本篇是PolarDB 优化器查询变换系列的第四篇,之前的文章请见:
窗口函数解相关:https://ata.alibaba-inc.com/articles/194578
IN-list变换:https://ata.alibaba-inc.com/articles/254779
Join消除:https://ata.alibaba-inc.com/articles/252403
引言
在数据库的查询优化特性中,基于关系代数的等价变换一直是一个比较有挑战但又收益较高的方向,也就是我们常说的查询变换。很多变换可以在严格验证不存在性能回退的情况下做到启发式的应用(无脑变换),从而对性能产生巨大提升,一般是1~2个数量级。如上文章列举的join消除,就是这么一个启发式应用的例子。
而利用MySQL8.0的窗口函数对相关子查询做展开,在满足特定前提条件下,也可以实现无回退的性能收益,具体可以详见上面第1篇文章。基于window function的解相关让PolarDB TPC-H Q2/Q17的性能提升了很多倍。
但这里其实还有更优的解法:
之前SQL团队资深的优化器架构师Oystein在对Q17的分析中,提到了一种基于Lateral derived table的变换方案,可以做到更稳定的性能表现和更高的加速比:
SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM lineitem
JOIN part ON p_partkey = l_partkey
WHERE p_brand = 'Brand#34'
AND p_container = 'MED BOX'
AND l_quantity < (
SELECT 0.2 * AVG(l_quantity)
FROM lineitem
WHERE l_partkey = p_partkey
);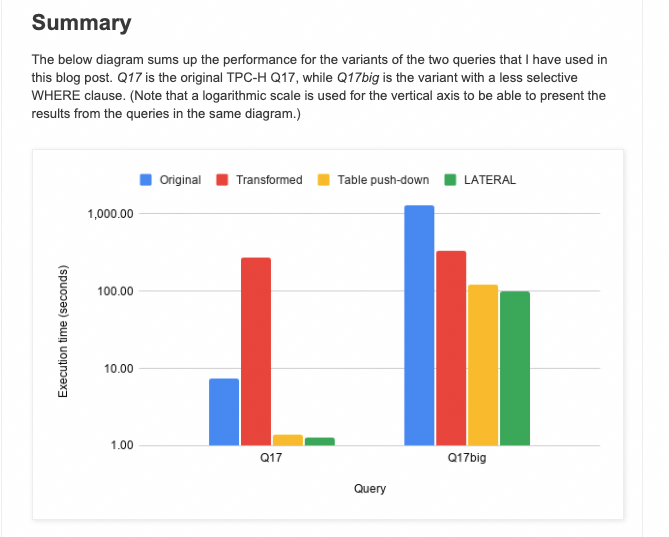
上图中Q17big是修改了外层查询中对于part表的选择率,而Table push-down是一个类似窗口函数的方案。可以看到这里LATERAL的性能在两种情况下都是最优的,那么这个LATERAL的变换是什么样的呢?
SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM lineitem
JOIN part ON p_partkey = l_partkey
JOIN LATERAL((
SELECT 0.2 * AVG(l_quantity)
FROM lineitem
WHERE l_partkey = p_partkey
)) AS ldt (avg_qty)
WHERE p_brand = 'Brand#34'
AND p_container = 'MED BOX'
AND l_quantity < avg_qty;这里产生了一个JOIN LATERAL,和一个带有相关性的derived table ldt,对应的执行计划:

可能从原始的Q17一下跳转到这样一个计划有些不好理解,我们分步来看下:

-
基于原始的相关子查询,第一步是转换为一个带有group by条件的derived table: pq(avg_qty, pk),再与外层的part表/lineitem表做join,由于相关条件作为group by列,因此对外层的每一行数据,derived table只会有对应分组的数据参与join和过滤计算,保证了和原来相关子查询结果的一致性。但这里有一个问题:
pq这张derived table,需要对lineitem表做全表扫描,然后完成聚集计算并一次性物化
考虑到lineitem是TPC-H中最大数据量的表,这种解相关的方式不一定会保证性能可以更优,这个变换PolarDB已经实现,但默认并不是开启的。
-
第二步将pq.pk = l_partkey这个join条件,进一步下推到pq这个derived table中,就变成了前面给出的lateral derived table的形式,相当于在左侧变换的基础上,下推了join条件,这产生了3方面的变化:
-
内层增加了过滤条件 l_partkey=p_partkey,可能可以使用索引,过滤掉lineitem的大量数据
-
由于下推条件覆盖group by的所有字段,每次对外层一行数据,内层总是针对特定分组的数据做计算,group by已经不再需要,可以消除
-
ldt表是要反复物化的,但如果它所依赖的part表数据量相对很少,则即使反复物化也比一次全量物化的成本更低
基于上面这3方面的因素,这种变换带来了很大的性能提升,比window function的变换要更大,但也能看到,这里有很多不确定的因素,也就是说这并不是一个启发式的无脑变换,需要基于代价决定。
由于实现的复杂度也较高,一开始并不在短期的研发计划中。但后来在线上的客户中遇到了实际的问题:
SELECT *
FROM (
SELECT *
FROM db_order.tb_order
WHERE create_date >= DATE_SUB(CAST('xxxx' AS datetime), INTERVAL 5 MINUTE)
AND product_type IN (?, ?)
) o
LEFT JOIN (
...
) od
ON o.order_id = od.order_id
LEFT JOIN (
SELECT t.*, row_number() OVER (PARTITION BY detail_id ORDER BY update_date DESC) AS rn
FROM db_order.tb_order_sku t
WHERE update_date >= DATE_SUB('xxxx', INTERVAL 50 MINUTE)
AND coalesce(product_type, 'xx') <> '?'
) os
ON od.id = os.detail_id
...查询做了大量简化和模糊,但总体问题就是,对于os这个derived table,由于内层表tb_order_sku的数据量很大而且没有合适的索引,需要做大量的聚集计算和物化大量数据,通过反复尝试优化,给出了这样的手动改写:
SELECT *
FROM (
...
) o
LEFT JOIN (
...
) od
ON o.order_id = od.order_id
LEFT JOIN LATERAL((
SELECT t.*, row_number() OVER (PARTITION BY detail_id ORDER BY update_date DESC) AS rn
FROM db_order.tb_order_sku t
WHERE update_date >= DATE_SUB('2022-12-05 15:12:05', INTERVAL 50 MINUTE)
AND coalesce(product_type, '0') <> '5'
AND od.id = detail_id
)) os;可以看到将join条件下推了进去,变成了lateral join,性能从60s+提升到0.5s。
正是由于线上客户的实际需求,推动我们实现了这个基于代价的join条件下推变换。
Join Predicate Pushdown
最早看到这个优化功能,是在Oracle著名的CBQT paper中,关于这篇文章的解读知乎有很多,笔者也写过一篇:
里面的一个章节介绍了这个优化: Join Predicate PushDown(JPPD),虽然篇幅不多,但还是非常准确的切中了变换的核心:
适用条件
在查询中存在derived table和外层表的join,并且采用了nested loop join的方式,此外在join列在derived table的内层,有适当的索引可以使用来加速对内层表的物化计算,并且有准确的统计信息支撑,确保下推后可以在内层过滤大量的数据。
为什么需要是nested loop join,因为对外层的每一行数据,都需要能触发内层表的重新物化,这个过程发生在外层读取每一行数据时,但如果是hash join,不仅要反复物化还要反复构建hash table,从iterator的迭代模型上触发模式也不合理(破坏了一侧先build,另一侧再probe的流程)。
收益条件
在满足适用条件的前提下,我们记外层表的数据量为N,内层的原数据量是M,内层基于join条件下推后的数据量是m,那大致的计算公式如下:
下推前:
N * Lookup_cost(M) + Mat_cost(M)
下推后:
N * (Lookup_cost(m) + Mat_cost(m))
下推前 > 下推后,即可保证可以产生更优的执行计划。
实现方案
很明显,这是一个需要基于代价决策的变换。虽然实现有些复杂,但思路还是比较朴素的:
-
在先进行的derived table内层优化的过程中:
-
完成内层derived table的join ordering优化,获取非下推情况下的全量物化代价
-
判断是否适合做JPPD,如果适合则打上标记,并收集这种潜在的candidate
-
返回到外层优化过程中,基于与该candidate derived table的join条件,构建相关的优化结构,并 传递 到derived table的内层,构建内部针对下推join条件的相关优化结构
-
外层开始join ordering枚举时,对于潜在下推的derived table, 保留 其原有的join plan,基于新构建的下推条件优化结构, 重新做join ordering优化 ,看是否可以选中下推条件所对应的索引,如果选中说明内层产生了适合的候选计划,没有选中则 恢复 原有的join plan
-
如果选中,调整derived table在外层的输出行数 + 物化代价,继续参与到外层的枚举过程中
-
最终外层选中的最优join计划中,如果对于derived table就是选择了下推后的新plan,说明新的优化策略基于代价被选中
-
在外层构建物理执行结构时,也将条件推入derived table内层并构建相关执行结构,建立依赖关系,消除不必要的group by条件等
用流程图描述和一个例子可能更清晰些:

可以看到,这里会在外层做join ordering的过程中,反复枚举内层可能的新join plan,如果内层查询比较大这个开销也是不可接受的,因此对内层计划也需要一个caching机制,在于外层可能的关联表和关联索引的情况下,最优计划被保留下来,后续如果还是同样的依赖关系,虽然所处的外层join顺序变化了(枚举过程中),内层计划还是可以复用的。
同时如果内层的group by列,完全可以被下推的join条件所覆盖,那就可以保证对外层每一行,内层选中的数据都是同一个分组的数据,group by就可以消除掉了,避免不必要的分组计算(但前提要有聚集函数,否则group by带来的去重效果就没有了,导致不正确的结果)
实际效果
我们仍以TPC-H Q17来看,使用10s的数据量串行执行,原始查询
EXPLAIN
SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM lineitem
JOIN part ON p_partkey = l_partkey
WHERE p_brand = 'Brand#34'
AND p_container = 'MED BOX'
AND l_quantity < (
SELECT 0.2 * AVG(l_quantity)
FROM lineitem
WHERE l_partkey = p_partkey
);执行计划是:
| -> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join (cost=779599.70 rows=511050)
-> Filter: ((part.P_CONTAINER = 'MED BOX') and (part.P_BRAND = 'Brand#34')) (cost=217445.20 rows=19743)
-> Table scan on part (cost=217445.20 rows=1974262)
-> Filter: (lineitem.L_QUANTITY < (select #2)) (cost=25.89 rows=26)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=25.89 rows=26)
-> Select #2 (subquery in condition; dependent)
-> Aggregate: avg(lineitem.L_QUANTITY)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=28.47 rows=26)可以看到,针对外层lineitem的每行数据,内层都要执行一遍,虽然使用了LINEITEM_FK2这个索引,但执行方式是固化的。
执行时间 3.49s
如果单独开启针对标量子查询转为derived table的变化,计划为
| -> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join
-> Nested loop inner join (cost=722658.72 rows=511050)
-> Filter: ((part.P_CONTAINER = 'MED BOX') and (part.P_BRAND = 'Brand#34')) (cost=202430.95 rows=19743)
-> Table scan on part (cost=202430.95 rows=1974262)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=23.76 rows=26)
-> Filter: (lineitem.L_QUANTITY < derived_1_2.Name_exp_1)
-> Index lookup on derived_1_2 using <auto_key2> (Name_exp_2=part.P_PARTKEY)
-> Materialize
-> Group aggregate: avg(lineitem.L_QUANTITY)
-> Index scan on lineitem using LINEITEM_FK2 (cost=5896444.53 rows=54300917)可以看到,子查询做了全量物化后,与外层查询进行join,join顺序是part -> lineitem -> dt
执行时间太长中间就kill了。
但如果加入JPPD的优化,就可以生成如文章开头所产生的最优计划:
| -> Aggregate: sum(lineitem.L_EXTENDEDPRICE)
-> Nested loop inner join
-> Nested loop inner join
-> Invalidate materialized tables (row from part) (cost=202430.95 rows=19743)
-> Filter: ((part.P_CONTAINER = 'MED BOX') and (part.P_BRAND = 'Brand#34')) (cost=202430.95 rows=19743)
-> Table scan on part (cost=202430.95 rows=1974262)
-> Index lookup on derived_1_2 using <auto_key2> (Name_exp_2=part.P_PARTKEY)
-> Materialize (invalidate on row from part)
-> Group aggregate: avg(lineitem.L_QUANTITY)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=9.06 rows=26)
-> Filter: (lineitem.L_QUANTITY < derived_1_2.Name_exp_1) (cost=6.47 rows=9)
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=part.P_PARTKEY) (cost=6.47 rows=26)可以看到L_PARTKEY=part.P_PARTKEY这个外层join条件被下推了,和part表先做lateral join,最后与lineitem join,与预期一致。
执行时间 1.05s
而线上客户的案例更是从60+s ,缩减到了0.5s,可以说效果非常明显。
总结
针对上面给出的TPC-H Q17,大家可能有一个疑问,既然这个转换并不一定是更优的,虽然结合JPPD可以产生最优计划,但却无法默认把它打开,这不是矛盾么?确实如此,这也是我们在做的另外一个更为重要的工作:Cost-based query transformation所要解决的问题。
CBQT的核心是要建立一个枚举框架,在这个框架中,各种变换规则可以不用固化的加入到codebase中,而是基于基于代价决定每个变换是否完成,并考虑变换之间的关联性,使某些变换可以相互应用、反复应用,同时在过程中最小化重复优化所带来的额外开销(统计信息的重新估计、query block的重新优化等),在时间+空间与计划最优性之间取得一个合理的tradeoff。
最后不得不感叹一下,优化器的开发工作是一个持续积累的过程,虽然各个特性看起来是case by case,但逐渐积累就会最终产生质变。而我们能做的就是在客户需求的导向下,针对每一个功能特性深入挖掘,尽可能适用更多的场景,产生尽量优的效果。
