
企业在大模型训练、微调和推理环节对算力的需求有何不同?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
不同的企业对算力的需求存在显著差异,
首先是训练阶段:这一阶段通常需要最高的算力。因为训练大型模型需要处理海量的数据,并且需要进行多次迭代以优化模型参数。这通常涉及到大量的浮点运算,因此需要大量的GPU或TPU资源。例如,训练一个千亿参数规模的大型模型可能需要数千个GPU,并且可能需要数周的处理时间,成本可能达到数百万美元可以参考这个文档: https://www.thepaper.cn/newsDetail_forward_22716419
而微调阶段:微调通常需要的算力比训练阶段要低,因为不需要从头开始训练模型,而是在已有的基础上进行调整。但是,如果微调涉及到全参数更新,它仍然可能需要相对较高的算力,尤其是对于大型模型。一些优化技术如LoRA(Low-Rank Adaptation)可以减少所需的算力
最后是推理阶段:推理是指使用训练好的模型对新数据进行预测。与训练和微调相比,推理通常需要的算力较低,因为它只涉及模型的前向传播。然而,对于大型模型,即使是推理也可能需要相对较多的GPU资源,特别是当需要快速响应或处理大量请求时。此外,推理的算力需求还取决于模型的复杂性和输入数据的大小
这个是大致的图: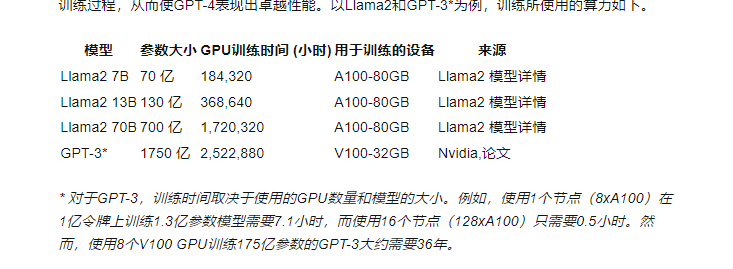
文章参考: https://www.zhihu.com/tardis/bd/art/672573246?source_id=1001

