
大数据计算MaxCompute里面使用分区字段关联会和hive里面一样提升效率吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
MaxCompute中的分区设计与Hive类似,目的都是为了优化查询性能。通过使用分区字段,可以减少在执行查询时扫描的数据量,从而提高查询效率。当查询涉及的分区字段是JOIN操作的一部分时,确实能够提升JOIN的效率,因为它允许MaxCompute在JOIN之前过滤掉不相关的数据分区。
MaxCompute的优化策略与Hive可能会有所不同,具体提升的效率取决于数据分布、查询复杂性和MaxCompute的执行引擎优化。为了获得最佳性能,建议遵循最佳实践,如使用适当的分区策略,确保热点数据分散在不同分区,以及利用索引来进一步加速查询。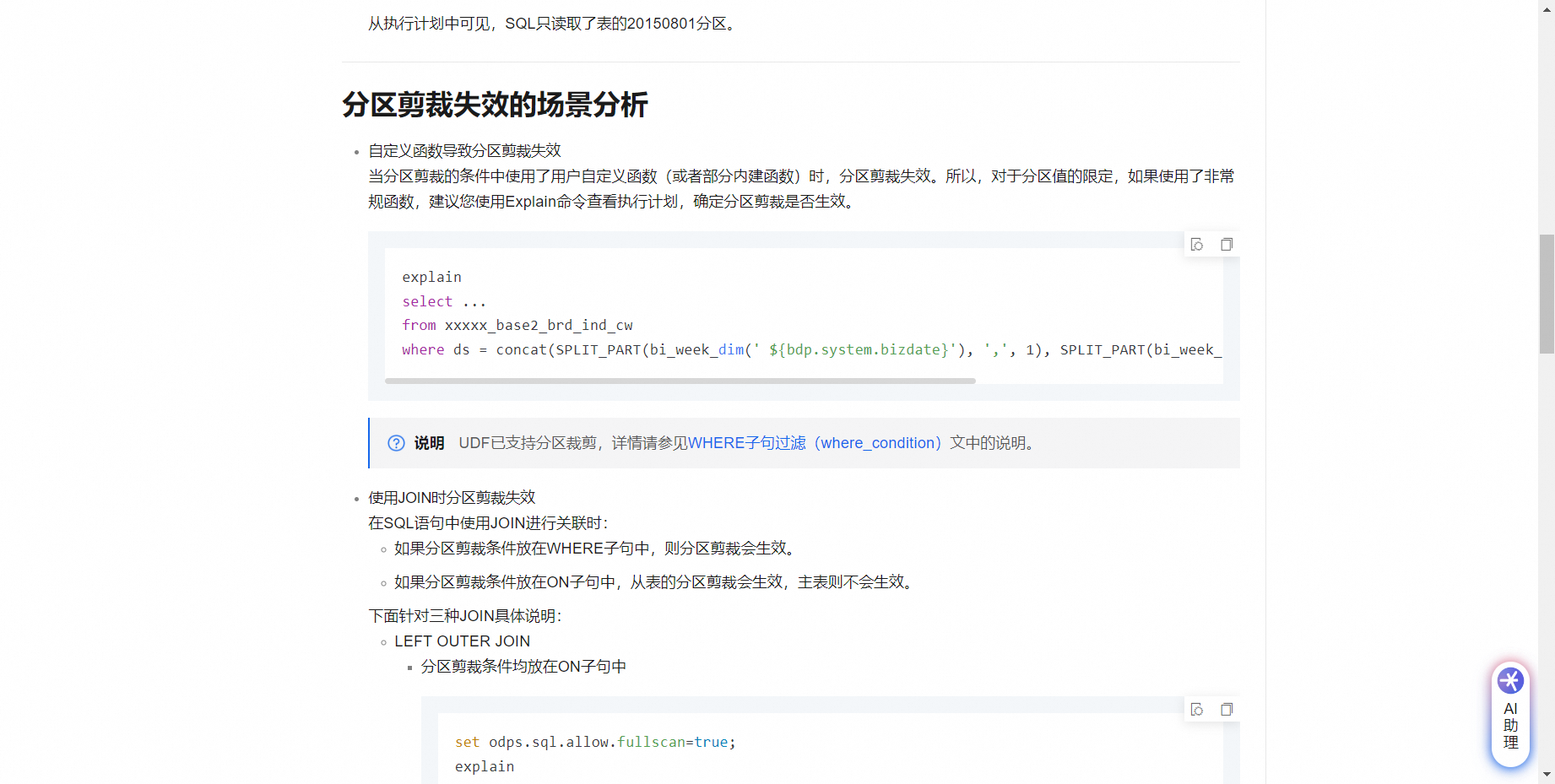
会,参考下:https://help.aliyun.com/zh/maxcompute/use-cases/check-whether-partition-pruning-is-effective?spm=a2c4g.11186623.0.i36#section-ebd-cyd-5db ,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


