
DataWorks使用数据集成同步mongodb时报错 怎么解决?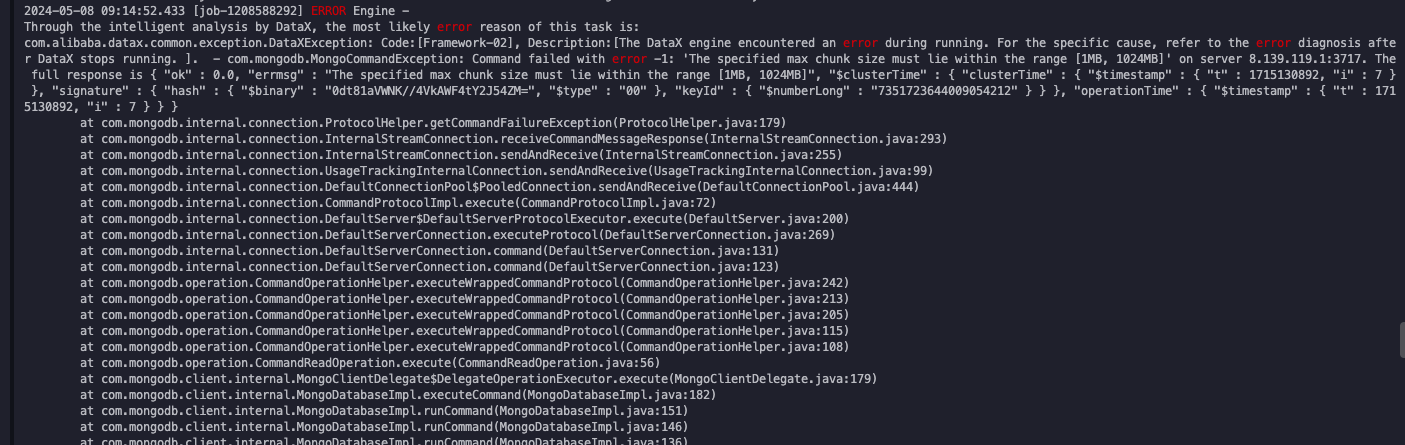
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
use SplitVector to splitCollection, dockCount: 904117, avgObjSize: 595, chunkDockCount: 452058maxChunkSize: 1026
我理解 每个块上限 1026M,按现在的切分 每个chunk要包含452068个文档 平均每个文档595字节 超过了上限
尝试配置一下splitFactor 默认1 可以增加试试https://help.aliyun.com/zh/dataworks/user-guide/mongodb-data-source?spm=a2c4g.11186623.0.i1#task-2310398
转脚本 增加splitFactor参数,和column参数同级 ,此回答整理自钉群“DataWorks0群已满,新群请看群公告”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

