
请问各位大佬 flinkcdc2.4.2读取sqlserver写入iceberg不是边读边写吗 日志显示读了30分钟读了276万 但是iceberg表中一查还是8095条 。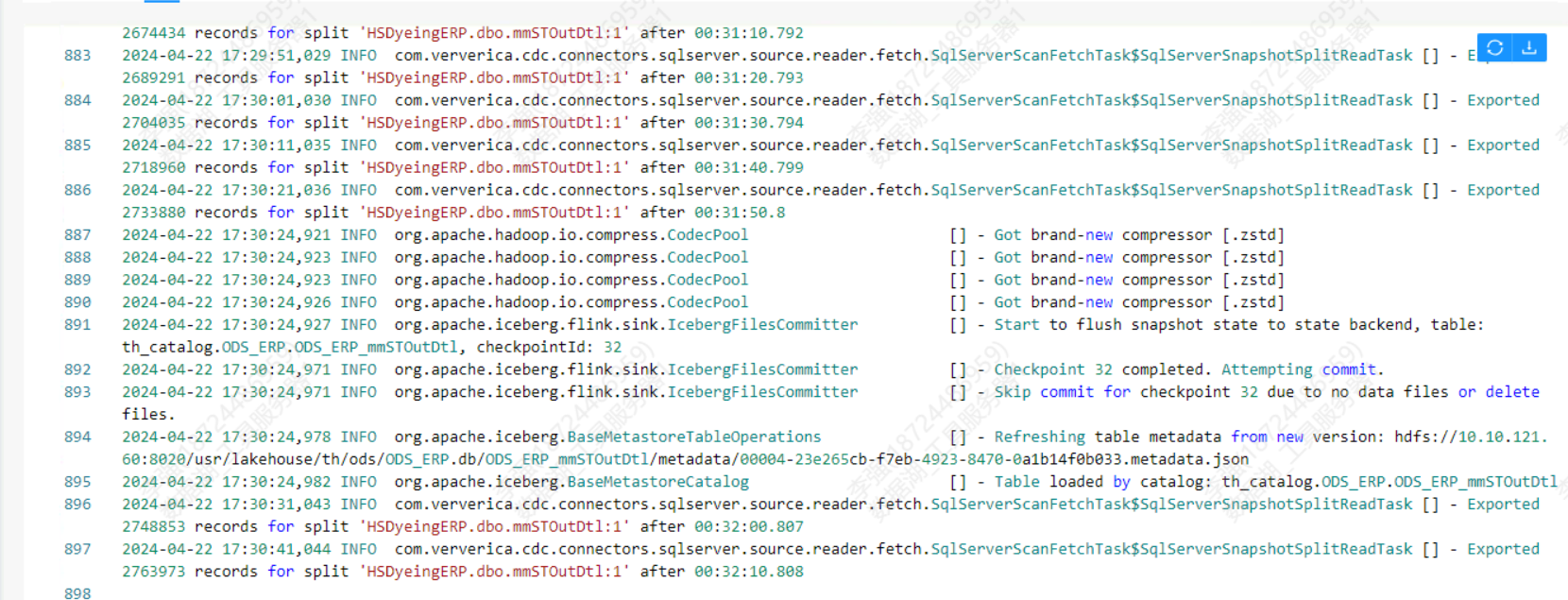 仔细观察了一下日志 就刚开始commit过 之后就不commit了。
仔细观察了一下日志 就刚开始commit过 之后就不commit了。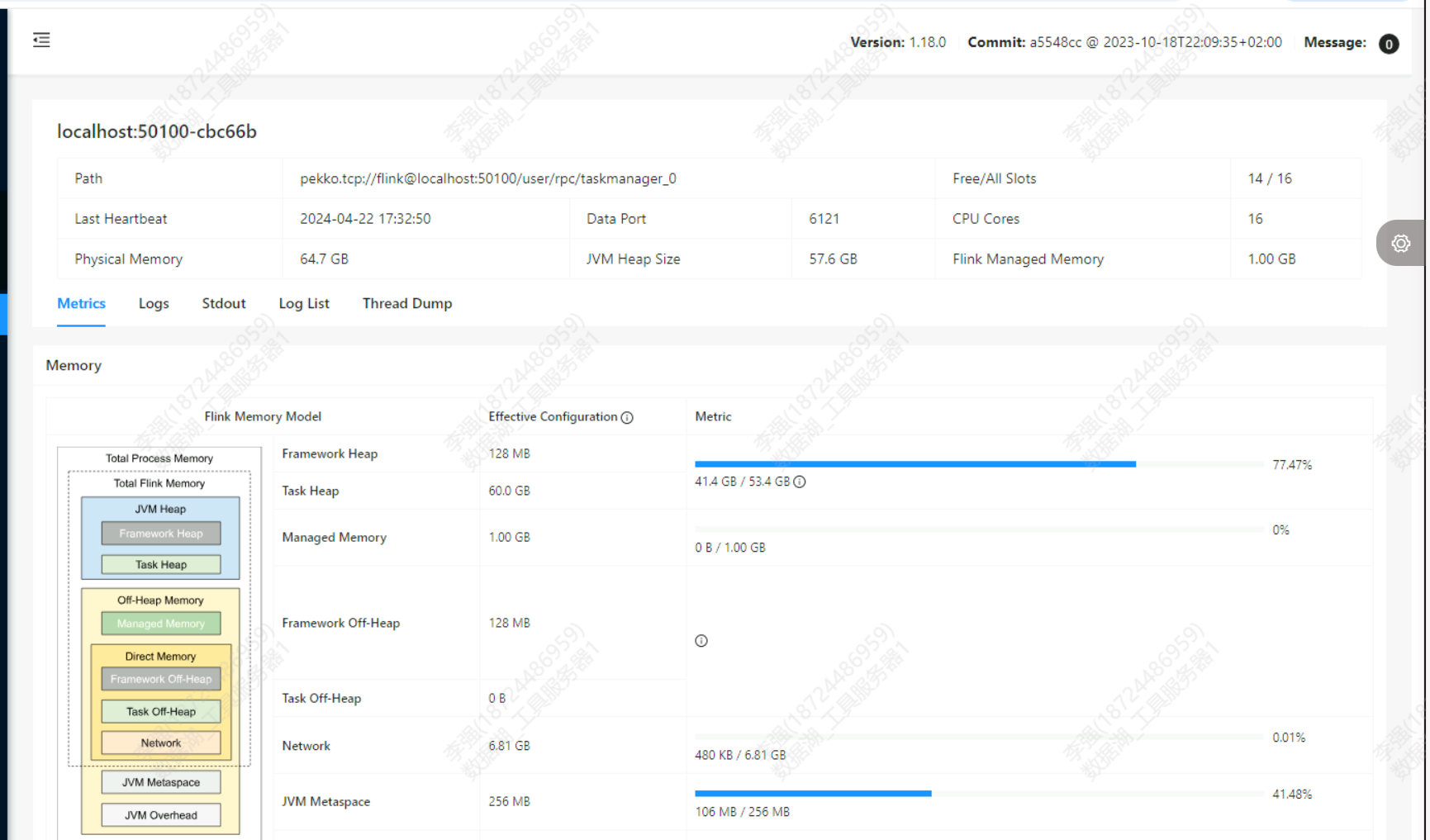 并且taskmanager这里显示内存占比已经很高了请问应该怎么处理一下呢?
并且taskmanager这里显示内存占比已经很高了请问应该怎么处理一下呢?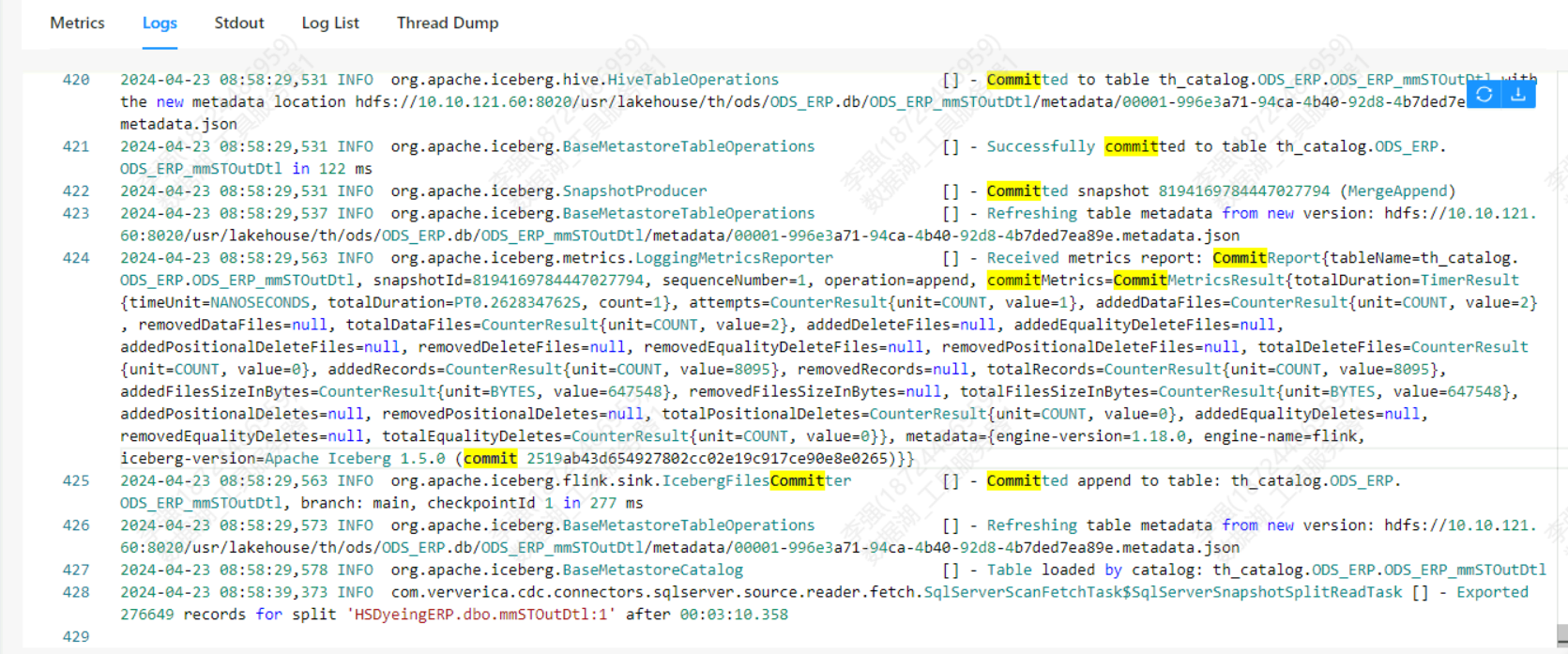
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC 2.4.2 在读取 SQL Server 数据并写入 Iceberg 表时,存在数据读取与写入不一致的情况。日志显示读取了大量数据(276万条),但 Iceberg 表中仅写入了少量数据(8095条)。此外,日志中显示仅有初始阶段有 commit 操作,后续未再提交,并且 TaskManager 内存占用较高。以下是针对该问题的分析和解决方案:
append 和 complete。如果写入模式配置不当,可能导致数据未正确写入。execution.checkpointing.interval=10s
execution.checkpointing.mode=EXACTLY_ONCE
append,以避免覆盖已有数据。示例配置如下:.outputMode("append")
iceberg.commit.manifest.target-size-bytes=8388608 # 8MB
iceberg.commit.manifest.min-count-to-merge=10
taskmanager.memory.process.size=4g
taskmanager.numberOfTaskSlots=4
parallelism.default=4
PARTITIONED BY (date_column)
以下是一个完整的 Flink CDC 读取 SQL Server 并写入 Iceberg 的示例配置:
# Flink 配置
execution.checkpointing.interval=30s
execution.checkpointing.mode=EXACTLY_ONCE
parallelism.default=4
# TaskManager 资源配置
taskmanager.memory.process.size=4g
taskmanager.numberOfTaskSlots=4
# Iceberg 配置
sink-conf.connector=iceberg
sink-conf.catalog-name=dlf_catalog
sink-conf.catalog-database=iceberg_db
sink-conf.io-impl=org.apache.iceberg.aliyun.oss.OSSFileIO
sink-conf.oss.endpoint=<yourOSSEndpoint>
sink-conf.access.key.id=<yourAccessKeyId>
sink-conf.access.key.secret=<yourAccessKeySecret>
sink-conf.warehouse=<yourOSSWarehousePath>
taskmanager.memory.managed.fraction。通过以上步骤,您可以有效解决 Flink CDC 读取 SQL Server 数据并写入 Iceberg 表时的数据不一致问题。如果问题仍未解决,建议进一步分析日志并联系技术支持团队获取帮助。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
