概率图基础
概率图模型就是用图的结构来表示多个随机变量的联合概率分布(joint probability distribution),


有了这样一个概率图模型之后,我们就能够很容易地去采样出一个样本出来。原始采样法(ancestral sampling)从模型所表示的联合分布中产生样本,又称祖先采样法。该方法所得出的结果即视为原始采样。对于上述概率图,其采样可以表示为:

D-separation
这里还有一个概念比较重要:条件独立:如果p ( a ∣ b , c ) = p ( a ∣ c ) ,那么我们说在给定c cc的情况下,a 和b 是条件独立的,定义为a ⊥ b ∣ c 。
给定一个图模型之后,如何测试哪些变量是条件独立的呢?我们举三个例子来说明:
- Example 1:
tail-to-tail

上图的有向图联合概率分布可以表示为:

变量c 不给定的情况下,a 和b 的联合概率表示为:

可以知道,他们是不条件独立的,而一旦给定变量c 之后,概率图模型变为(给定变量用阴影填满):

此时a 和b 的联合概率可以表示为:

此时a 与b 条件独立。
- Example 2:
head-to-tail
再考虑链状的一个情况:
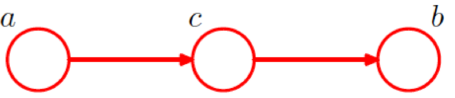
此时概率图的联合概率可以表示为:

变量a 和变量b 的联合概率可以表示为:

可以发现,变量a 和变量b 并不条件独立。当给定变量c 之后,概率图变为:

变量a 和变量b 的联合概率可以表示为:

此时变量a 和变量b 条件独立。
- Example 3:
head-to-head

此时概率图的联合概率表示为:

a 和b 之间的联合概率可以表示为:

可以发现他们是条件独立的,当给定变量c 之后,此时概率图模型变为如下形式:

此时a 和b 的联合概率可以表示为:

此时a 和b 不是条件独立的。
对上述规律进行总结,变成D-separation:
考虑两个结点的集合A 和B ,A 到B 的路径上,如果有一个集合C 在,以下两种情况我们称这条路径被blocked:
(a) 路径上的箭头,满足head-to-tail或者tail-to-tail的节点在集合C 中;
(b) 路径上的箭头满足head-to-head的节点不在C 里面,或者它任何的后代都不在C 里面。
如果A 到B 的所有路径都是blocked的话,我们称A 和B 被C d-separated的。
D-separation的应用
我们在做极大似然估计的时候,似然函数可以写成如下形式:


贝叶斯推论
Bayesian inference就是拿观测数据去更新我们的假设:

P ( hypothesis ∣ data ) 也被称作后验概率,说的是观测到某些数据之后所做的推断。P ( data ∣ hypothesis ) 被称作为似然,likelihood,P ( hypothesis ) 被称作为先验。
在做近似推断的时候,我们经常需要去评估后验概率p ( Z ∣ X ) ,或者是E p ( Z ∣ X ) 。但往往这个z zz变量是高维的,较难处理。近似推断(Approximate inference)常常会被用来解决这类问题。
- 确定行的技术:拉普拉斯近似(
Laplace approximation)来用高斯分布找到p ( Z ∣ X ) ;另外一个技术就是变分推断(variational inference)。经典机器学习系列(十)【变分推断】。 - 随机性的技术:马尔科夫链蒙特卡洛(
Markov Chain Monte Carlo,MCMC),从p ( Z ∣ X ) 中采样大量的样本之后做估计。
变分推断
变分推断(Variational inference)的思想主要就是用一个参数化的分布近似后验分布:

这样就把一个推理(inference)问题变成一个优化(optimization)问题。详细的变分推断的知识可以在这里找到:经典机器学习系列(十)【变分推断】。这里直接给出log下的边缘概率表示:

概率图角度解强化学习问题
图概率下的策略搜索
最大熵的RL就等于某种inference,在最大熵的RL里面,所有的东西都有一个soft,都有一个概率,这样做的很自然的一个好处就在于能够增加探索(exploration),概率图模型理论框架已近比较成熟,如果能够用于强化学习中能够解决很多强化学习的问题。
回顾一下强化学习,强化学习的优化目标可以表示为一个策略搜索问题,以最大化期望奖励对策略参数进行搜索:

其轨迹(trajectory)分布可以表示为:

从这个trajectory的联合分布可以推出其概率图模型:


此时的概率图模型表示为:


通过上述这种定义方式,在确定性环境(deterministic dynamics)中很容易被理解,最高的奖励将有最大的出现概率。具体底奖励的轨迹出现的概率也会比较低。

我们可以从状态-动作(state-action)的消息中得到仅有状态(state)的消息:
 dat
dat




我们把这个东西称作soft value function。此时策略: