集群状态(value): 集群状态是监控指标中最重要的指标之一,表示集群的健康度。当数值为2.00(RED),代表集群状态异常,该集群存在不可用的主分片,此时执行查询虽然部分数据仍然可以查到,但实际上已经影响到索引读写,需要重点关注。这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着索引已缺少数据,搜索只能返回部分数据,而分配到这个分片上的请求都返回异常。可能会影响业务。当数值为1.00(YELLOW),代表集群状态异常,主分片可用,但是副本分片不可用。这种情况Elasticsearch集群所有的主分片已经分配了,但至少还有一个副本是未分配的。所以不会影响业务,但是集群高可用性会被降低。当数值为0.00(GREEN),代表集群状态正常,所有主分片和副本分片都可用。当搜索业务不可用的时候, 第一时间看该监控指标, 如果是2 . 0 0(RED),调用ES接口,使用GET /_cat/health?v 命令,查看status的值是否是red,如果是,优先排查ES集群问题,因为监控页面的数据可能存在延迟。如果该指标为非2.00(RED),优先排查ES客户端应用问题。当该指标是2.00(RED)。
快照状态:该指标是指自动备份功能的快照状态,当数值为-1或者0时,代表服务正常。-1代表没有快照,0代表有快照,1表示正在进行快照,2表示快照任务失败。快照任务失败一般是由于集群不健康或者节点磁盘使用率较高原因导致。
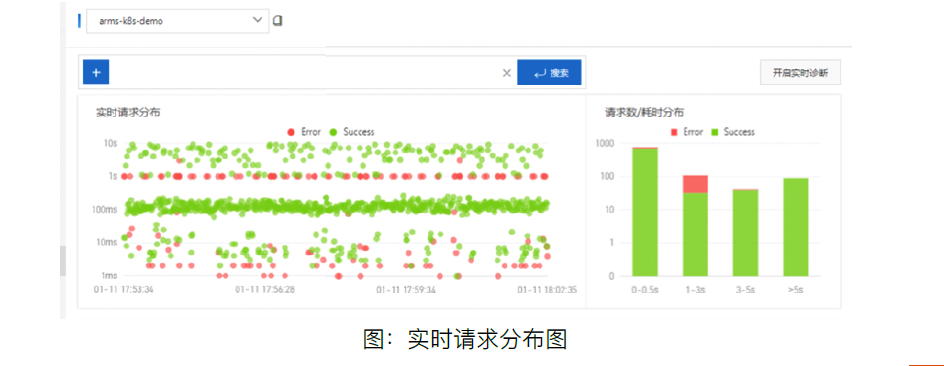
集群写入QPS(Count/Second):集群写入QPS是指集群每秒钟写入的文档数量,通过_bulk API也是计算的写入文档数量,而不是写入请求次数。集群如果出现CPU、内存等资源使用突然增高,优先看下相应时间点,写入或者查询QPS是否有突增。
集群查询QPS(Count/Second):集群查询QPS是指集群每秒钟查询请求QPS数量,查询请求QPS数量是计算的主shard维度,所以查询请求QPS数量与查询的索引主分片数量有关,例如查询的索引有5个主分片,则一次查询请求对应5个QPS。
这里可能会造成疑惑的地方,一是我业务上明明没有这么多请求,但是监控上能看到更多。二是集群中有一些系统默认的索引,kibana、.monitoring-es 也会产生一定的QPS。
节点CPU使用率(%):展示了集群节点CPU使用百分比,当CPU使用率波动较大时,尤其是超过90%,需要重点关注,可能会导致ES服务异常。
节点HeapMemory使用率(%):展示了集群节点内存使用百分比,当内存使用率波动较大时,尤其是超过90%,需要重点关注,可能会导致ES服务异常。另外,当内存使用过高时,会产生GC。
节点磁盘使用率(%):节点磁盘使用率是指各节点的磁盘使用率,建议控制在75%以下,如果没有调整过,集群默认设置是磁盘使用率超过85%,会导致新的分片无法分配。超过90%:ES会尝试将对应节点中的分片迁移到其他磁盘使用率比较低的数据节点中。超过95%:系统会对Elasticsearch集群中的每个索引强制设置read_only_allow_delete属性,此时索引将无法写入数据,只能读取和删除对应索引。不过这个默认设置是支持修改的,修改参数cluster.routing.allocation.
disk.watermark.low、cluster.routing.allocation.disk.watermark.high、cluster.routing.allocation.disk.watermark.flood_stage。
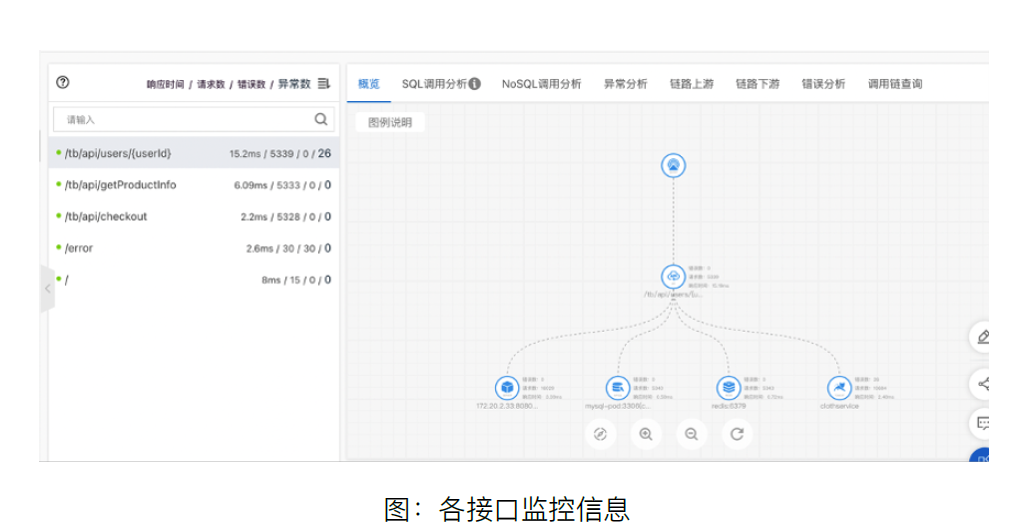
节点load_1m(value):展示了集群中各节点在1分钟内的负载情况,这个字段并不是表示CPU的繁忙程度,而是度量系统整体负载。该指标的正常数值,应该低于对应节点规格的CPU核数。
FullGc次数(count):FullGc次数指标展示了集群中1分钟内的full gc总次数,如果gc次数为0需要关注下。
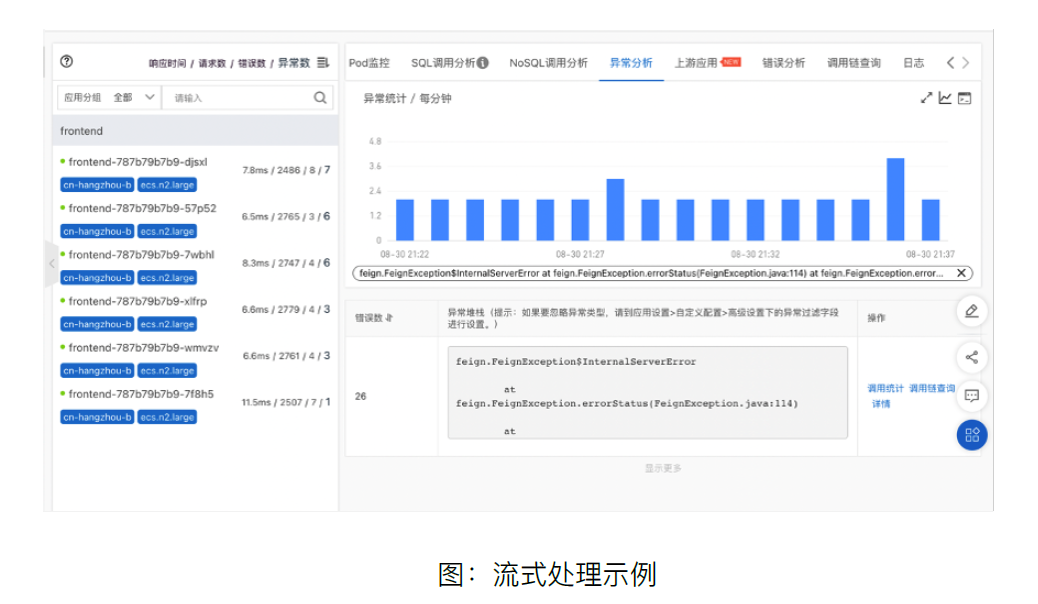
Exception次数(count):Exception次数指标展示了集群的主日志中,一分钟内出现的ERROR和WAEN级别日志的总个数。
节点网络流入包(count):是指每分钟集群中各节点网络流入流量包的数量,集群如果出现CPU、内存等资源使用突然增高,并且QPS没有增多的情况时,可以关注下节点网络流入包监控趋势。
节点网络流出包(count):是指每分钟集群中各节点网络流入流量包的数量。
集群如果出现CPU、内存等资源使用突然增高,并且QPS没有增多的情况时,可以关注下节点网络流入包监控趋势。
数据流入率(KB/s):是指集群中各节点每秒数据包的流入速率,周期是1分钟。集群如果出现CPU、内存等资源使用突然增高,并且QPS没有增多的情况时,可以关注下节点网络流入包监控趋势。
数据流出率(KB/s):是指集群中各节点每秒数据包的流出速率,周期是1分钟。集群如果出现CPU、内存等资源使用突然增高,并且QPS没有增多的情况时,可以关注下节点网络流入包监控趋势。
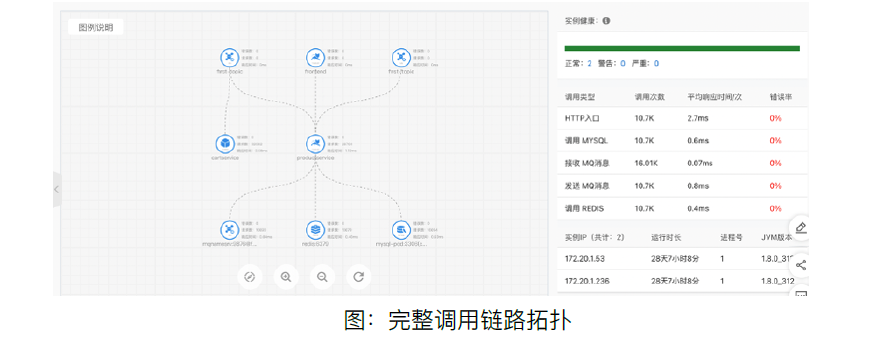
节点TCP链接数(count):节点TCP链接数指标展示了集群中各节收到客户端每次发起TCP连接请求的数量。该指标能在一定成都上反应出客户端使用ES的程度,当该指标有增加的情况,要在业务上确认下,是否符合预期。如果不符合预期,要检查下,是否是客户端发起TCP连接长时间未释放,导致节点TCP连接数量突增等原因。
个IO的能力的,所以即使IOUtil达到了100%,也无法说明磁盘的IO打满了,所以无法通过这个指标来衡量磁盘的饱和度,不过可以通过IOUtil的使用趋势,反映出磁盘IO的压力变化。
每秒完成的读请求数量(count):每秒完成的读请求数量是指集群中各节点每秒完成的读请求的数量。
每秒完成的写请求数量(count):每秒完成的写请求数量是指集群中各节点每秒完成的写请求的数量。
每秒钟读取的大小(MB/s):每秒钟读取的大小指标展示了集群中各节点每秒读取的数据量。
每秒钟写入的大小(MB/s):每秒钟写入的大小指标展示了集群中各节点每秒写入的数据量。
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版