回顾 1.0 版
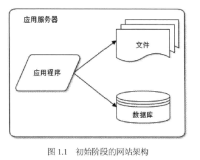
我们来回顾下 1.0 版 的内容,需求上经过分析,最终 1.0 版只是做一个 MVP——最小可行性产品,只完成最简化的核心流程,即:注册 ——> 登录 ——> 入金 ——> 交易 ——> 出金 。架构设计上,从 API 设计到关键流程设计,再到数据库设计,最后服务端的设计,基本都以节省开发成本为考虑因素,采用了最低成本的设计方案。
总的来说,MVP 版本整体设计是前后端分离的。API 统一采用 HTTP 通信协议 + JSON 传输协议,并加上 TLS 对传输数据进行加密。用户鉴权采用了 JWT 方案,可实现为无状态化。API 接口总共定义了 19 个,按业务领域划分为了 用户、账户、交易、行情 4 个模块。查询类的读请求统一用 GET 方法,非查询类请求统一用 POST 方法。实现流程上,也没用缓存,没用 MQ 等中间件,数据库只用了 MySQL,交易撮合也采用了实现简单的数据库撮合的方案。接入了两个第三方平台,一个是阿里云邮箱推送平台,用于发送邮件;一个是用于对接以太坊区块链的 infura 平台。数据库设计方面还提了一些设计规范和原则,按照 DDD 的设计思想,最后设计出了 9 张表。服务端是个单体应用,内部采用了简单的三层架构,分为了 API 层、Service 层、DAO 层。
整体的架构图大致如下:

这 1.0 版本,专业的人应该能看出来,存在一些比较重要的问题有待解决:
- 有些业务功能是缺失的,包括找回密码、修改密码、退出登录、KYC 认证(实名认证)、管理后台。
- 还有些待完善的业务,包括增加更多交易对、增加更多周期的 K 线图数据。
- 接口轮询请求行情数据,并从数据库读取,延迟高、效率低、性能差。
- 数据库撮合的性能太差。
接下来,我们就来研究下解决这些问题的设计方案。
迭代业务需求
对于缺失的业务功能,找回密码、修改密码、退出登录,这几个就是单纯地增加 API 接口并实现业务逻辑即可,很简单。KYC 认证需要上传证件照片,可以接入一个第三方的文件存储服务。管理后台目前比较重要的功能应该包括:用户管理、KYC 审核、提现审核、订单管理、交易对管理等。
而待完善的业务功能,增加更多交易对的支持,主要也是对接多几个主流的区块链 API,如今主流区块链基本都有比较成熟的第三方 API 的,接入也比较容易。增加更多周期的 K 线图数据也简单,根据不同周期的计算公式将数据累加计算并记录即可。
下面,还有相关的其他一些比较重要的设计点需要进行补充。
先对密码相关的设计进行补充,从用户在客户端输入密码,到网络传输,再到服务端数据存储,在整个流程中,为了保证密码的安全性,最佳实践的方案应该是怎样的?以下是我总结出来的几个要点:
- TLS 是基础;
- 密码再进行单独加密,加密算法要用非对称加密,比如 RSA、ECC;
- 如果用户登录时密码错误,那错误提示语不要直接提示“密码错误”,只需要给出一个大概的提示,比如“用户名或密码错误”;
- 密码错误次数连续超过 N 次,比如 6 次,则将用户锁定一段时间;
- 数据库用 慢哈希 + Salt 的方案进行存储,不同用户用不同 Salt 值,慢哈希算法主要有:Argon2、Scrypt、Bcrypt、PBKDF2;
- 增加多重校验,比如登录设备检测、指纹识别、人脸识别、手机验证码等。
不少人觉得已经有 TLS 就可以不对密码再进行单独加密了,这其实是不对的。TLS 能保证的只是传输过程中第三方抓包看到的是密文,但防不了在客户端和服务端截取数据的黑客,要在服务端截取数据比较难,但在客户端截取还是比较容易的。最简单的,你在浏览器访问知乎、京东等知名网站并用抓包工具抓取请求,就会发现,虽然是 HTTPS 请求,但看到的数据并非密文,而是明文的。对 HTTPS 的攻击手段也不少,比如降级攻击、中间人攻击等。所以,只用 HTTPS 做防护是不够的。
对密码加密为什么推荐用非对称加密,而不用单向哈希或对称加密呢?如果用单向哈希,比如 MD5/SHA,那对服务端来说,实际密码是哈希后的值,而不是用户的原密码,以后要升级加密算法就很麻烦;那对黑客来说,也没必要破解出用户的原密码,就直接用哈希后的密码向服务端请求即可通过校验。如果用对称加密,比如 AES/DES,那客户端需要安全保存加密密钥,这是非常难的。而用非对称加密,公钥保存在客户端就算泄露了也没有关系。
数据库存储方面,以前思考的方向是如何防止数据泄露,但现在更多考虑的则是泄露后如何防止数据被还原。意思就是说,我们要做到,就算被盗取了所有数据和代码,依然难以破解出原密码。要实现此目标,主要思路就是增加破解的成本,要让破解的成本远大于收益,这样就没有破解的意义了。而慢哈希 + Slat 的方案就能达到此目标,由于每个用户的 Salt 值不同,就无法用彩虹表进行批量破解;而加上慢哈希,要暴力破解的时间成本也呈指数级增加。
增加多重校验则让安全性更上 N 层楼了,现在微信、支付宝、以及很多金融类应用,都普遍只用 6 位数字的支付密码,之所以安全,也是因为有了多重校验机制。假设每层校验单独被破解的概率为 30%,那加上三层校验之后,被破解的概率就变为:30% * 30% * 30% = 2.7%,安全性大大提升。
那回到我们的交易系统,在这个迭代版本中,是应该增加这些功能的,开发成本也不会很高。多重校验方面,登录和支付时可以增加个手机验证的二次校验功能,这方案实现最简单,也一定程度上增加了安全性。
聊完了密码安全的设计,接着再对管理后台的设计做一些说明。
管理端和客户端有着很不一样的功能特性,很多业务逻辑也都不一样,管理端的用户相比客户端用户还有着更多的数据权限,因此,管理端和客户端通常都是分开为不同服务,但底层数据库则是同一套。加上管理后台之后,整个交易系统的整体架构大致如下:

优化行情问题
我们的行情问题,其实可以拆解为两个问题,一是客户端获取行情数据的问题,二是从数据库读取行情数据的问题。我们分别来设计解决这两个问题,再合并起来,也就能解决整体的问题了。
客户端获取行情数据
客户端获取行情数据,本质上是 Web 端与服务端进行即时通讯的问题,而实现 Web 端即时通讯的方式,其实有四种:轮询、长轮询、长连接、WebSocket。
轮询(Polling),也叫短轮询,只是客户端定时向服务端发送请求,服务端再返回响应数据,所以获取的数据其实并不是实时的,存在延迟。另外,因为不停地请求服务端,很多时候其实并没有新的数据更新,因此大部分请求属于无效请求,这对服务端来说,就是严重浪费了其资源。轮询的优点就是简单、易理解、容易实现,这也是我们第一版选择采用轮询方式的原因。
长轮询(Long Polling) 也是由客户端发起请求,与短轮询不同的在于,服务端接收到请求之后,不会马上返回响应,而会将请求挂起,直到数据有更新才返回响应。客户端接收到响应之后,就马上发下一次请求,所以本质上依然还是轮询。长轮询相比短轮询,明显减少了很多无效请求,也节约了资源。但缺点在于,连接挂起也会导致资源的浪费。
长连接(SSE) 在本质上与短轮询和长轮询不同,它允许服务端推送数据到客户端。其流程是这样的:客户端发送请求,服务端接收到请求后进行阻塞,并保持连接,当服务端有数据需要响应时,使用保持住的连接进行响应,并保持住连接。长连接适用于服务端到客户端单向推送的场景。不过,长连接的缺点就是只适用于高级浏览器,IE 不包括在内。
WebSocket 则完全不一样,除了最初建立连接时用 HTTP 协议,其他时候都是直接基于 TCP 协议进行通信的,可以实现客户端和服务端的全双工通信,性能高、开销小,是目前实现 Web 端即时通讯的最佳选择。而且,不只是在 Web 端,在 App 端也同样很适用。因此,我们客户端获取行情数据的优化方案,也是采用 WebSocket 最合适。
不过,应用 WebSocket,实现起来相比 HTTP 会复杂得多,设计上与 HTTP API 也不同,如果设计得不好,依然会浪费资源,因此,有必要说明一下。
首先,客户端与服务端建立连接之后,客户端需要什么数据,一般是通过发送订阅消息的方式通知服务端的,比如像这样:
{ "subscribe": "market.ethusdt.kline.1min" }
这是一条订阅 ETH/USDT 交易对的 1 分钟 K 线数据的消息,服务端接收到该订阅后,只要该交易对的 1 分钟 K 线数据有更新,就会不断将更新数据推送给客户端,直到用户取消了订阅,或断开了连接。取消订阅也简单,客户端再发一条消息类似这样:
{ "unsubscribe": "market.ethusdt.kline.1min" }
不过,订阅消息只是用来接收后续更新的数据,即增量数据。但客户端有时候还需要获取全量数据,尤其是初始化的时候,这时可以发一个一个性的请求消息,就和 HTTP 请求类似,比如,我们要获取 ETH/USDT 交易对的 1 分钟 K 线图的初始全量数据,我们可以发这样一条消息给服务端:
{ "request": "market.ethusdt.kline.1min" }
服务端接收到这条信息之后,就一次性返回全量数据。
理想情况下,客户端与服务端的连接会一直保持,只要两方不主动断开。但实际情况却会因为各种原因导致其中一端异常断开,而另一端却不知道。更多情况下是客户端异常断开了连接,而服务端不知道,依然会不断向客户端推送数据,且这些数据会丢失。为了应对这种情况,就需要一种机制来检测两端是否依然处于连接的状态,而这种机制就是心跳检测。心跳检测其实就是由其中一端定时(比如每隔 5 秒)向另一端发送数据包(也叫心跳包),另一端收到数据包之后马上回送一个数据包,以此检测两端的连接是否正常。心跳包的实现也简单,发起端只要发起一个 ping 消息,另一端再回复一个 pong 消息即可,类似这样:
{ "ping": 1606972817326 } { "pong": 1606972817326 }
后面那串数字可以是发送心跳包时的时间戳,回复消息用同一个时间戳,就知道是回复哪个心跳包的。
如果有一端超过三次没收到对方的心跳包了,那就可以认为对方掉线了。这时候,如果客户端还在线,就需要客户端发起重连。
数据库读取行情数据
直接从当前的 MySQL 数据库读取行情数据,主要会产生什么问题呢?
因为我们是轮询请求行情数据的,所以就会不间断地对数据库产生读请求,且随着在线用户越来越多,那对数据库的并发读也会越来越多,而且还是不间断的,所以,很容易会达到数据库的性能瓶颈,达到性能瓶颈的话,还会影响写请求。
而要解决数据库读性能瓶颈的问题,大部分人最先想到的解决方案就是读写分离。读写分离其实就是将数据库分为了主库和从库,读请求到从库读,主库处理写请求,写完数据之后再复制到从库。这样,就将大量读操作的压力转移到从库了,如果单个从库无法支撑大量读请求,还可以部署多个从库,实现负载均衡。一般用 MyCat 来实现读写分离。
不过,使用读写分离的话,还会存在主从数据一致性的问题。主库和从库需要达成数据一致性,从库才能读取到正确数据,因此,主从之间就存在数据同步(复制)的机制。虽然,主从复制有三种机制:异步复制、全同步复制、半同步复制。但不管用哪种复制方案,由于数据库已经变成了集群化,那高性能和一致性之间就难以兼得。异步复制能保持高性能,但无法保证数据的一致性。全同步复制保证了一致性,但严重牺牲了性能。半同步复制是个折中方案,算是取两者的平衡。
其实,要解决我们的问题,用读写分离并不是唯一方案,更不是最优方案。除了读写分离,还可以使用 Redis 缓存,还可以使用 MongoDB。应该优先选择用 Redis 缓存,因为其读写性能是最高的。
那么,选择了 Redis,接下来就需要思考用什么样的数据结构去存储各种行情数据更合适。我们的行情数据包括了深度数据、成交记录、K 线数据、Ticker 数据。
深度数据主要包含了买卖盘的价格和数量,需要按价格进行排序,且会频繁变更,比较适合用 sorted set 保存。买盘和卖盘分开不同的 key 保存,score 设置为价格,value 则设为价格和数量的二元组。另外,深度数据的特点是每个价格只能有一条数据,所以,相同 score 的记录不能存在多条,因此,需更新某个价格的盘口数量时,需要先删除该价格对应的 score 记录,然后再插入。
成交记录则是随着时间不断增加的,Ticker 数据还会根据最新成交记录而更新,K 线数据也是基于成交记录累加计算出来的。那么,成交记录比较适合用消息队列(MQ) 的方式保存,Ticker 和 K 线的处理线程就可以监听该队列,获取最新成交并更新各自的数据。Redis 5.0+ 版本的 stream 类型就很适合这种场景。
K 线数据包括了每个时间周期内的开盘价、收盘价、最高价、最低价、成交量等,记录也是随着时间不断增加的,但最近的一个时间周期内,即最新一条记录需要频繁修改,比较适合的存储结构就是 list 了。
Ticker 数据展示的主要是当天的开盘价、最高价、最低价、最新价、交易量等,不需要有多条记录,只需要一条记录即可,会根据成交记录的结果更新部分数据,用 hash 类型来存储最为合适了。
合并解决行情问题
接着,就要把两个独立问题的设计方案合并起来,就能串联成一个整体的解决方案了。
其实,也很容易,先从成交记录说起,这可以算是数据流的起点。每撮合成功一笔成交记录,就保存到 Redis 的成交记录 MQ 中,并对该 MQ 增加监听线程,监听到新成交之后,主要有 4 个操作:
- 通过 WebSocket 将最新成交记录推送给订阅了的客户端;
- 更新最新的 K 线数据并缓存,然后通过 WebSocket 将最新 K 线记录推送给订阅了对应 K 线数据的客户端;
- 更新 Ticker 数据并缓存,再通过 WebSocket 将最新的 Ticker 信息推送给订阅了 Ticker 数据的客户端;
- 更新深度数据,减掉已成交的量。
触发深度数据变更的地方有几个,除了有成交记录,还有用户撤单成功时,都会减少深度数据对应价格的数量。以及,用户下单后,委托单未能即时成交的剩余量会增加对应价格的数量。
另外,WebSocket 推送深度数据不是由某一事件触发的,而是定时推送的,一般是每隔 1 秒推送一次。
最后,可以发现,其实整个行情模块是相对独立的,完全可以抽离成独立的服务。而且,从另一方面来说,行情 API,后续是要对外开放的,变成开放 API,那为了不影响内部 API 服务,肯定也是需要独立服务的。既然如此,早点抽离成单独服务,对后续的改动最少。抽离后,那整个交易系统的整体架构就变成了下图所示:

升级撮合技术
数据库撮合的性能,一般是在 100 TPS 左右,性能很低,主要原因就在于与数据库交互太多,I/O 也很多,且还会受数据库事务逻辑所约束。数据库撮合系统,想要提升性能,只能靠升级硬件,要求数据库的硬件配置非常高,成本也非常高昂。而且,因为撮合的规则,要求撮合时只能串行,不能并行,所以也没法用横向扩容服务器的方式来提高整体性能。
撮合的逻辑,是按照「价格优先、时间优先」的原则进行匹配成交的,未能即时匹配成交的订单,就会被放入交易委托账本(Orderbook)。Orderbook 本质上就是买和卖的两个队列,两个队列都按照价格优先、时间优先的原则进行排序。所谓价格优先、时间优先,即是说:卖单队列的委托单是按价格由低到高排序,买单队列则相反,按价格由高到低排序;相同价格的委托单,则是按下单时间的先后来排序。

如上图,每个小方格表示一个委托单,标 H 的是排在头部的委托单,N 则是与 H 同价格但下单时间上排在 H 后面的委托单,S 则是下一档位价格的第一个委托单。可以从图中明显看出,水平方向,委托单是按时间排序的,垂直方向,又是按价格排序的。
撮合的时候,都是先取出 H 委托单与新委托单进行匹配。如果新委托单是买单,则获取卖单队列的 H 单出来匹配;如果新委托单是卖单,则获取买单队列的 H 单。如果 H 单全部匹配成交了,那标识为 N 的委托单就变成了新的 H 单。如果第一排的全部委托单都匹配完了,那就 S 单会变成新的 H 单。
采用数据库撮合技术,就只有保存了所有订单的订单表,没办法将 Orderbook 保存成以上的数据结构,每次撮合判断时,都需要根据复杂的查询条件从全表中查询出 H 订单,很耗时,性能自然上不去。
所以,现在业界基本都不再采用数据库撮合了,而改用内存撮合了。内存撮合的性能,一台很普通的服务器都能轻松达到 1 万 TPS,内存配置高的甚至达到 10 万 TPS 也不是难事。
内存撮合之所以能有这么高的性能提升,有两个比较关键的原因:
- 把整个 Orderbook 都缓存在了内存中,直接在内存中操作数据,速度非常快。
- 在内存中用上图的数据结构保存 Orderbook 比较容易,每次撮合时,就能很快速地取出头部订单,不需要全表查询。
在具体的实现方案上,其实还有两种做法:一是采用 Redis 保存 Orderbook;二是直接用编程语言的对象存储 Orderbook。其实,业界说的内存撮合,是用第二种方案实现的,但有些人将内存撮合理解成内存数据库撮合,所以才产生了第一种方案。
不过,内存撮合的缺点就是内存的易失性,服务器出现故障停机时,所有的交易数据将会丢失,系统的可靠性以及一致性都相应大幅降低。要解决此问题,有复杂方案,也有简单方案。复杂方案主要用多机热备技术来保证可靠性,再用复制状态机技术来保证一致性。简单方案就是直接重启服务器,初始化时从数据库查询出订单并重新加载到内存中,简单粗暴。而我们目前比较适合先用简单方案,复杂方案的实现成本太高了,在当前阶段的投入产出比不高。
最后,使用内存撮合,严重依赖于服务器内存,不适合与其他服务共享内存,所以也应该将其抽离成单独的撮合引擎服务。这个抽离其实也简单,因为撮合引擎的输入是定序的订单队列,输出也是用队列。最终,我们的交易系统整体架构又变成了下图:

总结
至此,1.0 版本遗留的几个重要问题就一一解决了,解决完这些问题后,我们的版本可以说就升级到 2.0 了。完善了业务功能,优化了行情服务,升级了撮合技术。整套系统还划分为了行情服务、客户端服务、撮合服务、管理端服务,但其实还不是微服务架构,只是四个单体而已。下篇文章我们再来分析看看下一阶段又应该如何演进。