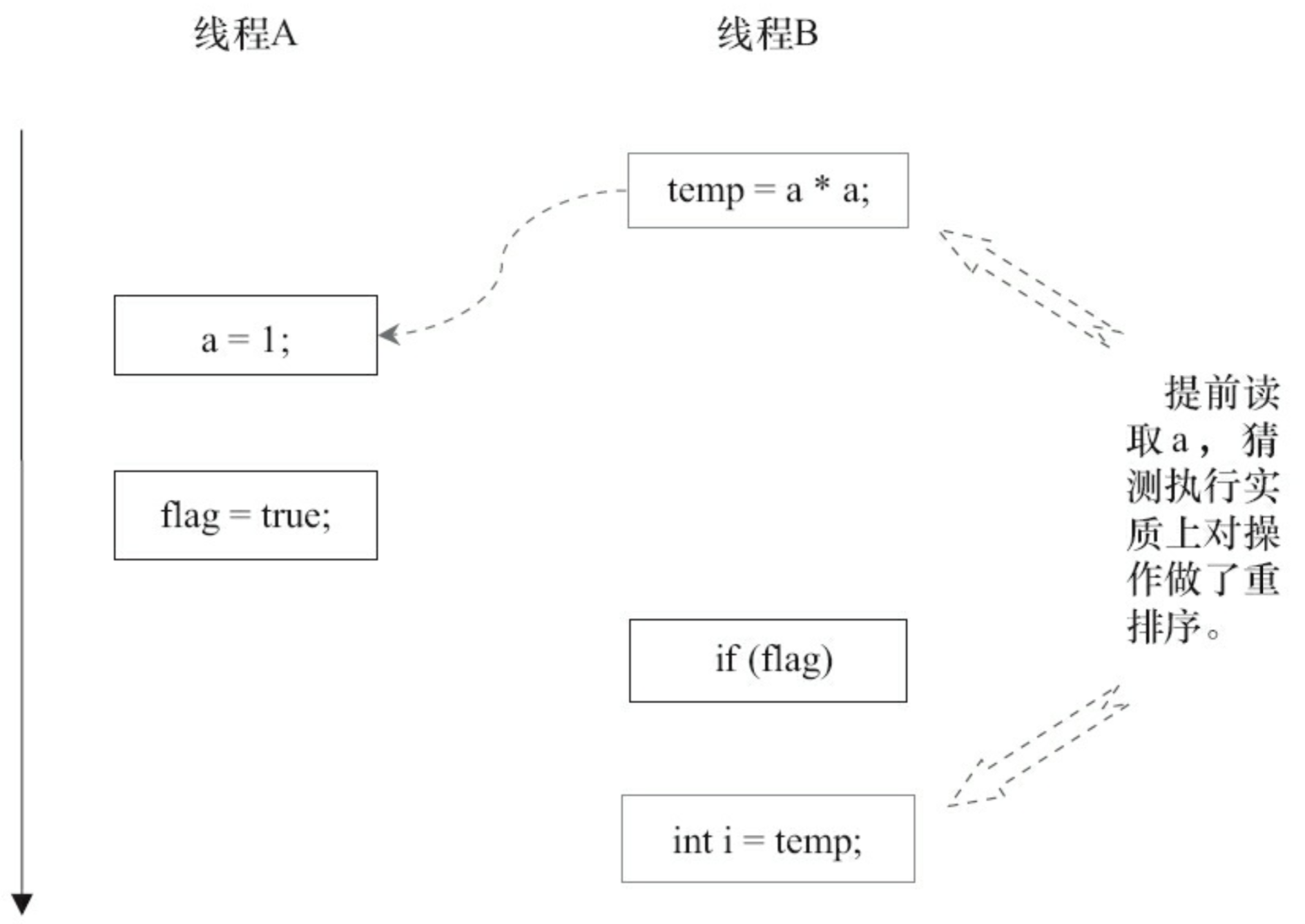
在程序中3 和 4有控制依赖关系(if判断条件,符合时才执行下面的代码块)。当存在控制依赖时,会影响指令序列执行的并行度。因此,编译器和处理器会采用猜测执行来克服控制依赖性对并行度的影响。当处理器猜测执行时,运行B程序的处理器可以提前读取并计算a*a,然后把结果临时存储在“重排序缓冲”(Reorder Buffer,ROB)的硬件缓存中;当3的判断为真时,再把这个结果写入变量i,如上图所示。这样的执行实质上对3 和 4 做了重排,破坏了语义。
五 总结
本章详细描述了指令重排序的场景,条件,以及数据依赖、控制依赖对指令重排序的影响。总结如下:
单线程程序,对存在控制依赖的操作执行重排序,不会改变执行结果;但在多线程程序中,对存在控制依赖的操作执行重排序,可能会改变程序的执行结果!这就是多线程执行时出现并发问题的根本原因,切记。

