令人无语的八阿哥_个人页

文章
0
问答
711
视频
0
个人介绍
暂无个人介绍
擅长的技术

暂无更多信息
暂无更多信息
暂无更多信息
-
 回答了问题
2021-11-26
回答了问题
2021-11-26
阿里云虚拟化技术发展历程是怎样的?
虚拟化技术是云计算的重要技术之一,在被云计算采用之后就不断演进发展。虚拟化技术在阿里云的历史正好是这个演进发展过程的一个缩影,如下图所示:

1)Xen 虚拟化架构(2009—2015 年)
2009 年,在阿里云刚成立之时,在开源虚拟化技术领域中,Xen 已经是比较成熟的虚拟机监控器项目,所以阿里云采用开源的 Xen 作为第一个虚拟化底层架构。当时,阿里云将 Xen 开源项目应用在公共云上,做了一些修改,解决了 Xen 在公共云应用中的大规模工程化方面的各种细节问题。在这个时期,亚马逊 AWS 的虚拟化架构使用的也是 Xen,这种选择也是当时业界的共识。
2)KVM 虚拟化架构(2015—2018 年)
2005 年、2006 年,Intel 和 AMD 的 x86 CPU 硬件分别开始支持硬件虚拟化 (VT)技术,并在 2006 年诞生了 KVM 这个基于硬件虚拟化的开源虚拟化项目。红帽(RedHat)公司在 2008 年收购了开发 KVM 的以色列公司 Qumranet 后,KVM 更是得到了大力的发展。2014 年左右,KVM 在功能完备性、稳定性、 社区支持等各个方面都超过了 Xen,这时阿里云也开始研发基于 KVM 的云服务器,最终在 2015 年将虚拟化架构迁移到了 KVM 上。在 2015—2018 年,阿里云不仅使用 KVM 解决了工程化58 的问题,也做了 QEMU/KVM 的热升级等原创工作,自研了 vCPU 的调度器,支持性能突发型实例规格(T5)的产品,同时对热迁移等重要功能做了比较好的优化。
3)软硬件结合的虚拟化架构(2018 年至今)
在 KVM 虚拟化技术比较成熟的情况下,在下一代的虚拟化架构演进方向上,包 括亚马逊 AWS、阿里云等云服务提供商仿佛达成默契,都在软硬件结合的方向上投入研发。AWS 在 2017 年年底对外发布了基于 Nitro 架构的 C5 实例规格,阿里云在 2017 年也发布了基于神龙架构的弹性裸金属服务器,并在 2018 年上线了基于神龙架构的虚拟机云服务器。神龙架构是阿里云自研的软硬件结合的虚拟化平台,其中的 MOC 卡是神龙架构中的核心硬件,将存储、网络、管控的链路全部转移到 MOC 上, 同时对 KVM 虚拟化技术做进一步优化,以提升计算性能。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
阿里云的虚拟机云服务器提供了哪些解决方案?
阿里云的虚拟机云服务器既可以作为 Web 服务器或者应用服务器单独使用,又可以与其他服务器一起工作,提供更丰富的解决方案,举例如下。
**企业官网或轻量的 Web 应用 **
当网站初始阶段访问量小时,一台低配置的入门级ECS T 规格族虚拟机即可运行 Apache 或 Nginx 等 Web 应用程序、数据库,以及存储文件。
**访问量波动剧烈的应用或网站 **
某些应用(如抢红包应用、优惠券发放应用)、电商网站和票务网站等的访问量可能会在短时间内产生巨大的波动。在这些场景中,独享型的C 规格族或者G 规格族虚拟机,配合负载均衡 SLB 和弹性伸缩,可自动化实现在访问量高峰来临前增加 ECS 实例,在进入访问量低谷时减少 ECS 实例,满足了访问量达到峰值时对资源的需求,同时能降低成本,并提升应用的可用性。
多媒体应用或网站
搭配使用独享型的虚拟机与对象存储 OSS,OSS 承载静态图片、视频或者下载包,进而降低存储费用,同时配合内容分发网络 CDN 和负载均衡 SLB,可大幅减少用户访问等待时间、降低网络带宽费用和提高可用性。
高并发游戏服务器
很多华丽精彩的大型在线游戏需要在服务端进行大量密集的计算,此时可以使用高主频型的HFC 或HFG 规格族虚拟机。它们配备了高主频的CPU,能为游戏引擎提供强大的计算力。
高 I/O 要求数据库
为支持承载高 I/O 要求数据库,如 OLTP 类型数据库和 NoSQL 类型数据库,可以使用较高配置的G 规格族或者R 规格族虚拟机,并配合高性能的 ESSD 云盘,或者使用带本地SSD 盘的I 规格族虚拟机,实现高 I/O 并发响应。云盘有更好的可靠性和灵活性,本地盘则有更低的时延,两个方案各有优劣。
大数据实时在线或离线分析
对于 Hadoop 分布式计算、日志处理和大型数据仓库等业务场景,可以使用大数据D 规格族虚拟机。它采用了本地HDD 硬盘,可以提供海量的存储空间和优异的存储性能。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
高性能计算的功能特点是什么?
高性能计算聚焦于解决大规模科学和工程问题,如科学计算、气象预报、计算模拟、石油勘探、CFD/CAE、生物制药、基因测序、影视渲染等,主要目的是通过并行计算提高运算速度,在可接受的时间和精度范围内,对复杂问题求解,因此对高性能计算系统的浮点算力、内存带宽、并行密度、互连带宽和延迟、并行 I/O、存储等方面都有十分高的要求,其中的每一个环节都将直接影响系统的运算速度。当前的高性能计算体系结构= 节点+ 系统互联,其中,节点是计算机系统内相对独立的子系统,具备一台计算机的完整功能,在云上就是一台云服务器;系统互联即指多个相对独立的节点通过一定拓扑采用典型的MPI(+OpenMP)模式高速互联。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
高性能计算是什么?
高性能计算(High Performance Computing,HPC)是计算技术发展最快的领域。 因为现代计算机最早的任务是为战场计算炮弹的弹道,所以,高性能计算都有共性, 即先在足够强大的计算机上仿真和建模、并行化、离散方程求解,再输出为人或机器可以理解和应用的结果。高性能计算由于面对的求解任务的强度大,复杂度和精度高,所以从早期的向量机、小型机到现代基于通用服务器的高性能计算集群,都采取了并行处理的编程模式。高性能计算因而又被称为并行计算(Parallel Computing), 和互联网上的分布计算(Distributed Computing)有一定的区别。
高性能计算体系结构的发展史其实是一部计算机技术的发展史。从19 世纪60 年代以前的ENIAC,到19 世纪70 年代的向量机Cray-1,又到19 世纪80 年代的并行机TMC CM2 大规模并行MPP,再到19 世纪90 年代的Intel ASCI 多处理器集群,直至21 世纪,集群就是HPC,GPU 异构集群大行其道。中国从天河2 号、太湖之光先后进入世界TOP500 到研制E 级超算,可以看到,基于集群和异构处理器的超算发展依然是领跑摩尔定律的、发展最快的计算机领域。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
AI加速器的分布式通信优化方法是怎样的?
(1)计算和通信的重叠。传统的计算和通信是串行的,即先做完梯度计算、再做梯度通信,我们的第一个优化工作是将计算和通信重叠起来,尽量减少通信的开销。
(2)去中心化梯度协商。传统分布式梯度协商方式是根节点和所有节点都协商, 因此根节点的负担会随着节点数增加而大幅升高。而我们采取的去中心化的梯度协商方式,将大规模下梯度协商的复杂度降低了一个数量级。
(3)梯度压缩。将要传输的梯度从FP32 压缩到FP16,并建立了相应的数据缩放机制,从而防止精度损失。
(4)分级通信优化。传统的环形通信方式是将所有节点上的GPU 形成一个大环, 致使其整体性能在以太网的通信上受到限制。我们做了分级通信的优化,首先在节点内部的GPU 上做一级规约通信,每个节点都规约到一块GPU 上,然后每个节点的这个GPU 再做二级规约通信。这样一方面减少了以太网上传输的数据量,另一方面通过流水线将节点内部的规约通信和节点之间的规约通信重叠起来,减少了整体通信时间。
(5)梯度融合优化。传统的通信方法是计算出一个梯度通信一次,这样会产生很多小包的通信,对网络带宽非常不友好,优化是等一批梯度计算完成后再融合在一起做通信,这样的大数据包能够大大提升网络带宽的利用率。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
什么是AI加速器?
AI 加速器主要面向人工智能领域的性能加速,目前应用最多的AI 框架就是TensorFlow、PyTorch、MXNet、Caffe 等,而这些AI 框架自身都有很多的发布版本被不同的开发者使用,并且各框架都有自己的一套分布式并行方式,我们为了屏蔽不同计算框架之间及不同计算框架版本间的分布式训练差异,通过统一的框架和统一的优化代码来优化这4 种计算框架的不同版本。我们研发了统一的AI 加速器,其架构如下图所示。
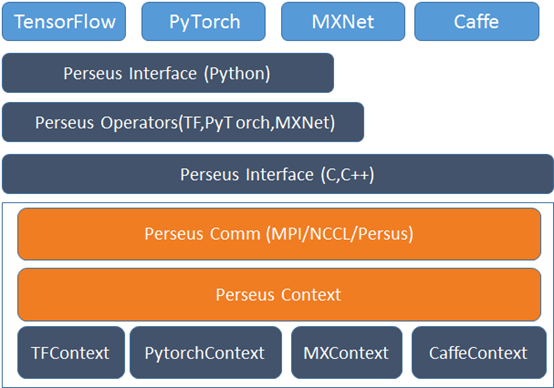
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
I/O 虚拟化技术的实现方式有哪些?
I/O 虚拟化技术,有些地方也叫I/O 设备虚拟化技术,目前主流的模型实现方式有以下几种:
全模拟:纯软件实现,通常由虚拟化层(QEMU)完全模拟一个设备给虚拟机用, 其优点是不需要修改操作系统内核和驱动,因此它是可移植性与兼容性最好的I/O 设备虚拟模型。但是,这种实现模型性能不高,主要原因是:第一,软件模拟本身就无法具有很高的性能;第二,在这种实现方式中,I/O 请求的完成需要虚拟机与监视程序多次的交互,产生大量的上下文切换,开销巨大。
Virtio驱动半虚拟化:将设备虚拟的工作一拆为二,一部分在虚拟机内核中作为前端驱动,一部分放到虚拟化层上(通常是QEMU)作为后端,前后端共享Virtio 环协同完成任务。Virtio 前后端的技术只是减少了VM Exit 和VM Entry(Guest 和Host 的上下文切换),并且使Guest 和Host 能通过并行处理I/O 来提高吞吐量并减少延迟。但是,I/O 的路径并不比全虚拟化技术少。
硬件辅助虚拟化:借助硬件技术,如Intel 的VT-d 技术实现PCI 设备直接挂载给虚拟机,常见的有设备直通和SR-IOV。
纵观各大云服务提供商,FPGA 云服务器采用的都是设备直通,主要因为以下三点:一是FPGA 的性能,客户考虑业务搬迁上云首先要做的就是对比,跟本地物理机比、跟竞品(如GPU/ASIC)比。虚拟化必然导致部分的硬件性能损耗,1% 的性能损失都会增大客户拒绝使用FPGA 云服务器的可能性;二是应用场景,FPGA 比较适用于计算密集型和通信密集型任务。在大数据爆发的时代,很多应用都需要调度多片FPGA 才能满足需求,将同一片FPGA 共享给多个客户的需求并不强烈;三是实现难度,分片FPGA(vFPGA)的多租户场景,在安全和隔离的实现上,虽然可以复用vGPU 方案,但是硬件逻辑开发的难度非常大。综合考虑,各大云服务提供商在FPGA 设备虚拟化时选择的都是性能损耗最小的设备直通方案。
设备直通(Device Passthrough)技术:是将宿主机上的PCIe 设备直接分配给客户机使用,虚拟机独占这个设备,在客户机进行对应的I/O 操作时,不需要通过VMM 或被VMM 截获,所以设备性能几乎无损耗。设备直通技术的实现依赖IOMMU 功能(隔离虚拟机对内存资源的访问),需要硬件支持,比如Intel 平台的VT-d 技术。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 虚拟化技术有哪些典型的应用场景?
FPGA 虚拟化技术比较典型的应用场景包括基于OpenCL 实现的MapReduce 框架和微软的Catapult 项目。
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 有哪些互联方式?
依赖FPGA 互联功能,常见的有三种互联方式,如下图所示。
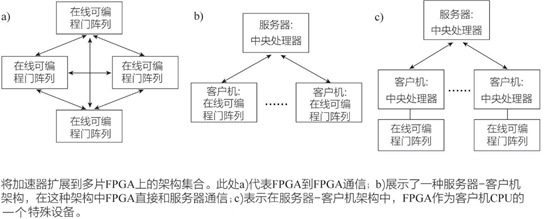
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 虚拟化技术根据资源的抽象级别可以分为哪些类别?
按照资源的抽象级别,FPGA 虚拟化技术分为三类,如下图所示。
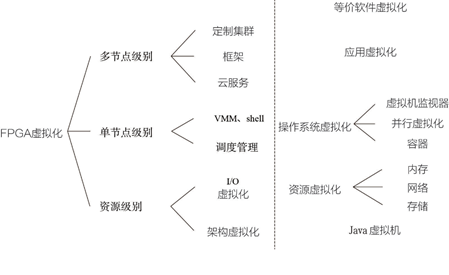
资源级别(Resource Level):FPGA 上的资源可分为两种,一种是可配置的, 一种是不可配置的,所以资源级别的虚拟化主要指架构虚拟化(增加一个抽象层)和I/O 虚拟化,比较典型的技术就是FPGA Overlay 技术,I/O 虚拟化技术本质上跟CPU/ GPU 实现类似,比如FPGA 云主机用到的设备透传功能。
单节点级别(Node Level):单节点指单片FPGA,主要指具备资源管理功能的抽象层,包括VMM(Virtual Machine Monitors,也叫Hypervisor),Shell(FPGA OS 或Hypervisor-vFPGA)和调度管理,主要用于多租户场景,即FPGA 云主机。
多节点级别(Multi-Node Level):多节点指由两片以上FPGA 组成的FPGA 集群,虚拟化的目的是在多片FPGA 上完成同一个加速任务。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 虚拟化技术的虚拟机是什么?
虚拟机通过一个抽象架构来描述应用从而彻底实现设备无关性。起初,虚拟机的概念用来表示FPGA 的静态架构,譬如Shell 或者vFPGA 的Hypervisor,并不是我们现在理解的虚拟机概念。现在的FPGA Overlay 技术是应用比较广泛的FPGA 虚拟化方法之一,它是位于FPGA 硬件层之上、并连接顶层应用的虚拟可编程架构,实现了对FPGA 底层硬件资源的抽象化和虚拟化。FPGA Overlay 的具体实现方式有很多种, 这里不详细介绍,其主要目的是为上层用户提供他们熟悉的编程架构与接口,比如通过C 语言等高层语言对Overlay 中的通用处理器等进行编程,而无须担心具体的硬件电路实现,这点类似HLS。Overlay 实现了FPGA 的硬件无关性,便于应用设计在不同FPGA 架构间移植。另外,用户可以选择只编译自己改动的逻辑部分,在很大程度上缩短了FPGA 的编译时间,也方便对应用进行调试和修改。但是在实际开发中,由于其引入的Overlay 层并不能完全隐藏FPGA 结构,而且此技术没有业界统一标准, 所以会来带额外的开发难度和成本。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 虚拟化技术的虚拟化执行是什么?
虚拟化执行是把一个应用分成几个有关联的任务,并通过一个抽象层来管理和调度它们,其目的是在一定程度上实现设备无关性(Device Independence),从而解决资源管理和安全隔离问题,还可以提高开发效率,比较典型的例子是“PipeRench”项目,此项目成功研发了“Kilocore”芯片,它内置了一个PowerPC 处理器,实现了硬件虚拟化,并可以动态配置,从而解决FPGA 的资源限制问题。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
FPGA 虚拟化技术的时域划分是什么?
时域划分早期主要解决设备容量问题,是将大规模的应用设计拆分为几个小设计,然后将每个设计烧写在单个FPGA 上顺序执行。时域划分技术如下图所示, 主要包括网表划分、数据流图划分和CDFG 划分。随着数据量和计算复杂度的增加, 单片FPGA 已经无法满足一个应用的需求,需要多片FPGA 并行完成,虚拟化技术逐渐打破了时间和空间维度的限制,就像大型数据中心的应用场景:多片FPGA 并行执行同一个任务,并可以及时切换到下一个任务。
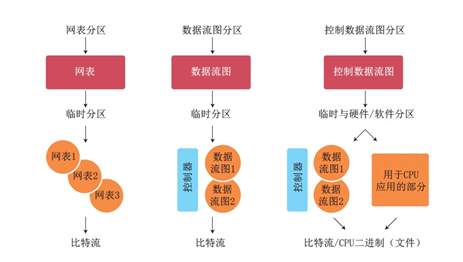
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
什么是FPGA 虚拟化技术?
将FPGA 的高性价比算力通过云输出,使得FPGA 的算力普惠化、平民化,这是FPGA as a Service 的核心出发点和立足点。同时,云上使用FPGA 与FPGA 的传统使用方式也有着非常大的区别。FPGA as a Service 的核心就是FPGA 虚拟化技术。
目前FPGA 虚拟化技术还在发展初期,近几年随着云计算和AI 技术的发展, 才逐渐成为工业和学术领域研究的热点。关于FPGA 虚拟化技术的介绍文献也比较少,关于FPGA 虚拟化技术的发展历史,目前比较全面的总结可以参考2018 年由Manchester 大学学生发表的一篇IEEE 论文A Survey on FPGA Virtualization ,文中提到早在2004 年由Plessl 和Platzner 发表的一篇论文Virtualization of Hardware- Introduction and Survey 中提到过FPGA 虚拟化技术的概念,将FPGA 虚拟化技术分为时域划分(Temporal Partitioning)、虚拟化执行(Virtualized Execution)和虚拟机(Virtual Machines)三种。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
GRID vGPU 的优势的优势是什么?
在 GPU 虚拟分片的场景下,一个物理 GPU 可以直通给多个虚拟机使用,如下图所示,和直通方案相比,具有如下优势。
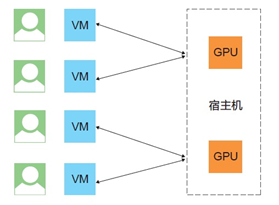
可以更加灵活地选择 GPU 实例规格,降低成本。
将一块物理 GPU 同时共享给多个用户使用,避免不必要的资源浪费。
基于硬件虚拟化技术,可以完美地实现高性能 GPU 在硬件安全隔离下为多用户 所共享。
GPU 虚拟化损耗可忽略,严格保证每用户分配到的 GPU 能力互相无干扰。
支持热迁移,当宿主机发生异常时可以通过热迁移技术迁移 GPU 云服务器实例,保障用户业务不中断。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
什么是GRID vGPU?
GRID vGPU 是 NVIDIA 的一项虚拟化技术,可以把一块 GPU 卡分片并分配给虚拟机使用,从虚拟机的角度来看,和 SR-IOV 一样,每个分片 vGPU 在物理上都是隔离的。GPU 分片虚拟化基于 VFIO Mediated Passthrough Framework 的 GPU 虚拟化方案。该方案由 NVIDIA 提出,并联合 Intel 一起提交到了 Linux Kernel 4.10 代码库,该方案的 Kernel 部分代码简称 mdev 模块,GRID vGPU 方案如下图所示。
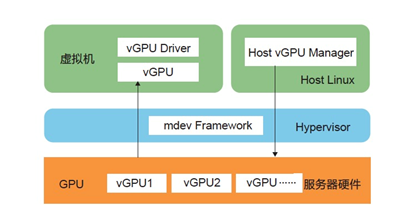
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
GPU SR-IOV 有哪些特性?
GPU SR-IOV 特性如下所述。
-
GPU 的显存是根据设定的虚拟比,由 GPU SR-IOV 驱动静态划分的,不可以 动态修改。
-
虚拟比最大为 16 ∶ 1(一个 GPU 最多虚拟出 16 个 vGPU),并且可以灵活配 置,支持的虚拟比有 16 ∶ 1、8 ∶ 1、4 ∶ 1、2 ∶ 1 和 1 ∶ 1。
-
每个 vGPU(VF)时间片都由 GPU SR-IOV 驱动(GIM)调度,每个 VF 时间片严格按照虚拟比来分配。不同 GPU VF 之间不会争抢资源。
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
-
回答了问题
2021-11-26
SR-IOV 技术有哪些功能?
SR-IOV 技术有如下两种功能。
**1)物理功能(Physical Function,PF) **
宿主机上的物理主设备,宿主机上的 GPU 驱动安装在 PF 上。PF 的驱动是管理者。它是一个完备的设备驱动,与一般 GPU 驱动的区别在于它管理了所有 VF 设备的生命和调度周期,比如下图所示的 07:00.0 就是 S7150 的 PF 设备。
2)虚拟功能(Virtual Function,VF)
也是一个 PCI 设备,如图 3-30 中的 07∶02.0 和 07∶02.1。下图中的一个 PF (S7150)划分出了 4 个 VF,理论上运行在 1 个 VF 上面的虚拟机 GPU 的图形渲染性能是 PF 的 1/4。
在 GPU SR-IOV 方案中,把一个物理 GPU 设备(PF)拆分成多个小份虚拟机 GPU(VF),这些 VF 依然是符合 PCI 规范的 PCIe 设备。GPU SR-IOV 方案在虚拟比 1 ∶ 1 的情况下性能上大概有 5% 的损失。

资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
GPU SR-IOV 技术架构是怎样的?
下图是 GPU SR-IOV 技术架构图,在虚拟化软件栈中加入了 GIM 模块来驱动 GPU 硬件。GIM 模块调用 PCI 子系统接口初始化 SR-IOV 虚拟功能(Virtual Function,VF),并 对硬件资源进行管理分配。VFIO 模块可通过标准的 PCI 设备接口直接使用虚拟功能。虚拟机实例中图形驱动程序将发送请求给 GIM 模块,由其将 虚拟功能使能并调度到硬件资源上运行。GIM 的运行对虚拟化环境而言完全透明,与直通技术没有差别。由于 GPU SR-IOV 使用标准的直通接口把虚拟 GPU 资源分配给虚拟机,所以虚拟机控制系统对其操作的接口与直通技术没有差别。

资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0 -
回答了问题
2021-11-26
GPU 虚拟化模式的GPU SR-IOV 模式是什么样的?
当前只有 AMD 的两款 GPU 产品支持 SR-IOV 模式:S7150 和 MI25。S7150 针对图形渲染的场景,MI25 则针对机器学习领域。阿里云 GPU 云服务器的 GA1 系列采用的就是 S7150,GA1 规格族中的小规格实例采用的是 SR-IVO 方案。将一个物理 GPU 做 SR-IOV 分片虚拟化处理。下图所示的GPU SR-IVO 模式是一个物理 GPU 102 。
通过 SR-IOV 的驱动虚拟出多个虚拟机 GPU。SR-IOV 标准是一种基于硬件的虚拟化解决方案,可提高性能和可伸缩性。
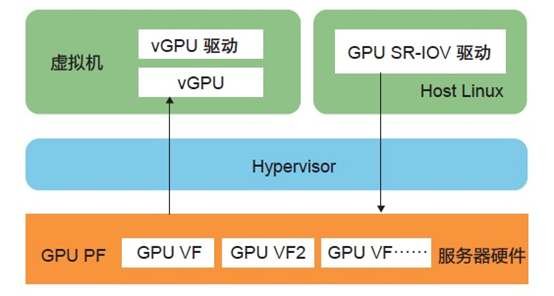
资料来源:《弹性计算—无处不在的算力》
赞0 踩0 评论0
滑动查看更多
暂无更多信息