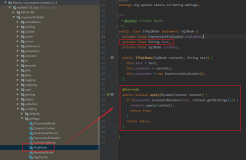
谈到<resultMap>标签,就不得不提字这个标签里面的其他一些标签的使用,比如常用的<id><result>,还有处理一对一和一对多关系的两个重要标签<association>和<collection>
这里先假设有几个POJO类叫User,Dept,Role,有几张表t_user,t_dept,t_role,tr_user_role
ClassUser{ privateLongid; privateStringname; privateIntegerage; privateDeptdept; privateList<Role>roles; //get set} ClassDept{ privateLongid; privateStringname; //get set} ClassRole{ privateLongid; privateStringname; //get set}
CREATETABLE `t_user` ( `id` int(11)NOTNULL AUTO_INCREMENT, `name` varchar(30)NULL DEFAULT NULL, `age` int(11)NULL DEFAULT NULL,`dept_id` int(11)NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE )CREATETABLE `t_dept` ( `id` int(11)NOTNULL AUTO_INCREMENT, `name` varchar(30)NULL DEFAULT NULL PRIMARY KEY (`id`) USING BTREE )CREATETABLE `t_role` ( `id` int(11)NOTNULL AUTO_INCREMENT, `name` varchar(30)NULL DEFAULT NULL PRIMARY KEY (`id`) USING BTREE )CREATETABLE `tr_user_role` ( `user_id` int(11), `role_id` int(11),)
他们之间的关系是这样的,一个用户一个机构,t_user表有t_dept表的dept_id外键;一个用户拥有多个角色,通过中间表tr_user_role建立这种一对多的联系。
下面介绍<association>和<collection>的使用方法。
<resultMapid="UserMap"type="package.User"><idcolumn="id"property="id"jdbcType="INTEGER"/><resultcolumn="name"property="name"/><resultcolumn="age "property="age "/><associationproperty="dept"javaType="package.Dept"><idproperty="id"column="DEPT_ID"/><resultproperty="name"column="DEPT_NAME"/></association><collectionproperty="roles"ofType="package.Role"column="ROLE_ID"><idproperty="id"column="ROLE_ID"/><resultproperty="name"column="ROLE_NAME"/></collection></resultMap><selectid="getList"parameterType="package.User"resultMap="UserMap"> SELECT t.ID,t.name,t.age,td.ID DEPT_ID,td.name DEPT_NAME,tr.ID ROLE_ID,tr.NAME ROLE_NAME FROM t_user t,t_dept td,tr_user_role tur,t_role tr <where> t.DEPT_ID = td.ID and t.ID = tur.USER_ID and tur.ROLE_ID = tr.ID </where></select>
通过上面的写法,就可以实现将一对一和一对多关系的数据自动的映射到User中去,假设就一个用户数据,这个用户数据对应一个机构,两个部门,而且sql语句在客户端执行的时候确实也有两个结果集,但是在java的po层,是一个用户数据,包含了一个机构数据和两个角色数据。上面的写法还有个更高级的用法,类似于子查询的方式,可能更好理解这种数据的包含关系
<resultMapid="UserMap"type="package.User"><idcolumn="id"property="id"jdbcType="INTEGER"/><resultcolumn="name"property="name"/><resultcolumn="age "property="age "/><associationproperty="dept"column=”DEPT_ID”select=”queryDeptByUserID”/><collectionproperty="roles"ofType="package.Role"column="ID"select=”queryRolesByUserID”/></resultMap><selectid="getList"parameterType="package.User"resultMap="UserMap"> SELECT t.ID,t.name,t.age,t.DEPT_ID FROM t_user t </select><selectid="queryDeptByUserID"parameterType="long"resultType="package.Dept"> SELECT t.ID,t.name t.DEPT_ID FROM t_dept t where t.ID = #{DEPT_ID} </select><selectid="queryRolesByUserID"parameterType="long"resultType="package.Role"> SELECT tr.ID,tr.name FROM tr_user_role tur,t_role tr where tur.ROLE_ID = tr.ID and tur.USER_ID=#{ID} </select>
上面的两种写法效果是一样的,但是第二种写法是不是感觉特别好理解这种映射关系。其实在执行的过程中发现第二种写法底层执行了三次sql查询,而第一种只执行了一次。这两种方法的使用看表数据量和查询效率来选择使用哪一种,以更快、更好的满足业务需求和更清晰的代码逻辑为原则去决定。