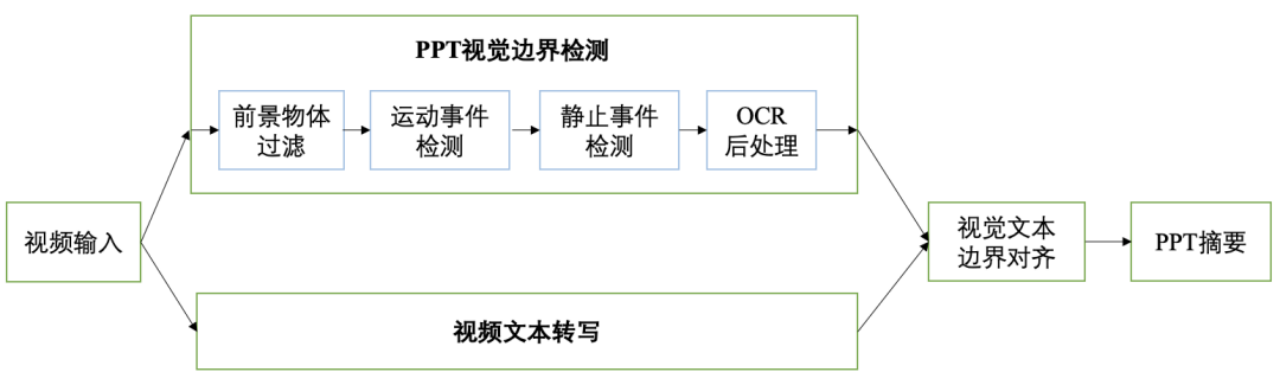
请简述PPT视觉边界检测及大模型摘要的基本流程。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PPT视觉边界检测及大模型摘要的基本流程包括:从视频中采集视频帧得到视频帧序列,进行前景物体过滤,依据运动和静止事件检测结果锚定PPT切换的时间戳,进行时间戳校准、相似度去重、OCR识别PPT内容等后处理操作,最后对齐视频转写的文本和PPT内容,输入到通义听悟摘要大模型得到每张PPT对应讲解内容的摘要总结。