域服务,基础结构服务和应用程序服务(Domain services, Infrastructure services and Application services)
域服务(domain service)是在域层内定义的域服务,但实现可以是基础结构层的一部分。存储库是域服务,其实现确实在基础结构层中,而工厂也是域服务,其实现通常在域层内。特别是在适当的模块中定义了存储库和工厂:CustomerRepository位于客户模块中,依此类推。
更一般地说,域服务是任何不容易在实体中生存的业务逻辑。埃文斯建议在两个银行账户之间进行转账服务,但我不确定这是最好的例子(我会将转账本身建模为一个实体)。但另一种域服务是一种充当其他有界上下文的代理。例如,我们可能希望与暴露开放主机服务的General Ledger系统集成。我们可以定义一个公开我们需要的功能的服务,以便我们的应用程序可以将条目发布到总帐。这些服务有时会定义自己的实体,这些实体可能会持久化;这些实体实际上影响了在另一个BC中远程保存的显着信息。
我们还可以获得技术性更强的服务,例如发送电子邮件或SMS文本消息,或将Correspondence实体转换为PDF,或使用条形码标记生成的PDF。接口在域层中定义,但实现在基础架构层中非常明确。因为这些非常技术性服务的接口通常是根据简单的值类型(而不是实体)来定义的,所以我倾向于使用术语基础结构服务(infrastructure service)而不是域服务。但是如果你想成为一个“电子邮件”BC或“SMS”BC的桥梁,你可以想到它们。
虽然域服务既可以调用域实体也可以调用域实体,但应用服务(application service)位于域层之上,因此域层内的实体不能调用,只能反过来调用。换句话说,应用层(我们的分层架构)可以被认为是一组(无状态)应用服务。
如前所述,应用程序服务通常处理交叉和安全等交叉问题。他们还可以通过以下方式与表示层进行调解:解组入站请求;使用域服务(存储库或工厂)获取对与之交互的聚合根的引用;在该聚合根上调用适当的操作;并将结果编组回表示层。
我还应该指出,在某些体系结构中,应用程序服务调用基础结构服务。因此,应用服务可以直接调用PdfGenerationService,传递从实体中提取的信息,而不是实体调用PdfGenerationService将其自身转换为PDF。这不是我的特别偏好,但它是一种常见的设计。我很快就会谈到这一点。
好的,这完成了我们对主要DDD模式的概述。在Evans 500 +页面书中还有更多内容 - 值得一读 - 但我接下来要做的是突出显示人们似乎很难应用DDD的一些领域。
问题和障碍
实施分层架构
这是第一件事:严格执行架构分层可能很困难。特别是,从域层到应用层的业务逻辑渗透可能特别隐蔽。
我已经在这里挑出了Java的EJB2作为罪魁祸首,但是模型 - 视图 - 控制器模式的不良实现也可能导致这种情况发生。控制器(=应用层)会发生什么,承担太多责任,让模型(=域层)变得贫血。事实上,有更新的Web框架(在Java世界中,Wicket [10]是一个崭露头角的例子),出于这种原因明确地避免了MVC模式。
表示层模糊了域层
另一个问题是尝试开发无处不在的语言。领域专家在屏幕方面谈话是很自然的,因为毕竟,这就是他们可以看到的系统。要求他们在屏幕后面查看并在域概念方面表达他们的问题可能非常困难。
表示层本身也可能存在问题,因为自定义表示层可能无法准确反映(可能会扭曲)底层域概念,从而破坏我们无处不在的语言。即使不是这种情况,也只需要将用户界面组合在一起所需的时间。使用敏捷术语,速度降低意味着每次迭代的进度较少,因此对整个域的深入了解较少。
存储库模式的实现
从更技术性的角度来看,新手有时似乎也会混淆将存储库(在域层中)与其实现(在基础架构层中)的接口分离出来。我不确定为什么会这样:毕竟,这是一个非常简单的OO模式。我想这可能是因为埃文斯的书并没有达到这个细节水平,这让一些人变得高高在上。但这也可能是因为替换持久性实现(根据六边形体系结构)的想法并不普遍,导致持久性实现渗透到域层的系统。
服务依赖项的实现
另一个技术问题 - 在DDD从业者之间可能存在分歧 - 就实体与域/基础设施服务(包括存储库和工厂)之间的关系而言。有些人认为实体根本不应该依赖域服务,但如果是这种情况,则外部应用程序服务与域服务交互并将结果传递给域实体。根据我的思维方式,这使我们走向了一个贫血的领域模型。
稍微柔和的观点是实体可以依赖于域服务,但应用程序服务应该根据需要传递它们,例如作为操作的参数。我也不喜欢这个:对我而言,它将实现细节暴露给应用层(“这个实体需要这样一个服务才能完成这个操作”)。但是许多从业者对这种方法感到满意。
我自己的首选方案是使用依赖注入将服务注入实体。实体可以声明它们的依赖关系,然后基础结构层(例如Hibernate,Spring或其他一些框架)可以将服务注入实体:
public class Customer { … private OrderFactory orderFactory; public void setOrderFactory(OrderFactory orderFactory) { this.orderFactory = orderFactory; } … public Order placeOrder( … ) { Order order = orderFactory.createOrder(); … return order; } }
一种替代方法是使用服务定位器模式。例如,将所有服务注册到JNDI中,然后每个域对象查找它所需的服务。在我看来,这引入了对运行时环境的依赖。但是,与依赖注入相比,它对实体的内存需求较低,这可能是一个决定性因素。
不合适的模块化
正如我们已经确定的那样,DDD在实体之上区分了几种不同的粒度级别,即聚合,模块和BC。获得正确的模块化水平需要一些练习。正如RDBMS模式可能被非规范化一样,系统也没有模块化(成为泥浆的大球)。但是,过度规范化的RDBMS模式(其中单个实体在多个表上被分解)也可能是有害的,过模块化系统也是如此,因为它变得难以理解系统如何作为整体工作。
我们首先考虑模块和BC。记住,模块类似于Java包或.NET命名空间。我们希望两个模块之间的依赖关系是非循环的,但是如果我们确定(比如说)客户依赖于订单,那么我们不需要做任何额外的事情:客户可以简单地导入Order包/命名空间并使用它接口和类根据需要。
但是,如果我们将客户和订单放入单独的BC中,那么我们还有更多的工作要做,因为我们必须将客户BC中的概念映射到BC订单的概念。在实践中,这还意味着在客户BC中具有订单实体的表示(根据前面给出的总分类帐示例),以及通过消息总线或其他东西实际协作的机制。请记住:拥有两个BC的原因是当有不同的最终用户和/或利益相关者时,我们无法保证不同BC中的相关概念将朝着相同的方向发展。
另一个可能存在混淆的领域是将实体与聚合区分开来。每个聚合都有一个实体作为其聚合根,对于很多很多实体,聚合将只包含这个实体(“琐碎”的情况,正如数学家所说的那样)。但我看到开发人员认为整个世界必须存在于一个聚合中。因此,例如,订单包含引用产品的OrderItems(到目前为止一直很好),因此开发人员得出结论,产品也在聚合中(不!)更糟糕的是,开发人员会观察到客户有订单,所以想想这个意味着我们必须拥有Customer / Order / OrderItem / Product的巨型聚合(不,不,不!)。关键是“客户有订单”并不意味着暗示汇总;客户,订单和产品都是集合的根源。
实际上,一个典型的模块(这是非常粗糙和准备好的)可能包含六个聚合,每个聚合可能包含一个实体和几个实体之间。在这六个中,一个好的数字可能是不可变的“参考数据”类。还要记住,我们模块化的原因是我们可以理解一件事(在一定的粒度级别)。所以要记住,典型的人一次只能保持在5到9个之间[11]。
入门
正如我在开始时所说,你可能在DDD之前遇到过很多想法。事实上,我所说过的每一个Smalltalker(我不是一个,我不敢说)似乎很高兴能够在EJB2等人的荒野岁月之后回归域驱动的方法。
另一方面,如果这些东西是新的怎么办?有这么多不同的方式来绊倒,有没有办法可靠地开始使用DDD?
如果你环顾一下Java领域(对.NET来说并不那么糟糕),实际上有数百个用于构建Web应用程序的框架(JSP,Struts,JSF,Spring MVC,Seam,Wicket,Tapestry等)。从持久性角度(JDO,JPA,Hibernate,iBatis,TopLink,JCloud等)或其他问题(RestEasy,Camel,ServiceMix,Mule等),有很多针对基础架构层的框架。但是很少有框架或工具来帮助DDD所说的最重要的层,即域层。
自2002年以来,我一直参与(现在是一个提交者)一个名为Naked Objects的项目,Java上的开源[12]和.NET上的商业[13]。虽然Naked Objects没有明确地开始考虑领域驱动的设计 - 事实上它早于Evans的书 - 它与DDD的原理非常相似。它还可以轻松克服前面提到的障碍。
您可以将Naked Objects视为与Hibernate等ORM类似。ORM构建域对象的元模型并使用它来自动将域对象持久保存到RDBMS,而Naked Objects构建元模型并使用它在面向对象的用户界面中自动呈现这些域对象。
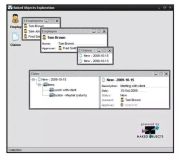
开箱即用的Naked Objects支持两个用户界面,一个富客户端查看器(参见图9)和一个HTML查看器(参见图10)。这些都是功能完备的应用程序,需要开发人员只编写要运行的域层(实体,值,存储库,工厂,服务)。

Figure 9: Naked Objects Drag-n-Drop Viewer

我们来看看Claim类的(Java)代码(如屏幕截图所示)。首先,这些类基本上是pojos,尽管我们通常从便捷类AbstractDomainObject继承,只是为了分解注入通用存储库并提供一些帮助方法:
public class Claim extends AbstractDomainObject { ... } Next, we have some value properties: // {{ Description private String description; @MemberOrder(sequence = "1") public String getDescription() { return description; } public void setDescription(String d) { description = d; } // }} // {{ Date private Date date; @MemberOrder(sequence="2") public Date getDate() { return date; } public void setDate(Date d) { date = d; } // }} // {{ Status private String status; @Disabled @MemberOrder(sequence = "3") public String getStatus() { return status; } public void setStatus(String s) { status = s; } // }}
这些是简单的getter / setter,返回类型为String,日期,整数等(尽管Naked Objects也支持自定义值类型)。接下来,我们有一些参考属性:
// {{ Claimant private Claimant claimant; @Disabled @MemberOrder(sequence = "4") public Claimant getClaimant() { return claimant; } public void setClaimant(Claimant c) { claimant = c; } // }} // {{ Approver private Approver approver; @Disabled @MemberOrder(sequence = "5") public Approver getApprover() { return approver; } public void setApprover(Approver a) { approver = a; } // }}
这里我们的Claim实体引用其他实体。实际上,Claimant和Approver是接口,因此这允许我们将域模型分解为模块,如前所述。
实体也可以拥有实体集合。在我们的案例中,Claim有一个ClaimItems的集合:
// {{ Items private List<ClaimItem> items = new ArrayList<ClaimItem>(); @MemberOrder(sequence = "6") public List<ClaimItem> getItems() { return items; } public void addToItems(ClaimItem item) { items.add(item); } // }}
我们还有(Naked Objects调用的)动作,即submit和addItem:这些都是不代表属性和集合的公共方法:
// {{ action: addItem public void addItem( @Named("Days since") int days, @Named("Amount") double amount, @Named("Description") String description) { ClaimItem claimItem = newTransientInstance(ClaimItem.class); Date date = new Date(); date = date.add(0,0, days); claimItem.setDateIncurred(date); claimItem.setDescription(description); claimItem.setAmount(new Money(amount, "USD")); persist(claimItem); addToItems(claimItem); } public String disableAddItem() { return "Submitted".equals(getStatus()) ? "Already submitted" : null; } // }} // {{ action: Submit public void submit(Approver approver) { setStatus("Submitted"); setApprover(approver); } public String disableSubmit() { return getStatus().equals("New")? null : "Claim has already been submitted"; } public Object[] defaultSubmit() { return new Object[] { getClaimant().getApprover() }; } // }}
这些操作会在Naked Objects查看器中自动呈现为菜单项或链接。而这些行动的存在意味着Naked Objects应用程序不仅仅是CRUD风格的应用程序。
最后,有一些支持方法可以显示标签(或标题)并挂钩持久性生命周期:
// {{ Title public String title() { return getStatus() + " - " + getDate(); } // }} // {{ Lifecycle public void created() { status = "New"; date = new Date(); } // }}
之前我将Naked Objects域对象描述为pojos,但您会注意到我们使用注释(例如@Disabled)以及命令式帮助器方法(例如disableSubmit())来强制执行业务约束。Naked Objects查看器通过查询启动时构建的元模型来尊重这些语义。如果您不喜欢这些编程约定,则可以更改它们。
典型的Naked Objects应用程序由一组域类组成,例如上面的Claim类,以及存储库,工厂和域/基础结构服务的接口和实现。特别是,没有表示层或应用层代码。那么Naked Objects如何帮助解决我们已经确定的一些障碍?
- 实施分层架构:因为我们编写的唯一代码是域对象,域逻辑无法渗透到其他层。实际上,Naked Objects最初的动机之一就是帮助开发行为完整的对象
- 表示层模糊了域层:因为表示层是域对象的直接反映,整个团队可以迅速加深对域模型的理解。默认情况下,Naked Objects直接从代码中获取类名和方法名,因此强烈要求在无处不在的语言中获得命名权。通过这种方式,Naked Objects也支持DDD的模型驱动设计原理
- 存储库模式的实现:您可以在屏幕截图中看到的图标/链接实际上是存储库:EmployeeRepository和ClaimRepository。Naked Objects支持可插入对象存储,通常在原型设计中,我们使用针对内存中对象存储的实现。当我们转向生产时,我们会编写一个实现数据库的实现。
- 服务依赖项的实现:Naked Objects会自动将服务依赖项注入每个域对象。这是在从对象库中检索对象时,或者首次创建对象时完成的(请参阅上面的newTransientInstance())。事实上,这些辅助方法所做的就是委托Naked Objects提供的名为DomainObjectContainer的通用存储库/工厂。
- 不合适的模块化:我们可以通过正常方式使用Java包(或.NET命名空间)模块化为模块,并使用Structure101 [14]和NDepend [15]等可视化工具来确保我们的代码库中没有循环依赖。我们可以通过注释@Hidden来模块化为聚合,任何聚合对象代表我们可见聚合根的内部工作;这些将不会出现在Naked Objects查看器中。我们可以编写域和基础设施服务,以便根据需要桥接到其他BC。
- Naked Objects提供了许多其他功能:它具有可扩展的体系结构 - 特别是 - 允许实现其他查看器和对象存储。正在开发的下一代观众(例如Scimpi [16])提供更复杂的定制功能。此外,它还提供多种部署选项:例如,您可以使用Naked Objects进行原型设计,然后在进行生产时开发自己的定制表示层。它还与FitNesse [17]等工具集成,可以自动为域对象提供RESTful接口[18]。
下一步
领域驱动的设计汇集了一组用于开发复杂企业应用程序的最佳实践模式。一些开发人员多年来一直在应用这些模式,对于这些人来说,DDD可能只是对他们现有实践的肯定。但对于其他人来说,应用这些模式可能是一个真正的挑战。
Naked Objects为Java和.NET提供了一个框架,通过处理其他层,团队可以专注于重要的部分,即域模型。通过直接在UI中公开域对象,Naked Objects允许团队非常自然地构建一个明确无处不在的语言。随着域层的建立,团队可以根据需要开发更加量身定制的表示层。
那么,下一步呢?
嗯,DDD本身的圣经是埃里克埃文斯的原着,“领域驱动设计”[1],建议阅读所有人。雅虎新闻组DDD [19]也是一个非常好的资源。如果你有兴趣了解Naked Objects的更多信息,你可以搜索“使用Naked Objects的域驱动设计”[20],或者博客[21](NO for Java)或Naked Objects网站[13 ](对于.NET而言)。快乐DDD'ing!