
Flink CDC里这种数据 flinksql 该如何解析?[{"id":"999","name":"abc","date":"1990-10-14"},{"id":"999","name":"abc","date":"1990-10-14"}] kafka里面的。还是一个json数组flink sql
kafka里面的。还是一个json数组flink sql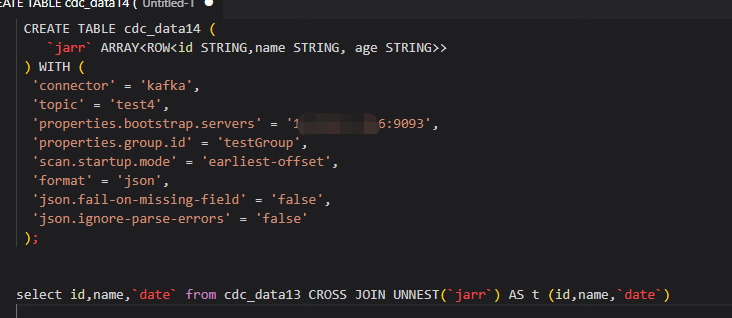
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你直接写字段名字,flink会自动解析的。create table 表名(
id 数据类型,
name 数据类型,
date 数据类型
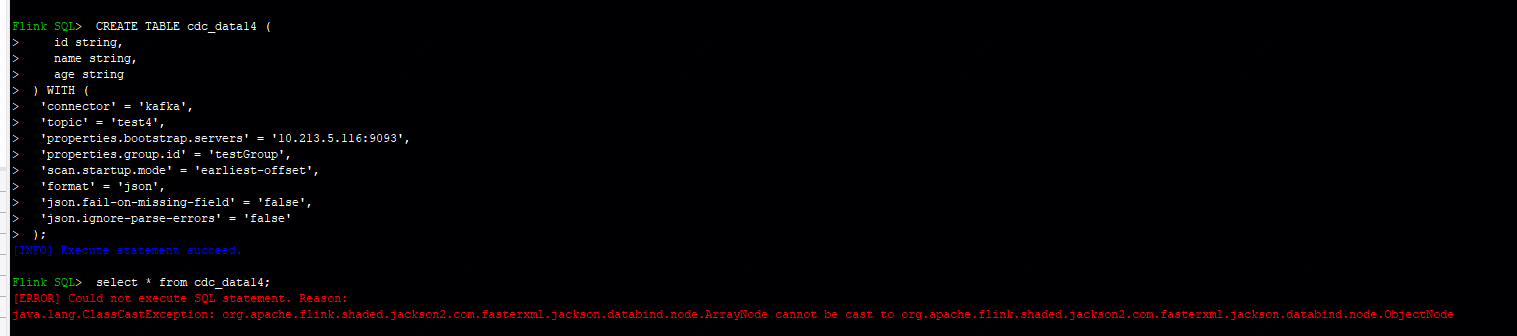
)CREATE TABLE product_view_mysql_kafka_parser(id string,name string,age string
) WITH (
'connector' = 'kafka',
'topic' = test4',
'properties.bootstrap.servers' = '10.213.5.116:9093',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
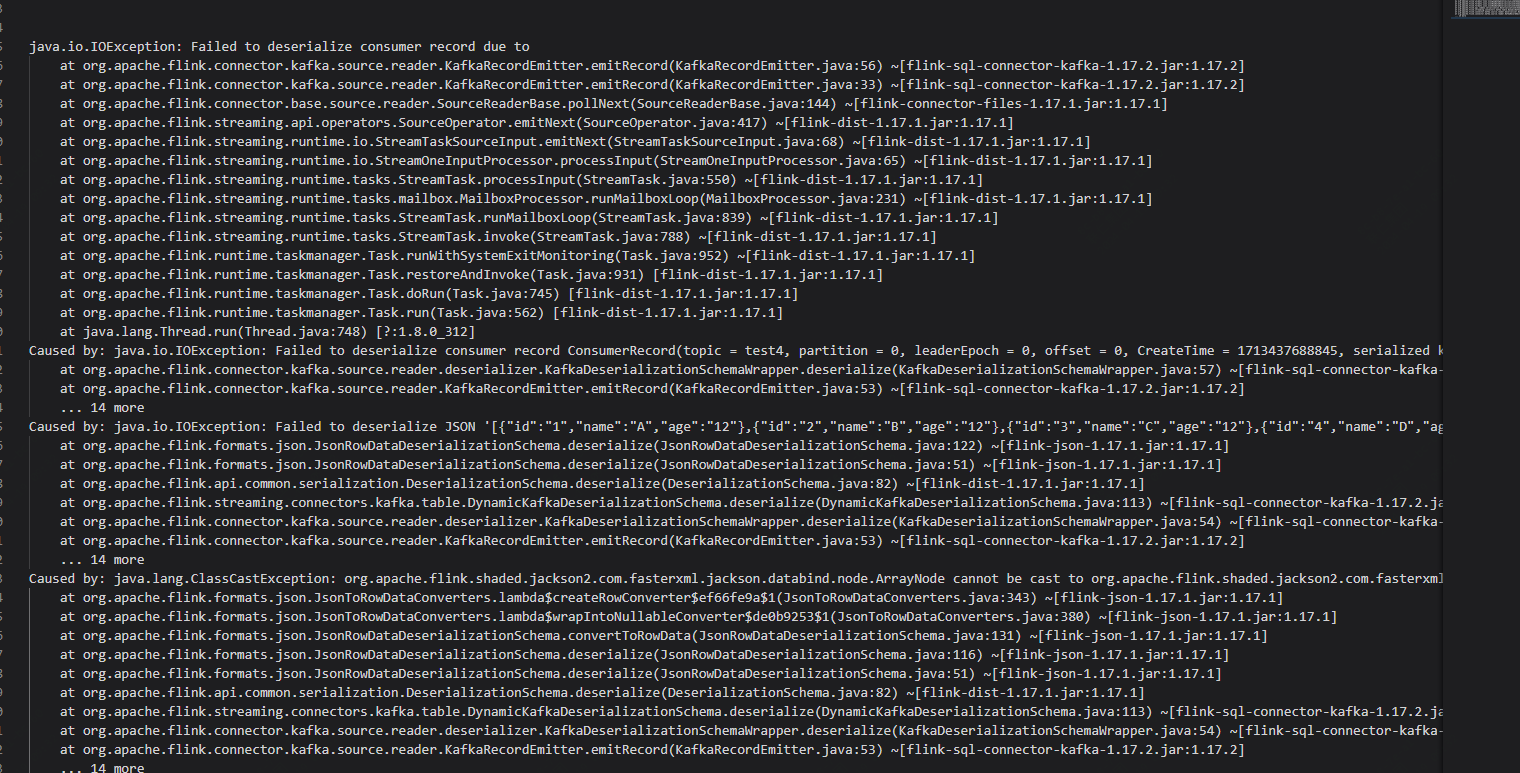
'properties.sasl.kerberos.service.name' = 'kafka'这样试试。 还有一种可能就是解析sql不能直接用select *, select的时候需要对数组进行处理。 SqlServer CDC 连接器首先通过 JDBC 读取表中的历史数据,再从 change tables 中或缺增量变更数据,从而实现全增量同步。好像flink sqlsever cdc这个就可以满足需求。此回答来自钉群Flink CDC 社区。
还有一种可能就是解析sql不能直接用select *, select的时候需要对数组进行处理。 SqlServer CDC 连接器首先通过 JDBC 读取表中的历史数据,再从 change tables 中或缺增量变更数据,从而实现全增量同步。好像flink sqlsever cdc这个就可以满足需求。此回答来自钉群Flink CDC 社区。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
