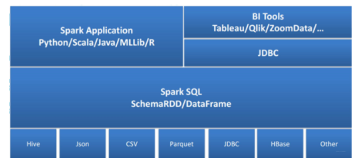
产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
备案
控制台
开发者社区
首页
探索云世界
探索云世界
云上快速入门,热门云上应用快速查找
了解更多
问产品
动手实践
官方博客
考认证
TIANCHI大赛
活动广场
活动广场
丰富的线上&线下活动,深入探索云世界
任务中心
做任务,得社区积分和周边
高校计划
让每位学生受益于普惠算力
训练营
资深技术专家手把手带教
话题
畅聊无限,分享你的技术见解
开发者评测
最真实的开发者用云体验
乘风者计划
让创作激发创新
阿里云MVP
遇见技术追梦人
直播
技术交流,直击现场
下载
下载
海量开发者使用工具、手册,免费下载
镜像站
极速、全面、稳定、安全的开源镜像
技术资料
开发手册、白皮书、案例集等实战精华
插件
为开发者定制的Chrome浏览器插件
探索云世界
新手上云
云上应用构建
云上数据管理
云上探索人工智能
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
热门
百炼大模型
Modelscope模型即服务
弹性计算
云原生
数据库
云效DevOps
龙蜥操作系统
平头哥
钉钉开放平台
物联网
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
支持服务
镜像站
码上公益
开发者社区
大数据
文章
正文
《Comparison of Spark SQL with Hive》电子版地址
2022-12-17
45
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议
》和 《
阿里云开发者社区知识产权保护指引
》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单
进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
Comparison of Spark SQL with Hive
《Comparison of Spark SQL with Hive》Comparison of Spark SQL with Hive
电子版下载地址:
https://developer.aliyun.com/ebook/1173
电子书:
</div>
文章标签:
分布式计算
SQL
Spark
HIVE
auqbllxiu
目录
相关文章
thinktothings
|
SQL
缓存
分布式计算
Spark 2.4.0编程指南--Spark SQL UDF和UDAF
## 技能标签 - 了解UDF 用户定义函数(User-defined functions, UDFs) - 了解UDAF (user-defined aggregate function), 用户定义的聚合函数 - UDF示例(统计行数据字符长度) - UDF示例(统计行数据字符转大写) ...
thinktothings
7071
0
0
javaedge
|
SQL
存储
分布式计算
Spark SQL实战(08)-整合Hive
Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。
javaedge
143
0
0
auqbllxiu
|
SQL
分布式计算
Spark
《Spark SQL:Another 16x faster after Tungsten》电子版地址
Spark SQL:Another 16x faster after Tungsten
auqbllxiu
56
0
0
auqbllxiu
|
SQL
分布式计算
Spark
《GeoMesa on Spark SQL》电子版地址
GeoMesa on Spark SQL
auqbllxiu
94
0
0
云祁
|
SQL
分布式计算
HIVE
【Spark】(八)Spark SQL 应用解析2
【Spark】(八)Spark SQL 应用解析2
云祁
181
0
0
云祁
|
SQL
分布式计算
关系型数据库
【Spark】(八)Spark SQL 应用解析1
【Spark】(八)Spark SQL 应用解析1
云祁
112
0
0
托马斯-酷涛
|
SQL
HIVE
九十四、Spark-SparkSQL(整合Hive)
九十四、Spark-SparkSQL(整合Hive)
托马斯-酷涛
173
0
0
游客wkxim4agoo6le
|
SQL
分布式计算
关系型数据库
Spark SQL 与Hive集成
笔记
游客wkxim4agoo6le
811
0
0
从大数据到人工智能
|
SQL
分布式计算
数据管理
spark SQL配置连接Hive Metastore 3.1.2
Hive Metastore作为元数据管理中心,支持多种计算引擎的读取操作,例如Flink、Presto、Spark等。本文讲述通过spark SQL配置连接Hive Metastore,并以3.1.2版本为例。
从大数据到人工智能
930
1
1
学堂小助手
|
SQL
缓存
分布式计算
Apache Hive--join 操作| 学习笔记
快速学习 Apache Hive--join 操作
学堂小助手
83
0
0
热门文章
最新文章
1
微服务(Microservice)那点事
2
Hadoop数据迁移MaxCompute最佳实践
3
(十) Spring Cloud构建分布式微服务架构 - SSO单点登录之OAuth2.0登录认证(1)
4
进程管理
5
文件或目录的权限与属性
6
How to safely shut down a loading UIWebView in viewWillDisappear?
7
谷歌 Project Zero 公布 Windows 10 漏洞
8
一个好用的短连接服务,mark备用
9
自动更新Chromium
10
一篇值得思考的职业教育之路!
1
算法金 | K-均值、层次、DBSCAN聚类方法解析
22
2
m基于深度学习的卫星遥感图像轮船检测系统matlab仿真,带GUI操作界面
20
3
ELK与Fluentd的结合
26
4
基于GA遗传优化的混合发电系统优化配置算法matlab仿真
29
5
【题解】—— LeetCode一周小结25
31
6
《手把手教你》系列基础篇(八十一)-java+ selenium自动化测试-框架设计基础-TestNG如何暂停执行一些case(详解教程)
30
7
基于布谷鸟搜索的多目标优化matlab仿真
25
8
JavaScript小数四舍五入的代码
21
9
MaxCompute产品使用问题之整库实时需要申请什么东西
19
10
MaxCompute产品使用问题之创建了oss外表,格式指定的parquet,然后执行的写入,发现不是标准parquet的格式,该怎么办
24
相关课程
更多
SQL进阶及查询
SQL入门与实践
数据库及SQL/MySQL基础
SQL调优与架构优化
SQL Server on Linux入门教程
如何在 PolarDB-X 中优化慢 SQL
相关电子书
更多
Comparison of Spark SQL with Hive
Ali-HBase的SQL实践与改进
Spark SQL最佳实践
相关实验场景
更多
PolarDB for AI:在数据库中通过SQL实现AI能力
玩转MaxCompute SQL! 30分钟搞定数据分析挖掘
SQL进阶之约束、索引
SQL进阶之子句、关键字和操作符
RDS MySQL的SQL问题诊断与调优
SQL的增删改查及函数应用
下一篇
部署LAMP环境(Alibaba Cloud Linux 3)