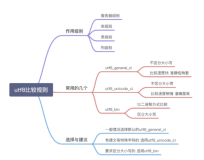
1:字符集 和 比较规则 简介
2:MySQL 中,支持的 字符集和比较规则
- 默认编码集:
- MySQL 5:latin1;
- MySQL 8:utf8mb4;
- 常用编码集:
- utf8mb3(utf8):1~3个字节来表示一个字符。(阉割过的 utf8mb4)
- utf8mb4:4个字节,来表示一个字符。(可存储表情符号)
- 查询当前 MySQL中,支持的字符集:
【 show charset; 】
【 show charset like '%utf8%'; 】
【 show character set like '%utf8%'; 】
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
+---------+---------------+--------------------+--------+
----------------------------------------------------------------------
【 select *
from information_schema.character_sets
where CHARACTER_SET_NAME like '%utf8%'; 】
+--------------------+----------------------+---------------+--------+
| CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | DESCRIPTION | MAXLEN |
+--------------------+----------------------+---------------+--------+
| utf8 | utf8_general_ci | UTF-8 Unicode | 3 |
| utf8mb4 | utf8mb4_general_ci | UTF-8 Unicode | 4 |
+--------------------+----------------------+---------------+--------+
- 查询当前 MySQL中,支持的比较规则:
【 show collation like '%utf8mb4_%'; 】
+--------------------------+---------+-----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------------+---------+-----+---------+----------+---------+
| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 |
+--------------------------+---------+-----+---------+----------+---------+
-- utf8_general_ci:是一种通用的比较规则。
-- _ci:不区分大小写
3:字符集和比较规则 的应用

(1)各级别的字符集和比较规则
- MySQL 有四个级别的 字符集和比较规则。分别是:
- 服务器级别。
- 数据库级别。
- 表级别。
- 列级别。
- 分别解释:
【 show variables like 'character_set_server'; 】
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| character_set_server | utf8mb4 |
+----------------------+---------+
1 row in set (0.00 sec)
----------------------------------------------------------------------
【 show variables like 'collation_server'; 】
+------------------+--------------------+
| Variable_name | Value |
+------------------+--------------------+
| collation_server | utf8mb4_general_ci |
+------------------+--------------------+
1 row in set (0.00 sec)
1、设置:
【 create database aa character set utf8mb4 collate utf8mb4_general_ci; 】
【 alter database aa character set utf8 collate utf8_general_ci; 】
----------------------------------------------------------------------
2、查询:
【 show variables like 'character_set_database'; 】
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| character_set_database | utf8 |
+------------------------+-------+
【 show variables like 'collation_database'; 】
+--------------------+-----------------+
| Variable_name | Value |
+--------------------+-----------------+
| collation_database | utf8_general_ci |
+--------------------+-----------------+
1、创建数据库时指定:
【 create table t1 (name varchar(20)) character set utf8mb4 collate utf8mb4_general_ci; 】
2、修改已创建数据库的字符集
【 alter table t1 character set utf8mb4 collate utf8mb4_general_ci; 】
【 alter table t1 convert to character set 'utf8'; 】
【 create table t2 (name varchar(10) character set utf8 collate utf8_general_ci); 】
【 alter table t2 modify name varchar(20) character set utf8 collate utf8_general_ci; 】
- 这4个级别的,字符集和比较规则的联系:
- 如果 创建或修改列 时没有显式的指定字符集和比较规则,则该列 默认用表的 字符集和比较规则;
- 如果 创建表时 没有显式的指定字符集和比较规则,则该表 默认用数据库的 字符集和比较规则;
- 如果 创建数据库时 没有显式的指定字符集和比较规则,则该数据库 默认用服务器的 字符集和比较规
则;
(2)客户端 和 服务器,通信过程中使用的字符集
- MySQL 通信协议:
- MySQL客户端 与 MySQL服务器,进行通信的过程中,事先规定好的数据格式,称为 MySQL 通信协议。
- 注意:
- 客户端在编码请求字符串时使用的字符集,与服务器在接收到一个字节序列后,认为该字节序列所采用的编码字符集,是两个独立的字符集。
- 我们应该尽量保证,这两个字字符集是一致的。
- 客户端发送请求:
-- (优先级:从高到低)
【 echo $lc_all 】
【 echo $LC_CTYPE 】
【 echo $LANG 】
zh_CN.UTF-8
-- zh_CN:表示语言以及国家地区。
-- UTF-8:表示操作系统当前使用的字符集是 UTF-8。
- 服务器接收请求:
【 show variables like 'character_set_%'; 】
++-----------------------+--------+
| Variable_name |Value |
++-----------------------+--------+
|character_set_client |utf8mb4 |
+------------------------+--------+
1、我们要告诉服务器,客户端 给 服务端 发送的数据是什么编码?
2、服务器认为,客户端请求数据的字符集,是按照,该系统变量指定的字符集,进行编码的。
所以也会用这个变量的值,来解析请求的字符序列(也就是:服务器解码请求时使用的字符集)。
3、每个客户端与服务端建立连接后,服务器都会为客户端维护一个 SESSION 级别的 变量。
|character_set_connection|utf8mb4 |
+------------------------+--------+
1、告诉字符集转换器,需要将“client” 接收到的客户端字节序列,转换成什么编码?
2、会把请求字节序列,将其从 client 转换为 "character_set_connection" 变量指定的字符集。
|character_set_database |utf8mb4 |
+------------------------+--------+
1、当前数据库默认的字符集。无论默认数据库如何改变,都是这个字符集;
2、如果当前没有 use数据库,那就使用 "character_set_server" 指定的字符集。
3、这个变量建议由系统自己管理,不要人为定义。
|character_set_filesystem|binary |
+------------------------+--------+
1、把os上文件名转化成此字符集,
2、即把 "client" 转换为 "character_set_filesystem"
3、默认binary,是不做任何转换的
|character_set_results |utf8mb4 |
+------------------------+--------+
1、服务器会采用,该系统变量指定的字符集。对返回客户端的字符串进行编码。
2、查询的结果用什么编码?(查询时,服务器会将字符串转换为该字符集编码后的字节序列,发送给客户端)
3、MySQL服务端把结果集和错误信息,转换为 "results" 指定的字符集,并发送给客户端。
|character_set_server |utf8mb4 |
+------------------------+--------+
1、服务器级别的字符集。
2、表示数据库服务器端,的默认字符集。
|character_set_system |utf8mb3 |
+------------------------+--------+
1、系统元数据(字段名等)字符集。这个值总是utf8,不需要设置。
2、这个字符集用于数据库对象(如表和列)的名字,
3、也用于存储在目录表中的函数的名字。
|character_sets_dir |/u01/mysql/share/charsets/|
+-----------------------+---------------------------+
-- 还有以collation_开头的同上面对应的变量,用来描述字符校对规则。
【 show variables like '%collation%'; 】
+-------------------------------+--------------------+
| Variable_name | Value |
+-------------------------------+--------------------+
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_0900_ai_ci | -- 表示服务器级别的比较规则
| default_collation_for_utf8mb4 | utf8mb4_0900_ai_ci |
+-------------------------------+--------------------+
- 查询当前数据库的校对规则( 字段说明同:character_set_% )
【 show variables like 'collation%'; 】
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
-- 当前连接的字符集。
| collation_connection | utf8_general_ci |
+----------------------+-------------------+
-- 当前日期的默认校对。
-- 每次用USE语句来“跳转”到另一个数据库的时候,这个变量的值就会改变。
-- 如果没有当前数据库,这个变量的值就是collation_server变量的值。
| collation_database | latin1_swedish_ci |
+----------------------+-------------------+
-- 服务器的默认校对。
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
(3)从发送请求,到接收响应的过程中,发生的字符集转换规则如下:
- 客户端发送的请求字符序列,是采用哪种字符集进行编码的。
- (取决于:客户端的操作系统使用的字符集)
- 服务器接收到请求字节序列后,会认为它是使用哪种字符集进行编码的。
- (取决于:character_set_client )
- 服务器在运行过程中,会把请求的字符序列,转换为以哪种字符集编码的字节序列。
- (取决于:character_set_connection )
- 服务器再向客户端返回字节序列时,是采用哪种字符集进行编码的。
- (取决于:character_set_results )
- 客户端在收到,响应字节序列后,是怎么把它们写到黑框框中的。
- 同第一步:(取决于:客户端的操作系统使用的字符集)


4:MySQL 中,如何设置字符集
(1)启动前,在配置文件中配置:( vim /etc/my.cnf )
- 配置 服务端字符集,然后需要重启服务器
- 注意:但是原库、原表的设定不会发生变化,参数修改只对新建的数据库生效。
[server]
# 默认字符集
character_set_server=utf8mb4
# 对应的默认的比较规则
collation_server=utf8mb4_general_ci

- 配置 客户端字符集:
(2)修改已有 数据库/表的字符集:
== 注意:原有数据可能需要导出和导入操作。
1、修改已创建数据库的字符集
【 alter database dbtest1 character set 'utf8'; 】
2、修改已创建数据表的字符集
【 alter table t emp convert to character set 'utf8'; 】
5:SQL 大小写规范
(1)说明:
- 在 SQL 中,关键字和函数名是不用区分字母大小写的:
- 比如 SELECT、WHERE、ORDER、GROUP BY 等关键字,
- 以及 ABS、MOD、ROUND、MAX 等函数名。
- 查看大小写是否敏感配置:
【 show variables like '%lower_case_table_names%'; 】
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| lower_case_table_names | 0 |
+------------------------+-------+
1 row in set (0.00 sec)
- 解释:
- 默认为0:大小写敏感 。
- 设置1:大小写不敏感。创建的表,数据库都是以小写形式存放在磁盘上,对于sql语句都是转换为小写对表和数据库进行查找。
- 设置2:创建的表和数据库,依据语句上格式存放,凡是查找都是转换为小写进行。
- MySQL在Linux下数据库名、表名、列名、别名大小写规则是这样的:
- 数据库名、表名、表的别名、变量名:是严格区分大小写的;
- 关键字、函数名称在 SQL 中:不区分大小写;
- 列名(或字段名)与 列的别名(或字段别名)在所有的情况下:均是忽略大小写的;
(2)如何配置:
- 当想设置为大小写不敏感时:(需重启 MySQL服务器)
[server]
lower_case_table_names=1
-- 不可以在 MySQL 运行中设置:
【 set global lower_case_table_names = 1; 】
ERROR 1238 (HY000): Variable 'lower_case_table_names' is a read only variable
- 注意:
- 此参数适用于 MySQL5.7;
- MySQL 8 禁止在重新启动 MySQL 服务时,将变量修改为不同于初始化 MySQL 服务时设置的 "lower_case_table_names" 值;(设置后重启 MySQL 服务会报错)
6:sql_mode 的合理设置
(1)宽松模式 vs 严格模式:
- 宽松模式:

- 严格模式:

(2)宽松模式再举例:
(3)模式查看和设置:
- 查看当前的 sql_mode:
【 select @@session.sql_mode; 】
【 select @@global.sql_mode; 】
【 show variables like '%sql_mode%'; 】
+----------------------------------------------+
| @@session.sql_mode |
+----------------------------------------------+
| ONLY_FULL_GROUP_BY,
| STRICT_TRANS_TABLES,
| NO_ZERO_IN_DATE,
| NO_ZERO_DATE,
| ERROR_FOR_DIVISION_BY_ZERO,
| NO_ENGINE_SUBSTITUTION
+----------------------------------------------+
1 row in set (0.00 sec)
- 临时设置方式:
-- 全局
【 SET GLOBAL sql_mode = 'modes...'; 】
-- 当前会话
【 SET SESSION sql_mode = 'modes...'; 】
-- 改为严格模式。此方法只在当前会话中生效,关闭当前会话就不生效了。
set SESSION sql_mode='STRICT_TRANS_TABLES';
-- 改为严格模式。此方法在当前服务中生效,重启MySQL服务后失效。
set GLOBAL sql_mode='STRICT_TRANS_TABLES';
- 永久设置方式:(在 /etc/my.cnf 中配置 sql_mode)(然后重启)
[mysqld]
sql_mode=ONLY_FULL_GROUP_BY,
STRICT_TRANS_TABLES,
NO_ZERO_IN_DATE,
NO_ZERO_DATE,
ERROR_FOR_DIVISION_BY_ZERO,
NO_ENGINE_SUBSTITUTION
- 当然生产环境上是禁止重启MySQL服务的,所以采用 临时设置方式 + 永久设置方式 来解决线上的问题,那么即便是有一天真的重启了MySQL服务,也会永久生效了。