@[toc]
Hadoop运行环境搭建(开发重点)
1.2克隆虚拟机
1.2.1背景
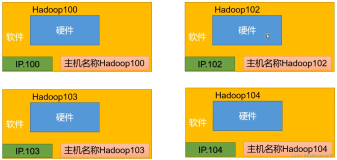
为什么不从hadoop101开始,因为一开始hadoop101留给了单台服务器操作使用,而用102,103,104搭建的是完全分布式,真正的生产集群。后面可以用101进行源码的编译

1.2.2利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
注意:克隆时,要先关闭hadoop100
关机的时候右键->电源->关闭客户机

右键->管理->克隆





然后103和104一样的操作
1.2.3如果不小心将虚拟机hadoop100移除了


这样是不会从根目录删除的
文件夹里还有hadoop100
1.2.4如何再将hadoop100添加回来

在左边右键点打开
找到你当时安装的路径,然后点这个文件打开,就可以了

1.2.5如何将hadoop104从磁盘删除

右键->管理->从磁盘中删除就可以了
1.2.6修改克隆机IP,以下以hadoop102举例说明
1.2.6.1修改ip
- [root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE="ens33"
ONBOOT="yes"
IP地址
IPADDR=192.168.159.100
网关
GATEWAY=192.168.159.2
域名解析器
DNS1=192.168.159.2
将IPADDR=192.168.159.100这里的100改成102即可
DEVICE="ens33"
ONBOOT="yes"
IP地址
IPADDR=192.168.159.102
网关
GATEWAY=192.168.159.2
域名解析器
DNS1=192.168.159.2
1.2.6.2修改主机名称
- [root@hadoop100 ~]# vim /etc/hostname

1.2.6.3配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
- [root@hadoop100 ~]# vim /etc/hosts
192.168.159.100 hadoop100
192.168.159.101 hadoop101
192.168.159.102 hadoop102
192.168.159.103 hadoop103
192.168.159.104 hadoop104
1.2.6.4网络配置
因为是克隆的hadoop100,之前将hadoop100配置好了,所以这个就不需要再弄了,如果没有弄过的,需要弄一下这个
对安装好的VMware进行网络配置,方便虚拟机连接网络,本次设置建议选择NAT模式,需要宿主机的Windows和虚拟机的Linux能够进行网络连接,同时虚拟机的Linux可以通过宿主机的Windows进入互联网。
1.2.6.4.1编辑VMware的网络配置


选择VMnet8,然后再点击更改设置


这个修改完成点确定

再次点确定
1.2.6.4.2Windows的网络配置
以下以Window11为例

点击这个

然后搜索网络连接



按如上格式修改IP信息(地址,网关,DNS服务器),修改完毕后全部点击确定退出
1.2.6.4.3修改windows的主机映射文件(hosts文件)
操作系统是window10/11,先拷贝出来,修改保存以后,再覆盖即可
进入C:\Windows\System32\drivers\etc路径
拷贝hosts文件到桌面
打开桌面hosts文件并添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
hadoop103和hadoop104也是一样操作,就不再一一展示了
1.2.6.5检查是否成功
[root@hadoop102 ~]# ifconfig

看看这里是不是改成102了,其余的103和104也是这样检查的
- [root@hadoop102 ~]# hostname

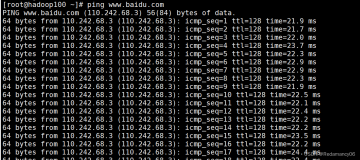
ping一下外网看看能ping上不能
- [root@hadoop102 ~]# ping www.baidu.com

1.3在XShell和Xftp连接hadoop102、hadoop103和hadoop104
看我之前的博客,和hadoop100是一样的,只需要将名字改一改就可以了
远程终端工具Xshell、Xftp传输工具的下载、安装和使用教程http://t.csdn.cn/RdqS2