
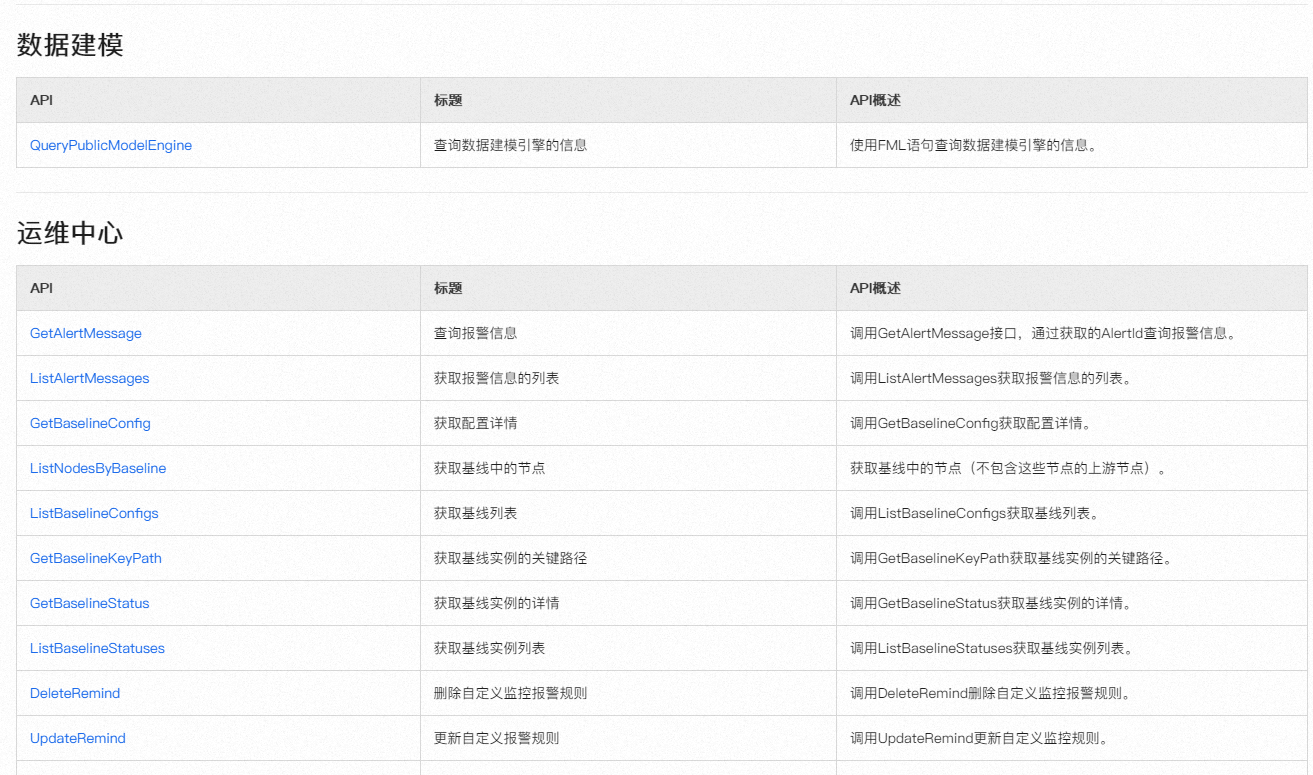
datawork api看文档返回的是个map,如果我一次性要查很多条数据,该怎么用?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当您通过DataWorks API查询数据且预期返回结果较多时,应考虑使用返回结果分页功能来有效管理和获取数据。具体操作如下:
page_number和page_size,来指定查询的页码和每页数据量,从而实现数据的分批次获取。相关链接
https://help.aliyun.com/zh/dataworks/support/dataservice-studio
在DataWorks中,如果您通过API查询数据时返回的是一个Map结构,并且需要一次性处理大量数据,可以采用以下策略来高效处理:
分批查询:
pageSize和pageNumber),您可以设置合适的页面大小来分批次获取数据,减少单次请求的数据量,提高处理效率和稳定性。循环处理Map:
map.entrySet().forEach()来迭代处理每一条记录。批量插入或更新:
异步处理:
内存管理:
API调用频率控制:
通过上述方法,您可以有效地管理和处理通过DataWorks API获取的大量数据,确保操作既高效又稳定。
相关链接
数据服务API 进入API查找界面 https://help.aliyun.com/zh/dataworks/user-guide/query-an-api
构造请求:根据API文档,构造HTTP请求。如果是GET请求,可能需要将参数附加到URL上;如果是POST请求,则需要在请求体中包含参数。
分页查询:如果API支持分页,您可以使用分页参数(如page_size和page_number)来逐步获取数据。这样可以避免一次性加载过多数据导致的性能问题。
如果你需要一次性查询多条数据,可以将多个键值对放入一个列表中,然后遍历这个列表来获取每个键对应的值。以下是一个使用Python的示例:
python
复制代码运行
import requests
def get_datawork_data(api_key, keys):
url = "https://datawork.example.com/api" # 请替换为实际的API地址
headers = {"Authorization": f"Bearer {api_key}"}
results = {}
for key in keys:
response = requests.get(f"{url}/{key}", headers=headers)
if response.status_code == 200:
results[key] = response.json()
else:
print(f"Error fetching data for key {key}: {response.status_code}")
return results
api_key = "your_api_key" # 请替换为你的API密钥
keys = ["key1", "key2", "key3"] # 请替换为你要查询的键列表
data = get_datawork_data(api_key, keys)
print(data)
在这个示例中,get_datawork_data函数接受一个API密钥和一个键列表作为参数。它遍历键列表,对每个键发起请求,并将结果存储在一个字典中。最后,它返回包含所有键值对的字典。
当使用DataWorks API并且发现单个API调用返回的是一个map,这通常意味着每次调用只能获取一条数据的详情。如果你需要一次性查询很多条数据,有几种不同的策略可以考虑,具体取决于API的设计和你的具体需求。以下是一些建议:
批量请求(如果API支持):
检查DataWorks API文档,看是否有提供批量查询的API。一些API平台会提供专门的批量请求接口,允许你一次性查询多条数据。
分页查询:
如果API支持分页(pagination),你可以通过循环调用API并调整分页参数(如页码page和每页条数pageSize)来逐页获取数据。虽然这不是一次性查询所有数据,但它允许你以较高效的方式获取大量数据。
并发请求:
如果你的查询任务允许并发执行,并且你能够处理并发结果,你可以考虑使用多线程或多进程来并发地向API发送请求。这种方式可以显著减少总查询时间,但需要注意处理好并发请求之间的资源竞争和结果合并。
缓存机制:
如果数据不经常变化,或者你对数据的实时性要求不高,可以考虑使用缓存机制。在第一次查询后,将结果缓存起来,并在后续的请求中优先从缓存中获取数据。这不仅可以减少API调用次数,还可以提高应用的响应速度。
优化查询条件:
如果可能,尝试优化你的查询条件以减少需要查询的数据量。例如,使用更具体的筛选条件来减少返回的map数量。
API反馈与请求:
如果上述方法都不可行,或者你对API的使用有疑问,可以考虑向API的提供者(如阿里云DataWorks支持团队)反馈你的需求,询问是否有批量查询的解决方案或者是否有计划在未来版本中支持这一功能。
自定义脚本或工具:
在某些情况下,你可以编写自定义的脚本或工具来自动化API的调用过程。例如,使用Python的requests库或Java的HttpClient来编写一个脚本,该脚本循环调用API并处理返回的数据。
综上所述,没有一种通用的方法可以直接适用于所有情况,你需要根据DataWorks API的具体设计和你的具体需求来选择最合适的策略。
如果您使用DataWorks API并且返回的数据结构是一个Map(键值对集合),但您需要查询大量数据时,通常可以采取以下几种策略来优化处理流程和提高效率:
如果API支持分页查询,您可以请求多个页面的数据。例如,每次请求一部分数据(比如100条记录),然后遍历所有页面直到获取到所有需要的数据。
如果API支持批量查询,您可以一次请求多个ID或其他标识符对应的记录,以减少API调用次数。
某些API可能支持流式数据传输,这样可以在数据生成的同时进行处理,而不是等待整个数据集准备好后再开始处理。
如果API支持异步处理,您可以提交一个查询任务并稍后获取结果,这样可以避免长时间等待响应。
对于重复查询的数据,可以考虑使用缓存机制来存储已经获取过的数据,减少不必要的API调用。
假设您有一个返回Map的API,并且您需要查询大量数据,这里提供一个简单的Java伪代码示例说明如何处理这种情况:
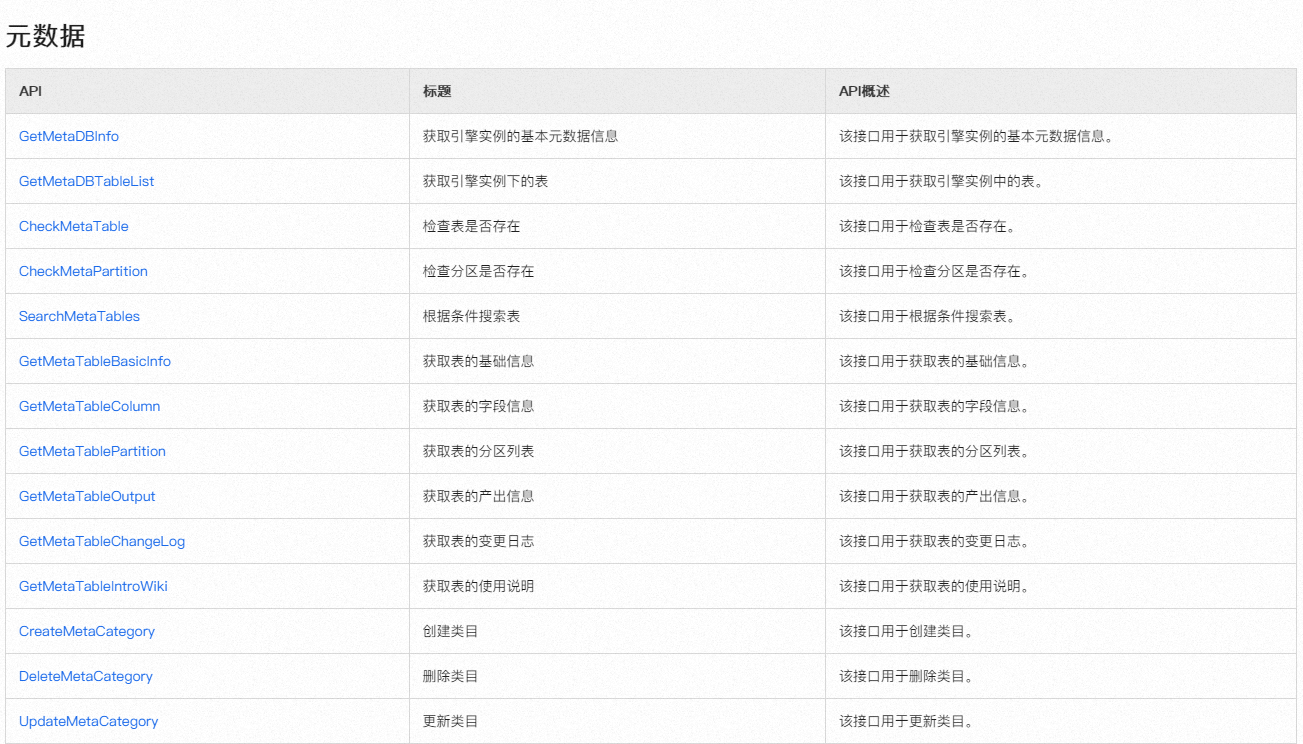
import java.util.Map;
import java.util.List;
public class DataFetcher {
private DataWorksApi dataWorksApi = new DataWorksApi(); // 假设这是您的DataWorks API客户端
public List<Map<String, Object>> fetchManyRecords(int pageSize, int totalPages) {
List<Map<String, Object>> allRecords = new ArrayList<>();
for (int page = 1; page <= totalPages; page++) {
Map<String, Object> pageRecords = dataWorksApi.fetchPage(page, pageSize);
allRecords.addAll(pageRecords.values()); // 假设每个页面的记录是按key存储的
}
return allRecords;
}
}
这个示例中,我们通过循环请求每一页的数据,并将它们收集到一个列表中。请注意,上述代码仅作示例用途,实际实现可能会有所不同。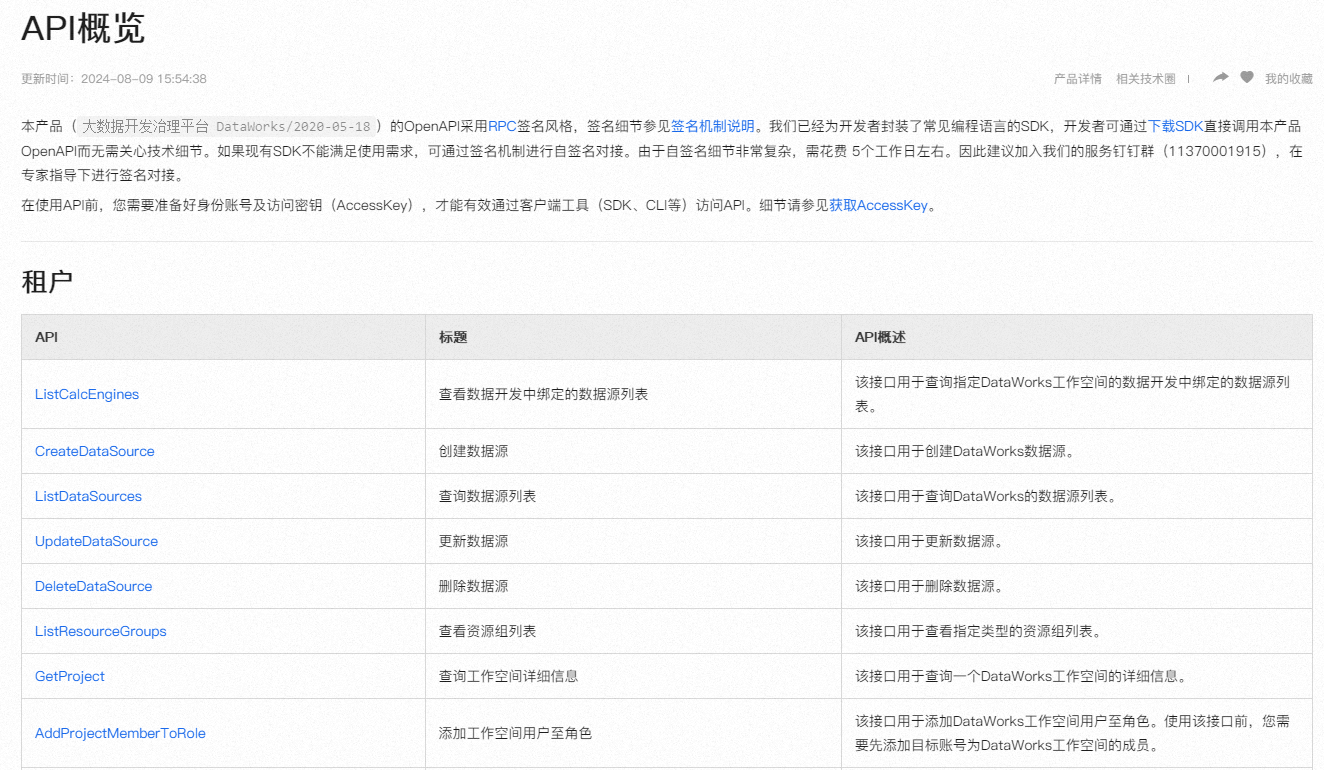
请根据具体的API文档和您的应用场景来选择合适的方法。如果需要更详细的帮助,请提供更多关于API的信息。
在使用DataWork API时,如果你需要一次性查询多条数据,通常你需要将这些查询条件构建成一个列表或数组,然后通过循环遍历这个列表,对每一条数据进行单独的API调用。这是因为大多数RESTful API设计都是针对单个资源的操作,一次请求通常只处理一个ID或一个特定的查询条件。
然而,具体的操作方式会根据API的设计和你使用的编程语言有所不同。以下是一个Python示例,假设query_data是一个包含多个查询条件的列表,每个条件都是一个字典,api_call是你的API调用函数:
# 假设你的API调用函数如下,它接受一个查询条件并返回一个Map
def api_call(query):
# 这里应该是你实际的API调用代码,例如使用requests库
response = requests.get('http://your-api-url', params=query)
return response.json()
# 查询条件列表
query_data = [
{"id": 1},
{"id": 2},
{"id": 3}
]
# 循环调用API并存储结果
results = []
for query in query_data:
result = api_call(query)
results.append(result)
# 结果是一个包含所有查询结果的List
print(results)
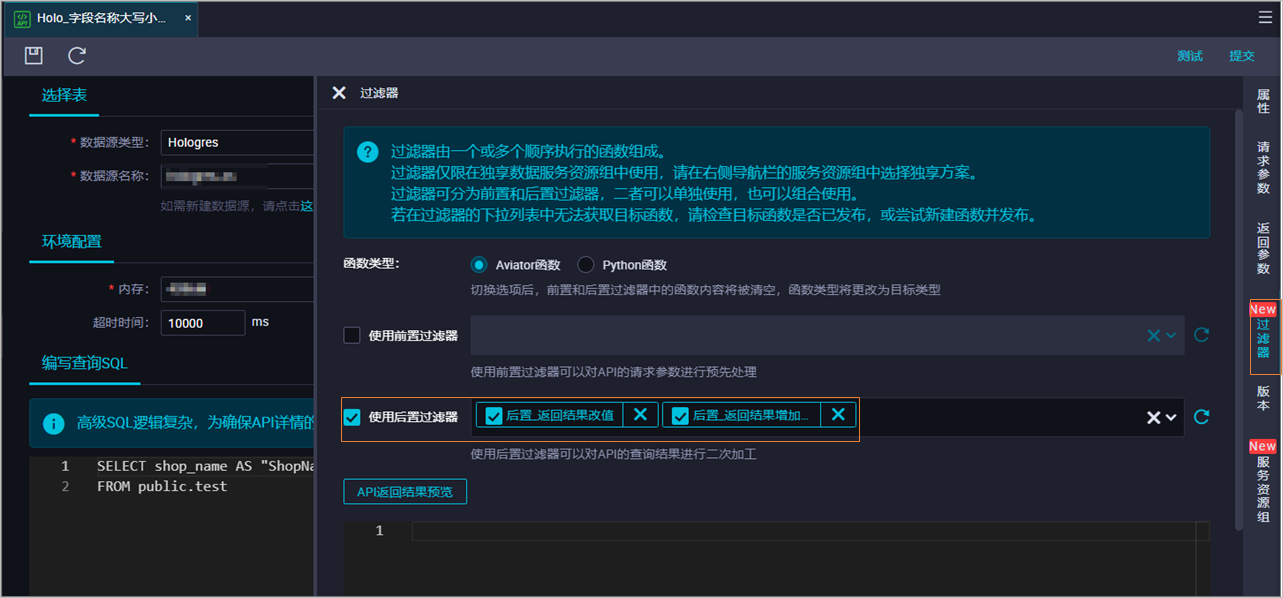
使用Aviator函数,如果API返回的数据结果(JSON格式)中字段很多,不想逐个判断字段返回值,可以用这个函数来遍历所有字段。
## 首先获取到JSON中的最内层数组rows,然后对数组rows进行嵌套遍历,即:对数组rows中的每个元素,进一步获取其中的map;当map中的value值为null时,改值为"测试"
## 在Aviator语法中,nil是空值常量,相当于其他语法中的null
rows = $0.data.rows;
for row in rows
{
for index in row
{
if(index.value == nil)
{
index.value = "测试"
}
}
}
return $0;
函数的输入及输出:
## 输入:
{
"data": {
"totalNum": 3,
"pageSize": 10,
"rows": [
{
"user_id": null,
"city": "SH",
"tags": "A,C,D,F"
},
{
"user_id": 2,
"city": "BJ",
"tags": "数据服务"
},
{
"user_id": null,
"city": null,
"tags": "A,B,C"
}
],
"pageNum": 1
},
"errCode": 0,
"requestId": "0bb211f016372870359913841e52d8",
"errMsg": "success",
"apiLog": null
}
## 输出:
{
"data": {
"totalNum": 3,
"pageSize": 10,
"rows": [
{
"user_id": "测试",
"city": "SH",
"tags": "A,C,D,F"
},
{
"user_id": 2,
"city": "BJ",
"tags": "数据服务"
},
{
"user_id": "测试",
"city": "测试",
"tags": "A,B,C"
}
],
"pageNum": 1
},
"errCode": 0,
"requestId": "0bb211f016372870359913841e52d8",
"errMsg": "success"
}
——参考链接。
有俩方式:
在DataWorks中,如果您通过API查询数据时返回的是一个Map结构,并且需要一次性处理大量数据,可以采用以下策略来高效处理:
分页查询:
大多数API设计时会支持分页查询功能,以减少单次请求的数据量并提高响应速度。您可以利用请求参数中的pageSize和pageNumber(或其他类似命名的参数)来控制每次查询的数据量和页码。这样可以分批次获取全部数据,避免一次性加载过多数据导致的性能问题。
循环调用与合并结果:
根据实际需求设置合适的分页大小,然后在代码中实现循环逻辑,每次调用API获取一页数据,直至所有数据被遍历。将每页返回的Map数据合并到一个大的数据集合(如List>)中,以便后续处理
这里可以查询一下API
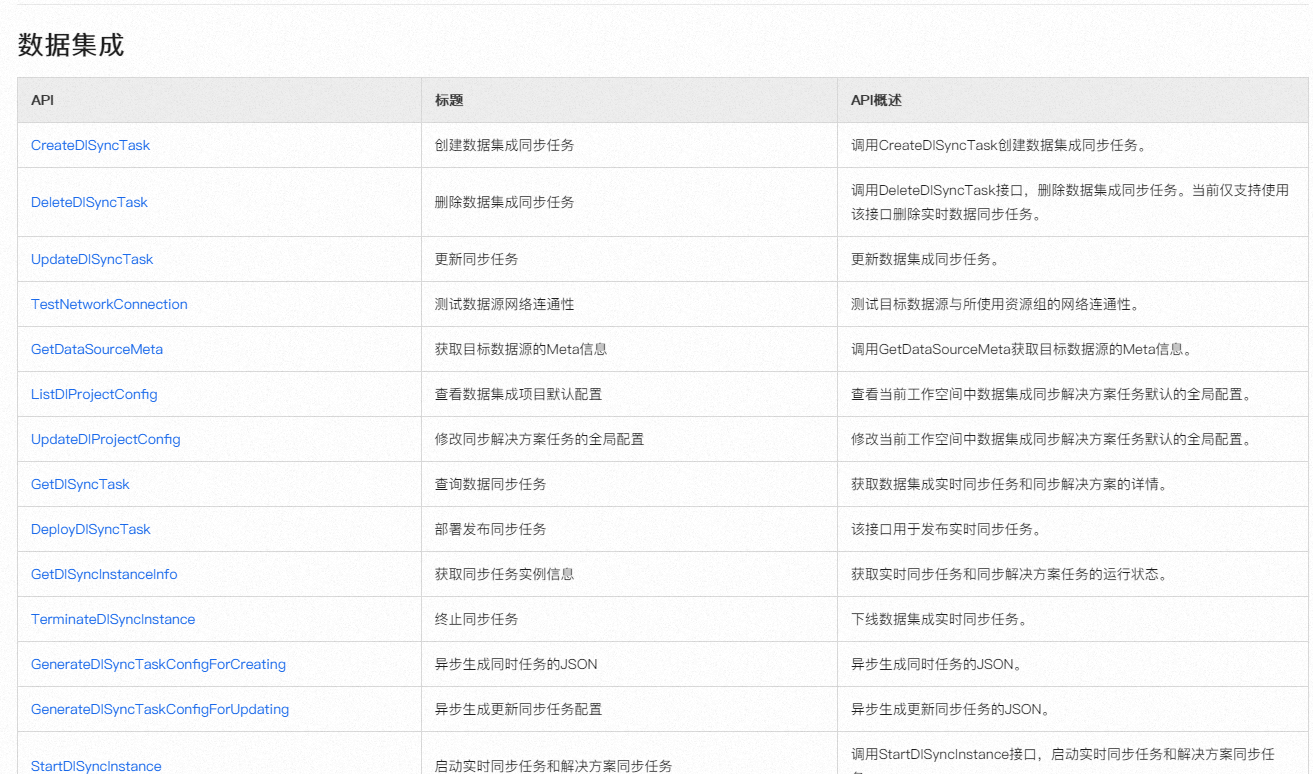
可以利用 DataWorks 提供的 OpenAPI 来实现批量操作和系统集成对接等工作,提高数据开发效率
。例如,您可以使用 DataWorks 的 GetMetaDBTableList API 来获取元数据表的列表信息,并进行分页查询
。此外,DataWorks 还提供了批量操作界面,允许用户对节点、资源、函数等进行批量编辑和操作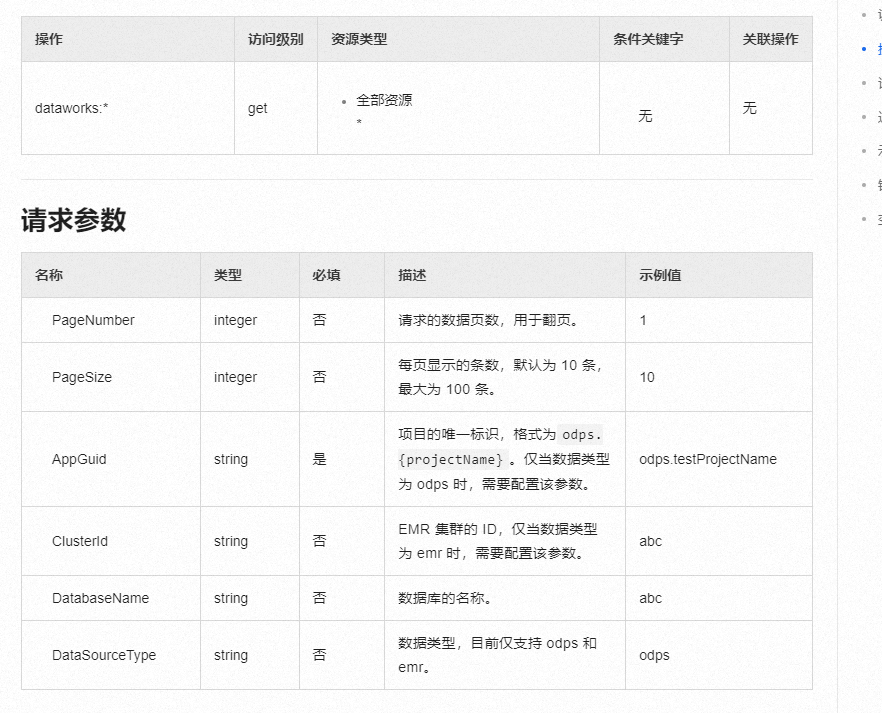
批量查询语句就行。
执行查询语句
在SQL编辑框内编辑对应数据源的查询代码,完成后执行对应命令即可获取查询结果。
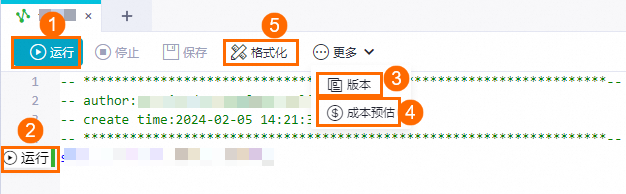
使用过程中,您可以:
①、②运行代码,运行完成后可查看对应代码的运行结果。
方式一:选中部分代码后单击运行。
方式二:单击SQL语句左侧的快捷运行按钮执行一行代码。
③代码版本:您也可以单击更多 > 代码版本来查看自动保存的代码和手动保存代码间差异,并选择需要的版本保存。
④成本预估:单句运行时界面会提示您此次调试运行可能需要的费用,运行完整代码前,您也可以单击更多 > 成本预估来对全量代码运行可能需要的费用进行预估。
说明
目前仅MaxCompute可以使用该功能。
⑤格式化:您也可以通过格式化将自行排版的代码一键规范化排版。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/sql-query?spm=a2c4g.11186623.0.i6
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


