
请教一下Flink 使用K8s的 HA 选举机制,怎么才能看到根因呢?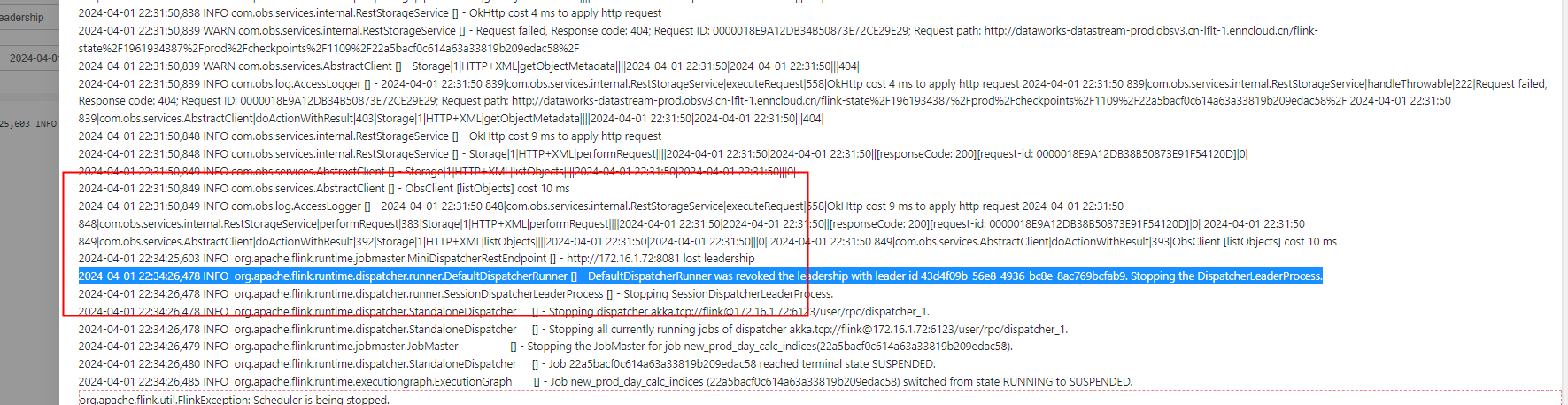
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink结合Kubernetes(K8s)的高可用(HA)选举机制时,如果需要排查根因,可以通过以下步骤和方法进行分析和定位问题。以下是详细的解答:
Kubernetes集群中的事件日志是排查问题的重要来源。通过阿里云容器服务ACK,您可以接入事件中心并查看集群中的所有事件。
通过这些步骤,您可以快速定位Kubernetes层面的问题,例如资源不足或网络异常。
Flink作业的日志中通常会记录HA选举过程中的详细信息,包括选举失败的原因、Leader节点的状态变化等。
org.apache.flink.runtime.leaderretrieval:记录Leader选举的相关信息。org.apache.flink.runtime.jobmaster:记录JobManager的状态变化。org.apache.flink.runtime.resourcemanager:记录ResourceManager的状态变化。Kubernetes资源的状态可能直接影响Flink HA选举的正常运行。例如,虚拟交换机IP不足可能导致Pod无法正常调度。
Has not enough ip address: abnormal event detected from kubernetes。kubectl get pods命令查看Pod的状态。CrashLoopBackOff或Pending状态,进一步检查Pod的描述信息(kubectl describe pod <pod-name>)以获取详细原因。Flink的HA机制依赖于ZooKeeper或Kubernetes的协调服务。如果配置不当,可能导致选举失败。
flink-conf.yaml中的high-availability.zookeeper.quorum配置是否正确。high-availability: kubernetes)。high-availability.cluster-id和kubernetes.namespace配置是否正确。如果Flink作业的数据流复杂,可以利用数据血缘功能追踪数据的来源和流转路径,帮助定位问题的影响面。
如果Flink作业涉及安全连接或认证(例如Kafka的SASL/SSL配置),需要确保相关配置正确无误。
properties.security.protocol、properties.sasl.mechanism和properties.sasl.jaas.config等参数配置正确。通过以上步骤,您可以从多个维度分析Flink使用K8s HA选举机制时的根因。建议按照以下优先级进行排查: 1. Kubernetes事件日志:快速定位集群层面的问题。 2. Flink作业日志:深入分析HA选举的具体异常。 3. 资源状态检查:确保Kubernetes资源充足且状态正常。 4. HA配置验证:确认ZooKeeper或Kubernetes的HA配置无误。 5. 数据血缘分析:辅助定位复杂数据流中的问题。
如果问题仍未解决,建议联系阿里云技术支持团队,提供详细的日志和配置信息以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

