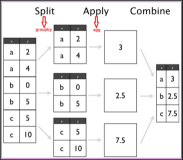
数据分析本质上就是用数据寻找问题的答案。当我们对一组数据执行某种计算或计算统计信息时,通常对整个数据集进行统计是不够的。取而代之的是,我们通常希望将数据分成几组,并执行相应计算,然后比较不同组之间的结果。
假设我们是一个数字营销团队,正在调查最近转换率下降的潜在原因。从整体来看转化率并不能让我们找到可能的原因。我们希望比较不同营销渠道,广告系列,品牌和时间段之间的转化率,以识别指标的差异。
Pandas是非常流行的python数据分析库,它有一个GroupBy函数,提供了一种高效的方法来执行此类数据分析。在本文中,我将简要介绍GroupBy函数,并提供这个工具的核心特性的代码示例。
数据
在整个教程中,我将使用在openml.org网站上称为“ credit-g”的数据集。该数据集由提出贷款申请的客户的许多功能和一个目标变量组成,该目标变量指示信贷是否还清。
可以在此处下载数据(https://www.openml.org/d/31),也可以使用Scikit-learn API导入数据,如下所示。
importpandasaspdimportnumpyasnpfromsklearn.datasetsimportfetch_openmlX,y=fetch_openml(name='credit-g', as_frame=True, return_X_y=True) df=Xdf['target'] =ydf.head()
基本用法
此函数最基本的用法是将GroupBy添加到整个dataframe并指定我们要进行的计算。这将生成所有变量的摘要,这些变量按您选择的段分组。这是快速且有用方法。
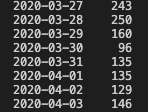
在下面的代码中,我将所有内容按工作类型分组并计算了所有数值变量的平均值。输出显示在代码下方。
df.groupby(['job']).mean()

如果我们想要更具体一些,我们可以取dataframe的一个子集,只计算特定列的统计信息。在下面的代码中,我只选择credit_amount。
data[['job', 'credit_amount']].groupby(['job']).mean()

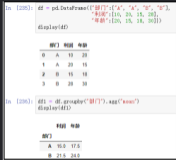
我们也可以按多个变量分组。这里我按工作和住房类型计算了平均信贷金额。
data[['job', 'housing','credit_amount']].groupby(['job', 'housing']).mean()

多聚合
groupby后面使用agg函数能够计算变量的多个聚合。
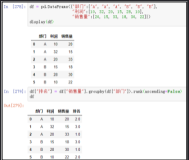
在下面的代码中,我计算了每个作业组的最小和最大值。
data[['job', 'credit_amount']].groupby(['job']).agg([min, max])

也可以对不同的列使用不同的聚合。在这里,我计算了credit_amount的最小和最大金额以及每种工作类型的平均年龄。
df[['job', 'credit_amount', 'age']].groupby(['job']).agg( {'credit_amount': ['min', 'max'], 'age': 'mean'})

聚合命名
NamedAgg函数允许为多个聚合提供名称,从而提供更清晰的输出。
df[['target', 'credit_amount', 'age']].groupby('target').agg( min_credit_amount=pd.NamedAgg('credit_amount', 'min'), max_credit_amount=pd.NamedAgg('credit_amount', 'max'), average_age=pd.NamedAgg('age', 'mean'))

自定义聚合
也可以将自定义功能应用于groupby对聚合进行自定义的扩展。
例如,如果我们要计算每种工作类型的不良贷款的百分比,我们可以使用下面的代码。
job_count=df[['job', 'target']].groupby(['job', 'target']).agg({'target': 'count'}) job_percent=job_count.groupby(level=0).apply(lambdax: 100*x/float(x.sum())) job_percent

可视化绘图
我们可以将pandas 内置的绘图功能添加到GroupBy,以更好地可视化趋势和模式。
我扩展了我在上一节中创建的代码,以创建堆叠的条形图,以更好地可视化每种工作类型的好坏贷款的分布。
df.groupby(['job', 'target'])['job'].count().unstack('target').fillna(0).plot(kind='bar', stacked=True)

除了使用GroupBy在同一图表中创建比较之外,我们还可以在多个图表中创建比较。
df[['duration', 'target']].groupby('target').boxplot()

总结
pandas GroupBy函数是一个工具,作为数据科学家,我几乎每天都会使用它来进行探索性数据分析。本文是该功能基本用法的简短教程,但是可以使用许多更强大的方法来分析数据。
如果你需要本篇文章完整代码,可以在这里找到:https://github.com/rebecca-vickery/machine-learning-tutorials/blob/master/data-analysis/pandas_grouby.ipynb