一、研究背景
目前的深度目标检测方法在学习预定义的对象类别集时,在大量的训练图像(PASCAL VOC、COCO)中进行了注释,达到了惊人的性能。不幸的是,它们的成功依然局限于检测少量的对象类别(例如,COCO中的80个类别)。
原因之一是大多数检测方法依赖于实例级边界框注释形成的监督,因此需要非常昂贵的人工标准工作来构建训练数据集,此外,当我们需要检测来自新类别的对象时,必须进一步为这个新类别注释图像中的大量边界框。
二、论文的目标
本文中,我们提出这样一个问题:
- 我们能否利用现有资源自动生成对象的边界框注释?
- 我们可以使用这些生成的注释来改进开放域目标检测吗?
大多数现有的方法只适用于有限的对象类别集。为了扩大基类,我们提出了一种从大规模【图像-标题对】中自动生成不同对象的伪边界框的注释方法。
我们的方法利用预先训练的视觉语言模型的定位能力来生成伪边界框标签,然后直接使用它们来训练目标检测器。
三、方法引入

3.1 之前的方法(左图)
训练期间依赖于人类的注释,试图在推理期间泛化到新类对象。
3.2 我们的方法(右图)
通过利用预先训练的语言视觉(VL)模型的定位能力,从大规模图像标题对中生成伪边界框注释。然后,我们利用它们来改进我们的开放域目标检测。
3.3 对比
与固定/小组基类的人工标注相比,我们的伪边界框标签生成器可以轻松的从大规模图像标题数据集中扩展到大组不同的对象,因此与以前的方法相比,能够在新对象上获得更好的检测性能。
四、论文核心
论文提到的框架主要包含两部分:
- 伪边界框标签生成器
- 开放域对象检测器
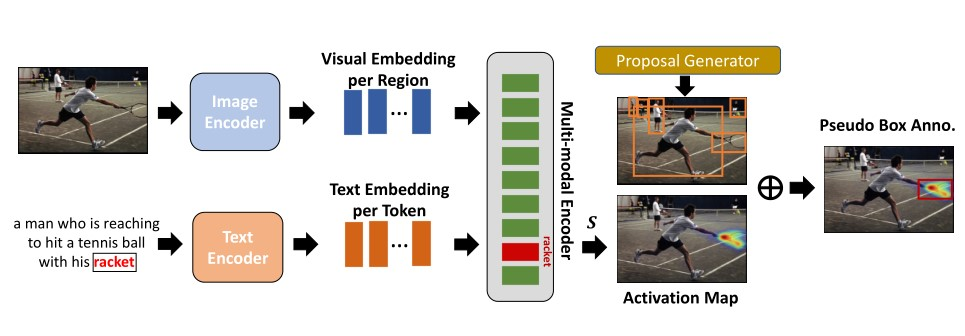
上图说明我们伪边界框标签的生成过程。
- 图像编码器:用于提取特征$V$
- 文本编码器:用于获取文本表示$T$,对应的标题$X=\{x_1,x_2,\cdots,x_{N_t}\}$,其中$N_t$是标题字数。
系统的输入是一个【图像-标题对】。使用图像和文本编码器来提取图像及其相应标题的视觉和文本表征。然后通过交叉注意的图像-文本交互获得多模态特征。我们在预定义的对象词汇表中保持感兴趣的对象。
对于标题中表征的每个感兴趣的对象(例如,图中的球拍),我们使用Grad-CAM在图像中可视化其激活映射。这个映射表明了图像区域对目标词的最终表示的贡献。
最后,我们通过选择与激活重叠最大的对象候选框来确定对象的伪边界框标签。
【我们的目标是:通过利用预训练的视觉语言模型中图像区域与对应标题中的单词之间的隐式对齐,为图像中感兴趣的对象生成伪边界框注释。】
交叉注意层:测量视觉区域表征与输入标题中的标记的相关性,并相应的计算所有视觉区域表征的加权平均值。
【视觉注意分数$A_{t}^l$可以直接反映不同视觉区域对标记$x_t$的重要性。因此基于注意力分数可视化激活映射,以在标题中给定名称的图像中定位。】
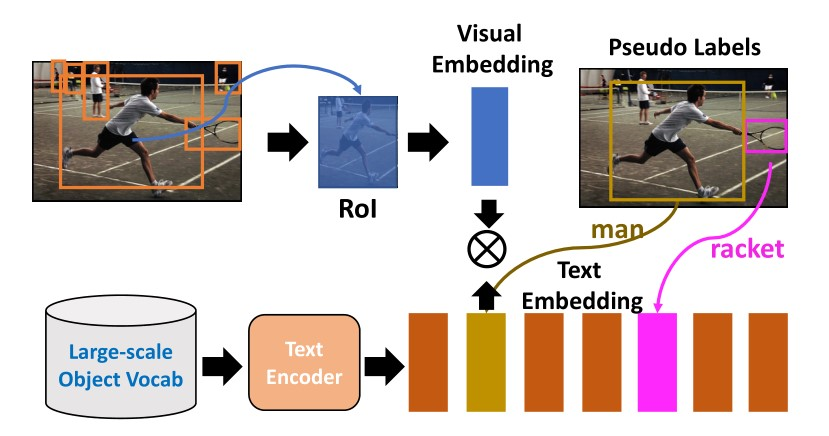
上图说明我们的探测器。
- 图像由特征提取器处理,然后是RPN网络;
- 通过在区域建议上应用ROI池化/ROI对齐来计算基于区域的特征,并获得相应的可视化表征
- 在训练过程中鼓励同一对象的视觉和文本表征的相似性
- 在推理过程中,给定一组感兴趣的对象类,与词汇表中的所有对象名称相比,如果区域建议的文本表征和该区域的可视化表征距离最小,则该区域建议与该对象类匹配。
五、实验
训练数据集:
- COCO Caption
- Visual-Genome
- SBU Caption
大约100万张图像。
默认词汇表由COCO、PASCAL VOC、Obeject 365和LVIS中的所有对象名称的联合构造的。
我们使用Mask-RCNN和ResNet-50作为开放词汇表检测器的基础,并在这里保持默认设置。
我们使用预训练的CLIP (ViT-B/32)文本编码器来提取词汇表中对象的文本嵌入。
在使用带有伪边界盒标签的大规模数据集训练开放词汇表检测器时,我们使用批处理大小为64,学习率为0.02;在COCO基类上进行可选微调时,批处理大小为8,学习率为0.0005。
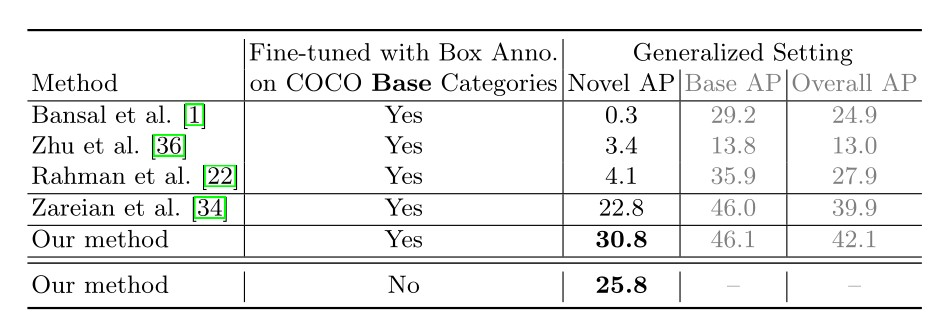
5.1 在COCO数据集上的表现
5.2 对其他数据集的泛化性能
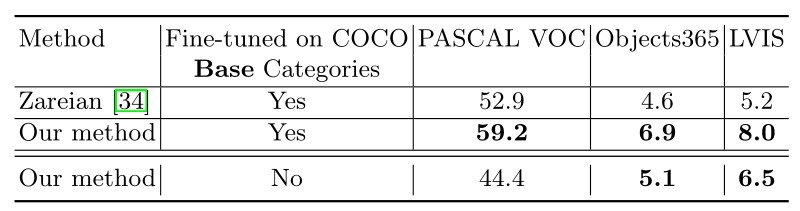
在推理过程中,区域将匹配到每个数据集的一个对象类别(包括背景)。
5.3 提案质量的影响

5.4 不同视觉-语言模式的影响
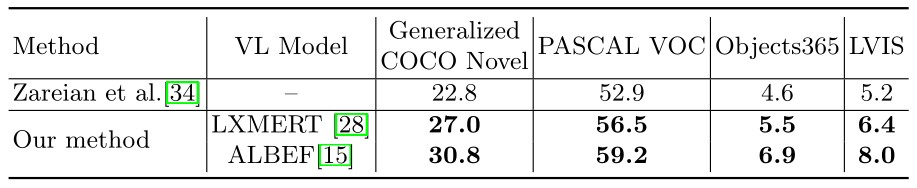
所有模型都在COCO基类上进行了微调。
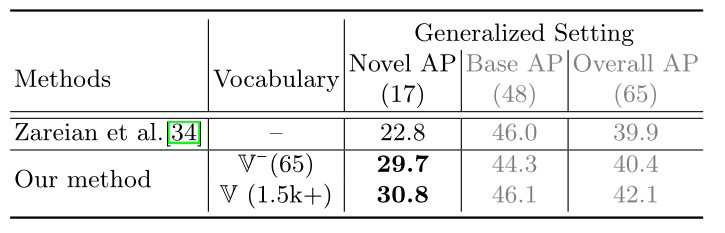
5.5 使用不同大小的词汇表生成伪标签的性能
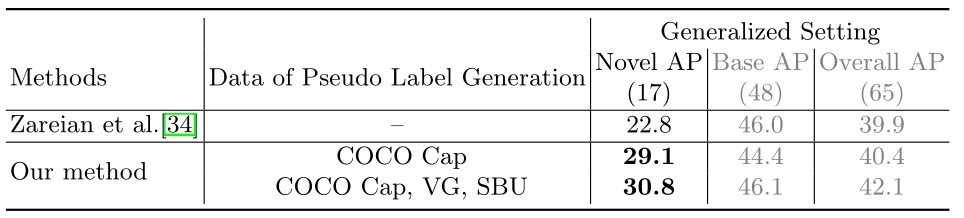
5.6 不同数量的数据生成伪标签
六、贡献和不足
6.1 贡献
- 提出了一种开放词汇表对象检测方法,可以从大规模图像-标题对生成的伪边界框注释来训练检测器。第一个在训练期间使用伪标签进行开放词汇表对象检测的工作;
- 利用现有的预训练的视觉语言模型,引入伪标签生成策略
- 在伪标签的帮助下,我们的方法很大程度上优于SOTA方法
6.2 不足
由于我们的伪标签生成器在没有人工干预的情况下从输入标题中挖掘对象的注释,因此由于表征在语言描述中的偏见,我们的伪标签可能是有偏见的。
手动过滤词汇表中有偏见的对象名称可能是一种有效的解决方案。
