大模型
产品
解决方案
权益
定价
云市场
伙伴
服务
了解阿里云
查看 "" 全部搜索结果
AI 助理
文档
备案
控制台
开发者社区
首页
技术博文
动手实践
对象存储
文件存储
块存储
日志服务
免费试用
探索云世界
热门
百炼大模型
Modelscope模型即服务
弹性计算
通义灵码
云原生
数据库
云效DevOps
龙蜥操作系统
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
数据可视化DataV
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
镜像站
开发者社区
技术作品
阿里云存储产品手册
在线阅读
148
1
读书笔记
暂无相关笔记,快来写一篇吧!
# 读完《阿里云存储产品手册》之后个人产生的3个疑问 首先声明,我并没有任何说要挑刺或者搞事情的意图,阿里云的产品我所在公司是纳入选型的Tier 1的,只是文档中有些地方确实令我产生了困惑,**无恶意询问一下**。 ## 1、数据得出的方式: 主要还是在【小天才】案例中提到了**“业务问题定位速度提升了30%”**,如果表述是“针对数据异常的检索速度提升了30%”我倒还是能够理解,因为更好的数据引擎确实能够带来速度的提升。 只是业务问题的定位个人觉得应该不单单是一套存储产品升级能够带来的(除非是那种纯粹做数据服务的公司),所以比较好奇这个数据究竟是如何来的,还是说只是一个大致预估? 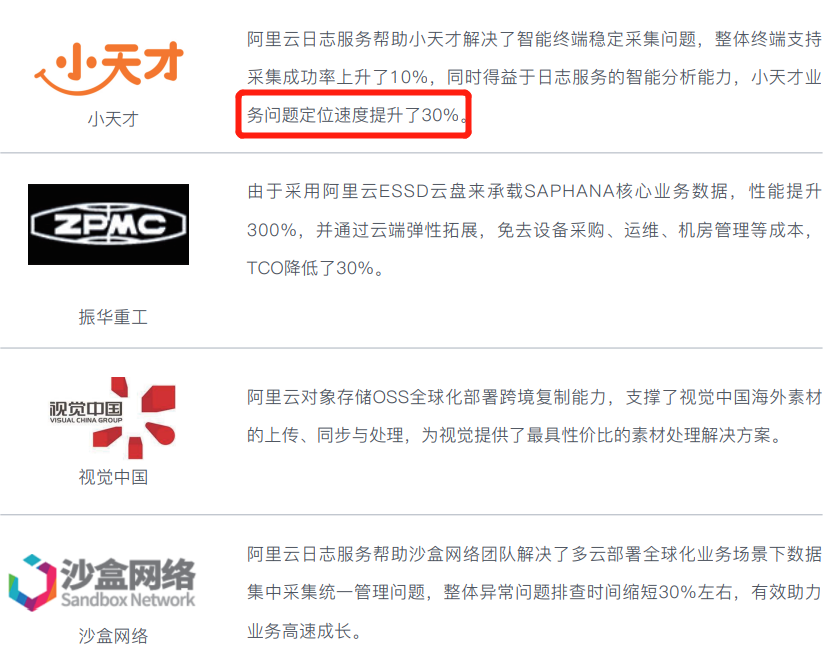 ## 2、功能横向对比的标准: 【哈啰出行】案例中提到了“替代了原有的Kafka节省的成本达到30%”,这我能够理解,因为Kafka确实比较贵,只是该案例中仅仅提到了“满足了稳定性、扩展性需求”,没有提到一些核心指标比如“消息队列的吞吐量和丢失率”有没有较大变动。 给人的感觉有点像“因为坐飞机比较贵,所以我们换成了坐汽车”,**确实,更改之后在安全、舒适、成本都有提升或保障,但没有提到速度和时效会不会受影响。**  ## 3、对外网的支持: 我们公司有一部分业务是要对接到泰国进口大米,所以后续可能会有海外业务的需求,海外业务需要使用外网,**文档里面更多侧重点还是在“内网和公网”**,对外网似乎很少提及,不知有没有补充?比如说“经过VPN时对VPN的渗透监测”? 



