
流水线并行是如何工作的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
所谓流水线并行,就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。
如下图所示,模型共包含四个模型层(如:Transformer层),被切分为三个部分,分别放置到三个不同的计算设备。即第 1 层放置到设备 0,第 2 层和第三 3 层放置到设备 1,第 4 层放置到设备 2。
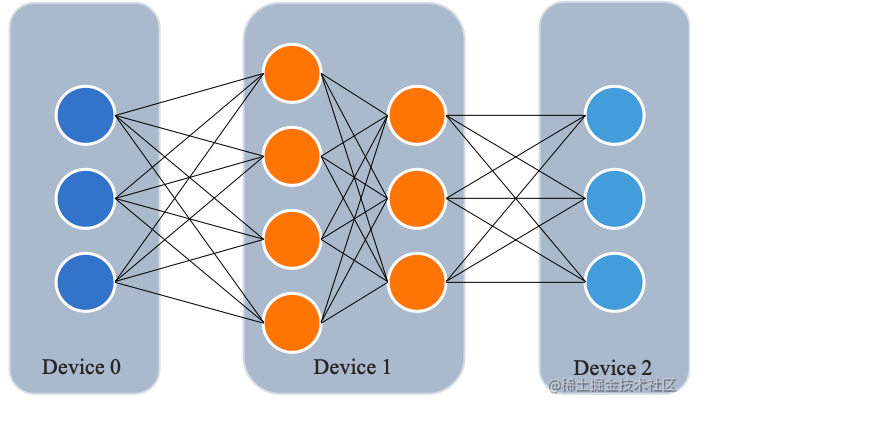
相邻设备间通过通信链路传输数据。具体地讲,前向计算过程中,输入数据首先在设备 0 上通过第 1 层的计算得到中间结果,并将中间结果传输到设备 1,然后在设备 1 上计算得到第 2 层和第 3 层的输出,并将模型第 3 层的输出结果传输到设备 2,在设备 2 上经由最后一层的计算得到前向计算结果。反向传播过程类似。最后,各个设备上的网络层会使用反向传播过程计算得到的梯度更新参数。由于各个设备间传输的仅是相邻设备间的输出张量,而不是梯度信息,因此通信量较小。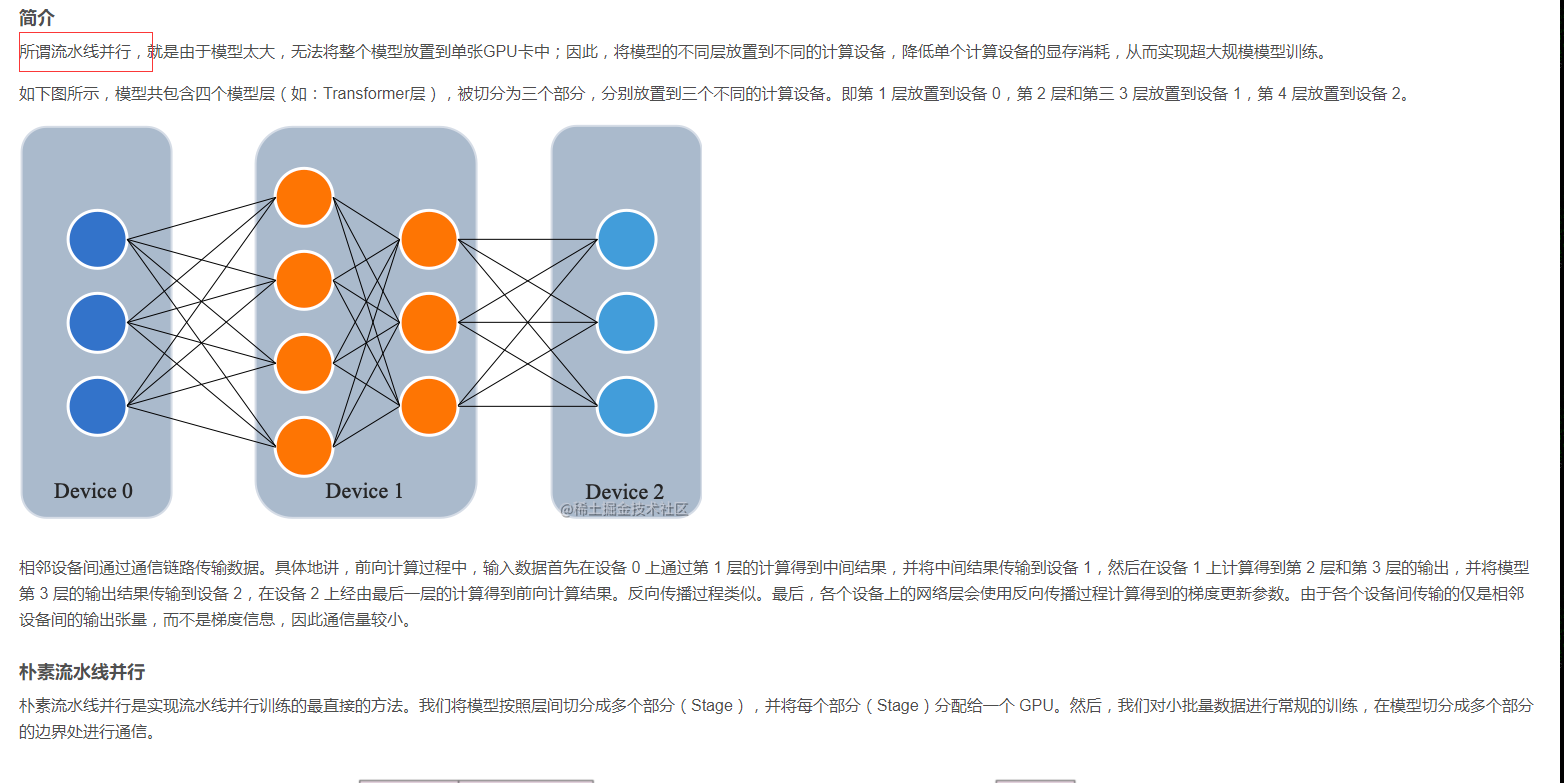
参考文档https://blog.csdn.net/2301_78285120/article/details/132702269
流水线并行(Pipeline Parallel, PP)是模型的层与层之间的拆分,将不同的层放到不同的GPU上。在计算过程中,必须顺序执行,因为后面的计算过程依赖于前面的计算结果。为了保持流水线并行的高吞吐,需要将一个较大的Batch size切分成多个小Batch。

